

Cross-cluster data processing system and method based on HQL
A data processing system and cross-cluster technology, applied in the field of big data processing, can solve the problems of rapid analysis of data by unfavorable data warehouse analysts, increase data maintenance costs, laborious and laborious, etc., and achieve easy promotion, no learning cost, and reduced maintenance cost effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
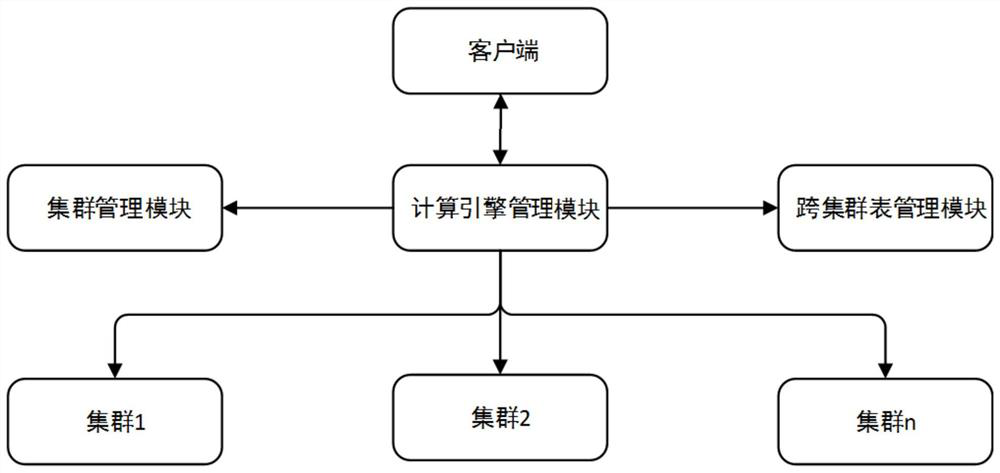
[0048] like figure 1 As shown in a cross-cluster HQL based data processing system of the present invention, the system includes a client, calculation engine management module, the cluster management modules, across the cluster table management module;
[0049] The client, for HQL query statement to be sent to the compute engine management module, while the data reception result of the compute engine query management module;
[0050] The compute engine management module, using Hive sent by the client engine parses the HQL statement, analyzed in HQL table used, and the table belongs to the cluster (cluster may be present, may present a non-clustered), to achieve this cluster or across a cluster computing; while the grammar checker module supports cross-cluster of HQL;
[0051] The cluster management module for acquiring computing resources in real time, all clusters (cpu cores and memory size) and storage resources (HDFS storage space usage), and apply certain rules to calculate the...
Embodiment 2
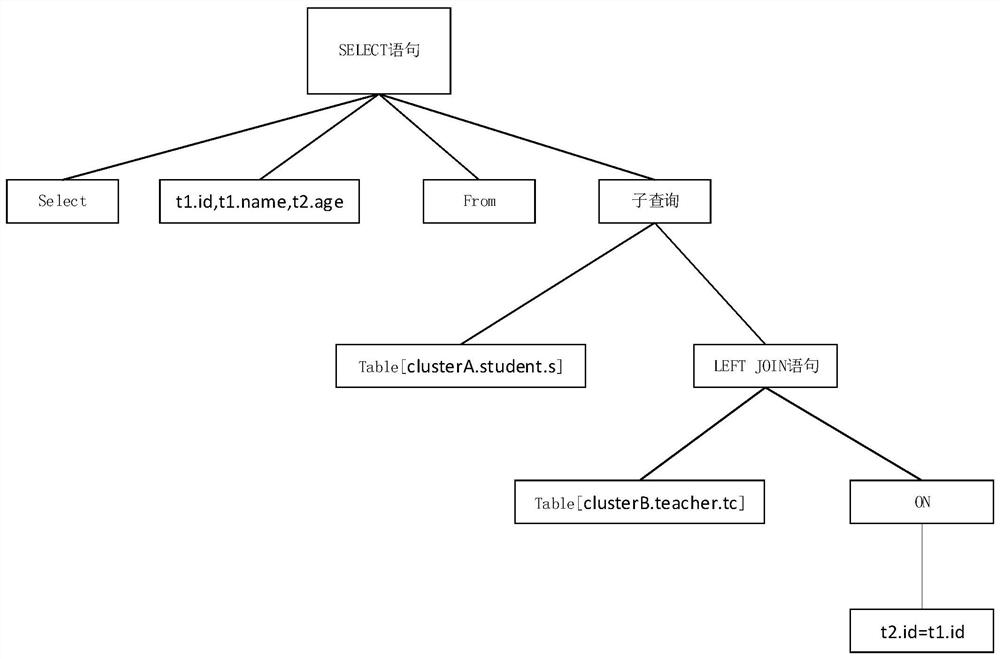
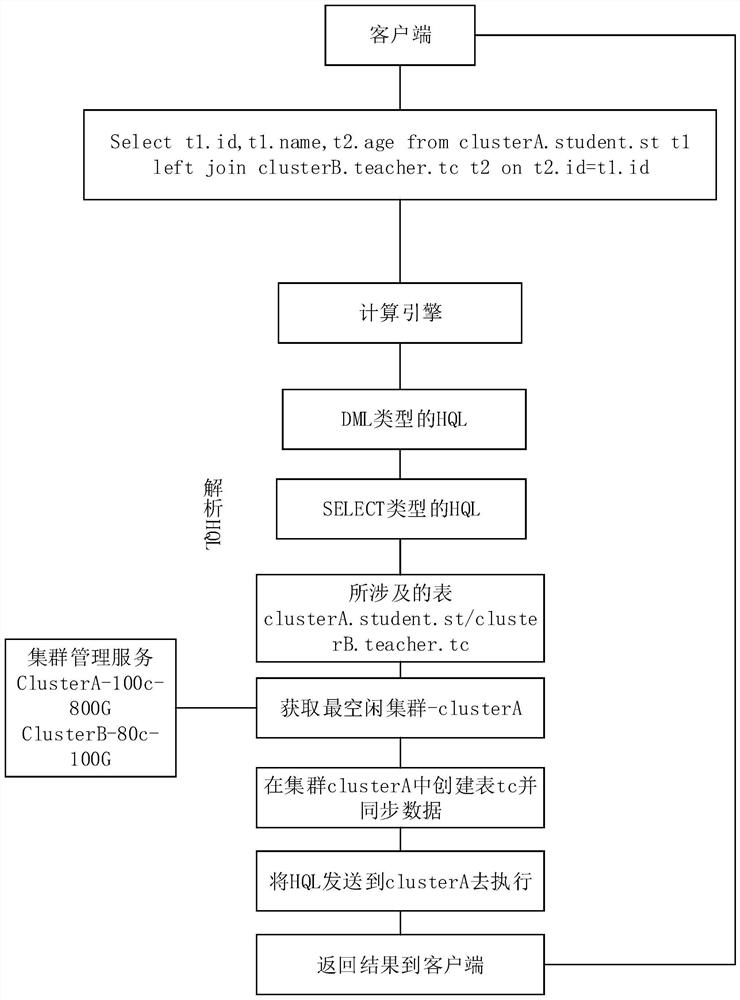
[0078] like figure 2 , image 3 As shown, the difference from the first embodiment is that the embodiment provides an HQL-based span data processing method, which is applied to an HQL-based hurdle data processing system according to Embodiment 1. This method includes:
[0079] S0: Using the ANTLR4 Technical Framework Analysis of the syntax of the HQL statement sent by the client correctly, if the syntax of the HQL statement is correct, perform the type of the HQL statement; if the syntax error of the HQL statement is returned to the client ;
[0080] S1: Use the Hive Engine to resolve the type of HQL statement to be queried by the client, the type of HQL statement includes DML type, DDL type;
[0081] S2: If the parsed HQL statement is the DDL type, continue to resolve the corresponding cluster of the HQL statement, while sending the HQL statement to the corresponding set of groups;
[0082] S3: If the parsed HQL statement is the DML type, continue to resolve the HQL statement for ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More