

Video description method based on target space semantic alignment
A video description and target technology, applied in the field of computer vision, can solve the problems of high time and space complexity of the attention mechanism, ignoring the corresponding relationship, difficult real-time performance, etc., and achieve the goal of improving operating efficiency, improving accuracy, and increasing accuracy Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
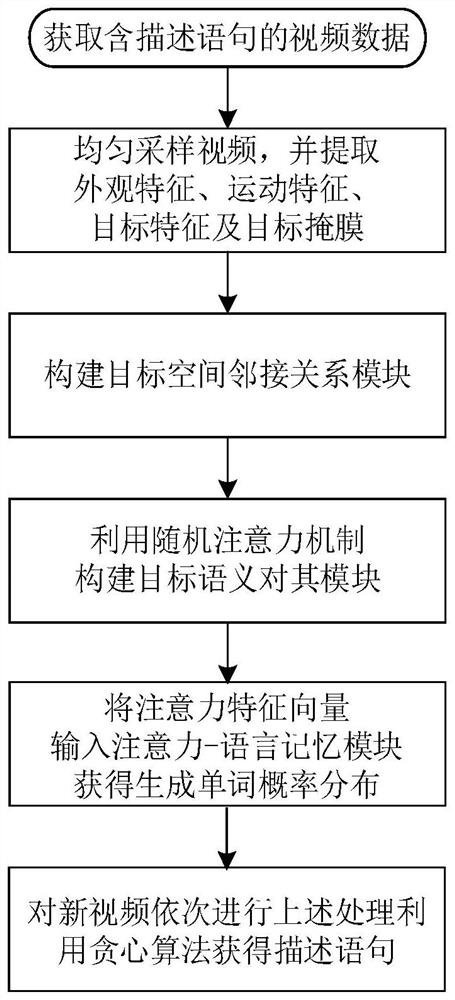
[0062] The present invention will be further described below in conjunction with accompanying drawing.
[0063] Such as figure 1 , a video description method based on target space semantic alignment, first uniformly sample the video, extract its video feature vector, target feature vector and mask set; then input the video mask set into the target space adjacency module, which can Obtain the target adjacency matrix; use the target adjacency matrix and the target feature vector to jointly construct the target adjacency feature, and use the word selection module to obtain the word candidate set; input the target adjacency feature vector, video feature vector and candidate word set into the target semantics The alignment module realizes semantic alignment; after obtaining the semantic alignment vector, input it into the attention-language memory module to realize the generation of the final sentence. This method can not only capture the object spatial relationship, but also achi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More