

Big data block iteration high-speed processing method, FPGA device and system
A large data block, high-speed processing technology, applied in the computer field, can solve problems affecting FPGA processing efficiency, occupying system resources, and limited RAM resources, so as to improve overall efficiency, release system resources, and meet computing needs.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 2
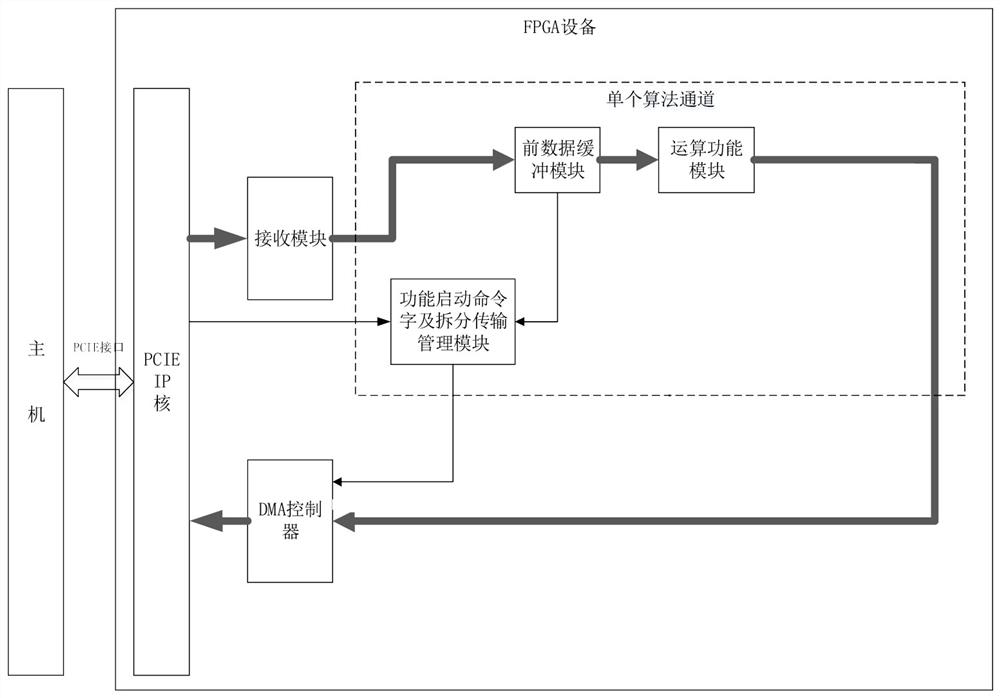
[0043] The difference between this embodiment and Embodiment 1 is that: in this polling process, the algorithm channel that is determined not to read data this time is executed in the first order to generate the first sorting process; The algorithm channel that reads and whose read length is the threshold value of the single-segment data transmission executes the second sorting process in order to generate the second sorting; reads the data determined this time and the read length is the length of the remaining source data The algorithm channel executes the third sorting process in sequence to generate the third sorting; after this round of polling, the next polling is performed in the order of the first sorting, the second sorting, and the third sorting.
[0044] The above method enables the DMA controller to dynamically adjust the order of the next round of polling according to the computing power of different algorithm channels and the actual transmission situation, so that ...
Embodiment 3
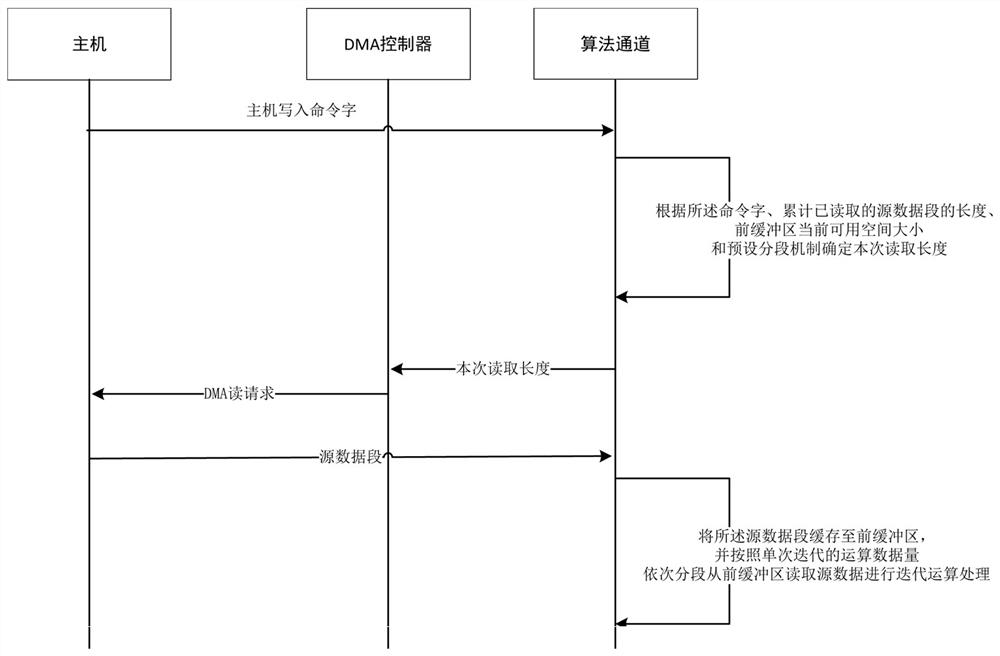
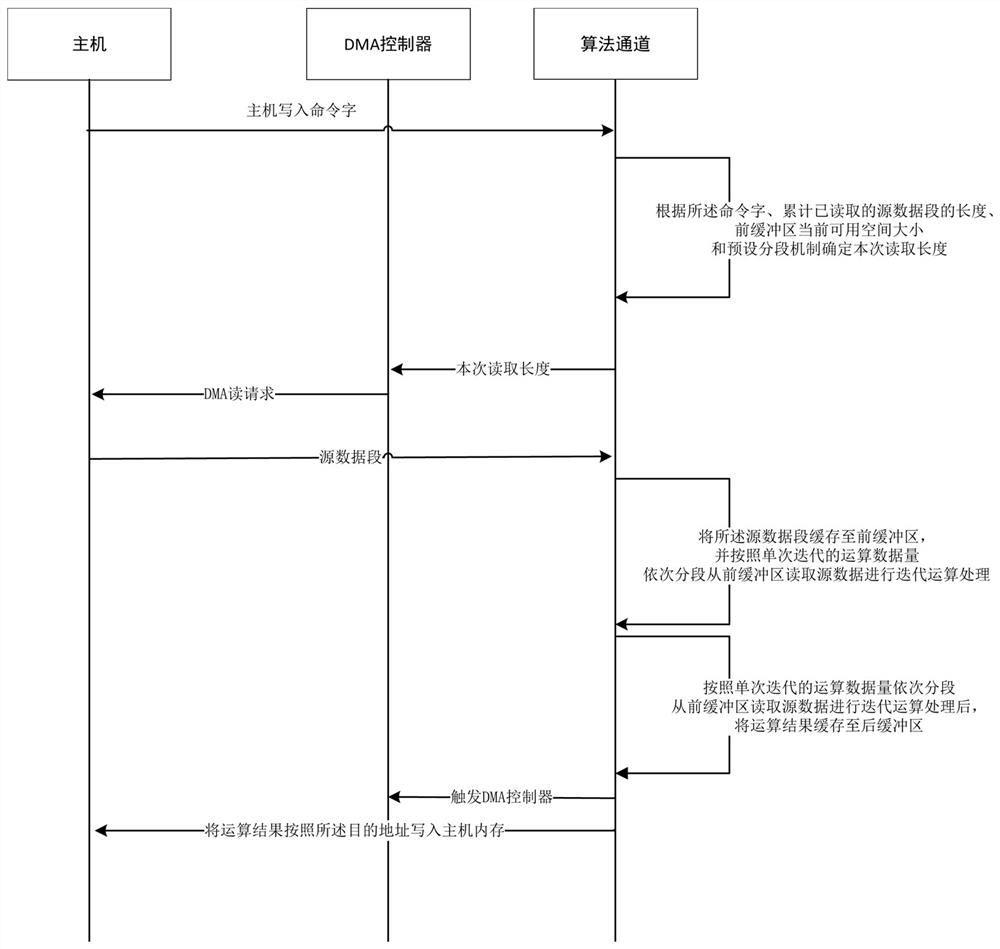
[0046] The difference between this embodiment and embodiment 2 is: as figure 2 As shown, according to the amount of operation data in a single iteration, the source data is read from the front buffer in sections for iterative operation processing, and the operation results are cached in the back buffer; the current available space in the back buffer is not 0 and all When the iterative operation of the source data is completed, the length of the operation result in the back buffer is extracted, and the DMA controller is triggered based on the length of the operation result in the back buffer to write the operation result into the host memory according to the destination address.
[0047] It can be understood that when the source data block is small, the calculation result corresponding to the algorithm channel is also small, so that the calculation result can be written into the host memory at one time.
Embodiment 4
[0049] The difference between this embodiment and embodiment 2 is: as figure 2 As shown, according to the amount of operation data in a single iteration, the source data is read in segments from the front buffer for iterative operation processing, and the operation result is cached in the back buffer; when the current available space of the back buffer is 0, based on The space size of the back buffer triggers the DMA controller to write the operation result into the host memory according to the destination address.
[0050] It can be understood that when the source data block is too large, the calculation result corresponding to the algorithm channel is also too large, so that the calculation result cannot be written into the host memory at one time, and segment writing is required at this time.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More