Webpage content extraction method and system based on heuristic rule
A web content and heuristic technology, applied in the direction of website content management, network data retrieval, character and pattern recognition, etc., can solve the problems of spending a lot of time maintaining and debugging code, low efficiency, etc., to save labor costs, universal strong effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

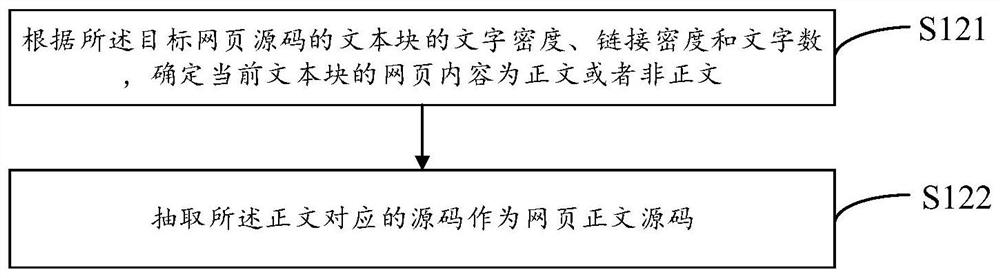
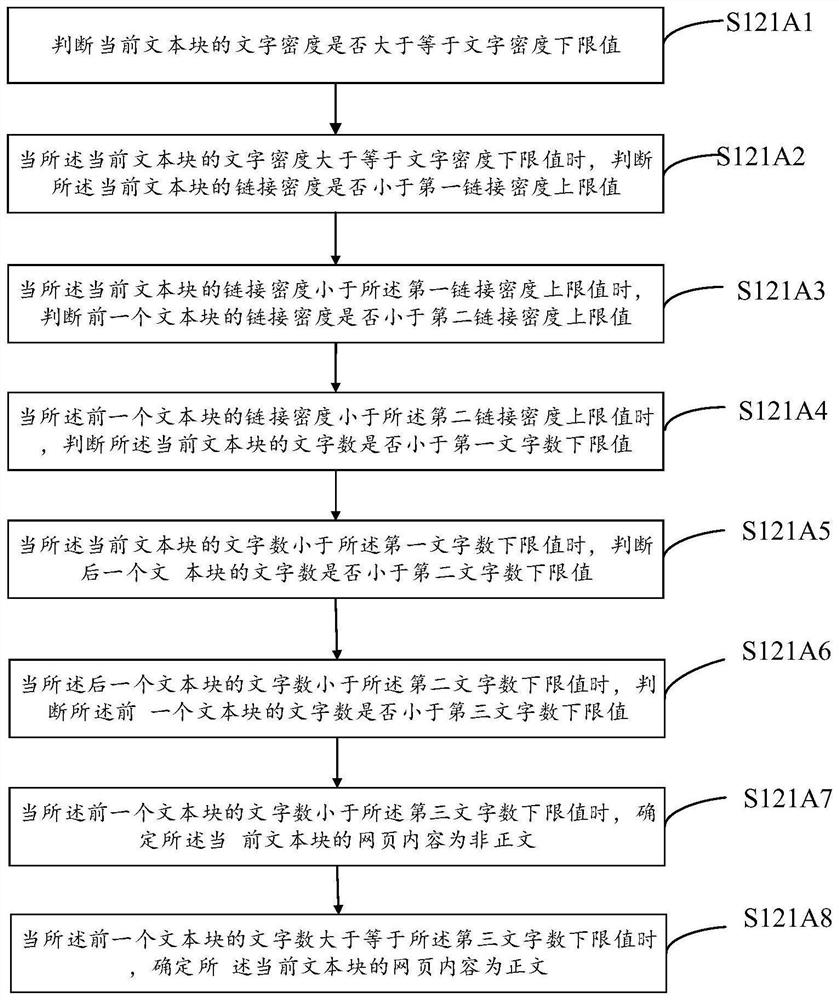
Examples
Embodiment 1
[0055] refer to figure 1 , shows a flow chart of the steps of the method for extracting web page content based on heuristic rules according to Embodiment 1 of the present invention. It can be understood that the flowchart in this method embodiment is not used to limit the sequence of execution steps. An exemplary description is given below taking the computer device 2 as the execution subject. details as follows.
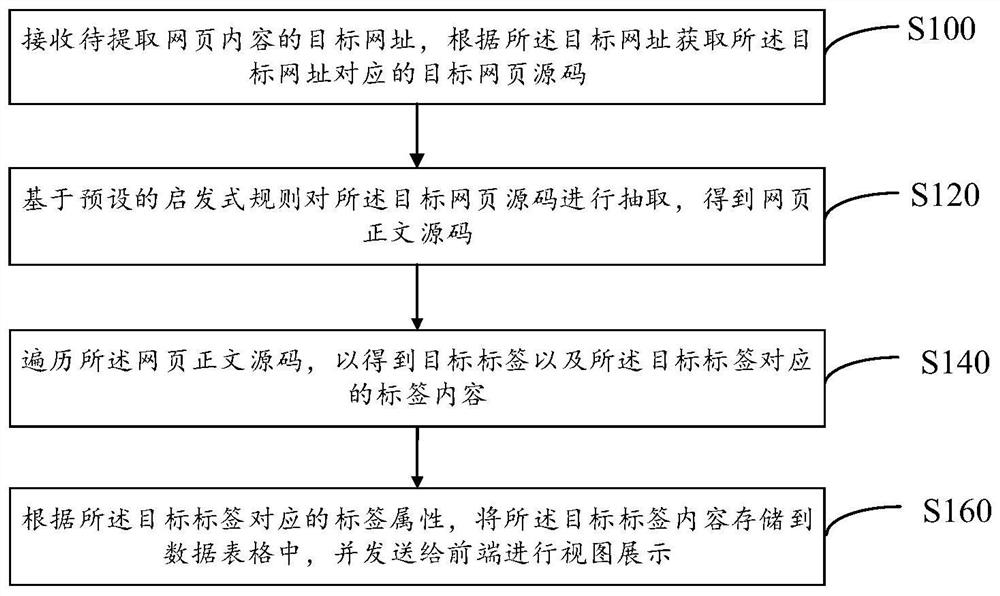
[0056] Step S100, receiving a target URL of webpage content to be extracted, and obtaining a target webpage source code corresponding to the target URL according to the target URL.
[0057] Specifically, the user opens the input page, and inputs a target URL in a corresponding input box to open the target webpage, or directly opens a target webpage in the browser homepage. After receiving the request extraction instruction for opening the target webpage, obtain the source code corresponding to the target webpage, that is, the source code of the target webpage.
...
Embodiment 2
[0113] read on Figure 7 , shows a schematic diagram of program modules of Embodiment 2 of the system for extracting web page content based on heuristic rules of the present invention. In this embodiment, the web page content extraction system 20 based on heuristic rules may include or be divided into one or more program modules, one or more program modules are stored in a storage medium, and processed by one or more implemented by a device to complete the present invention and realize the above method for extracting webpage content based on heuristic rules. The program module referred to in the embodiment of the present invention refers to a series of computer program instruction segments capable of completing specific functions, which is more suitable than the program itself to describe the execution process of the heuristic rule-based web page content extraction system 20 in the storage medium. The following description will specifically introduce the functions of each ...
Embodiment 3
[0135] refer to Figure 8 , is a schematic diagram of the hardware architecture of the computer device according to Embodiment 3 of the present invention. In this embodiment, the computer device 2 is a device capable of automatically performing numerical calculation and / or information processing according to preset or stored instructions. The computer device 2 may be a rack server, a blade server, a tower server or a cabinet server (including an independent server, or a server cluster composed of multiple servers) and the like. Such as Figure 8 As shown, the computer device 2 at least includes, but is not limited to, a memory 21 , a processor 22 , a network interface 23 , and a web content extraction system 20 based on heuristic rules that can communicate with each other through a system bus. in:
[0136] In this embodiment, the memory 21 includes at least one type of computer-readable storage medium, and the readable storage medium includes flash memory, hard disk, ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com