

Patient identity matching method based on PSO algorithm optimization
A matching method and patient technology, applied in the field of medical information, can solve the problems of large amount of calculation of sample data, non-optimal similarity weight coefficient, etc., to achieve the effect of reducing labor costs, improving data processing efficiency, and reducing workload
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
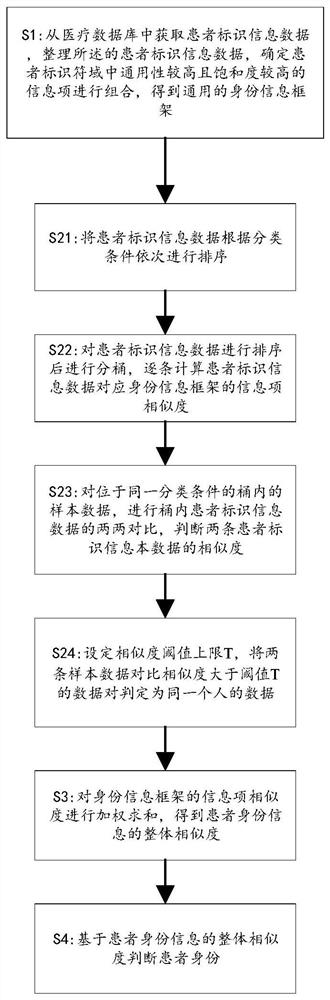
[0055] In the medical information system, patient identification information generally includes: name, gender, ethnicity, date of birth, ID number, contact number, address, medical insurance card number, and medical card number. Obtain the user information data uploaded by the server of the hospital information system; wherein, the user information data includes at least name, gender, ethnicity, date of birth, ID number, contact number, address, medical insurance card number, and medical card number; according to the preset The first field value extraction strategy obtains the corresponding current first field value in the user information data, and uses the current first field value as a retrieval condition to obtain the corresponding data set after primary screening; wherein, the data set after primary screening includes Several pieces of data after initial screening, each of which includes at least name, gender, date of birth, certificate type, certificate number, contact nu...
Embodiment 2
[0085] The matching degree of patient identity information can be reflected by the weighted sum of the matching degrees of each field information. The formula is a weighted expression:
[0086]
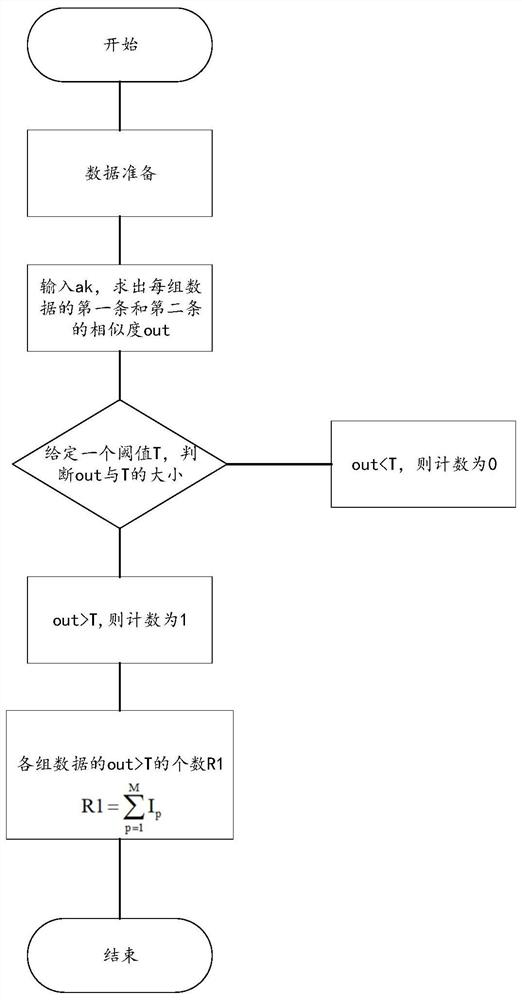
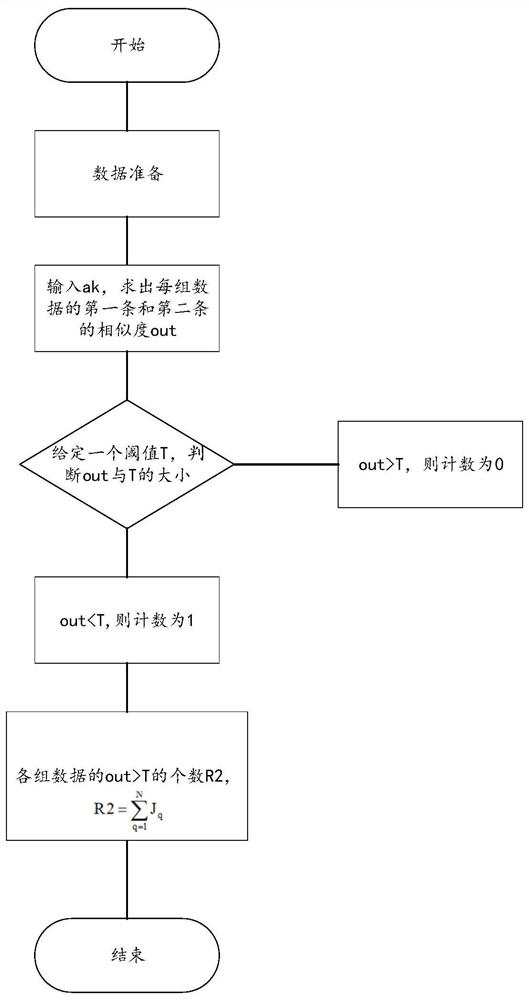
[0087] where Sim(X i , Y j ) refers to the similarity between the i-th record in patient identity source X and the j-th record in patient identity source Y; Sim(X ik , Y jk ) refers to X i record with Y j The similarity of the kth information item recorded, a k Refers to the weight given to the kth information item, which must satisfy 0k <1.
[0088] The degree of similarity between strings can usually be reflected by similarity measurement, distance measurement, edit distance (Edit Distance) and longest common subsequence (LCS, Longest Common Subsequence). The edit distance includes: Euclidean distance, Manhattan distance, etc.
[0089]
[0090] Table 1 Positive sample data pairs
[0091]
[0092] Table 2 Negative sample data pairs
[0093] This algorithm uses the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More