

Large-scale MIMO dynamic environment fingerprint positioning method based on domain adaptive network
A domain-adaptive and dynamic environment technology, applied in specific environment-based services, biological neural network models, location-based services, etc., can solve problems such as high cost of location fingerprint database, failure of location fingerprint database, failure to meet positioning requirements, etc. , to achieve the effects of alleviating fuzzy classification and reducing matching results, good effect and easy implementation
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

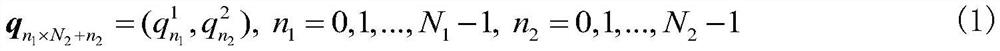
Examples
Embodiment Construction
[0069] In order to make those skilled in the art better understand the present invention, the implementation process of the technical solution is further described in detail below with reference to the accompanying drawings.
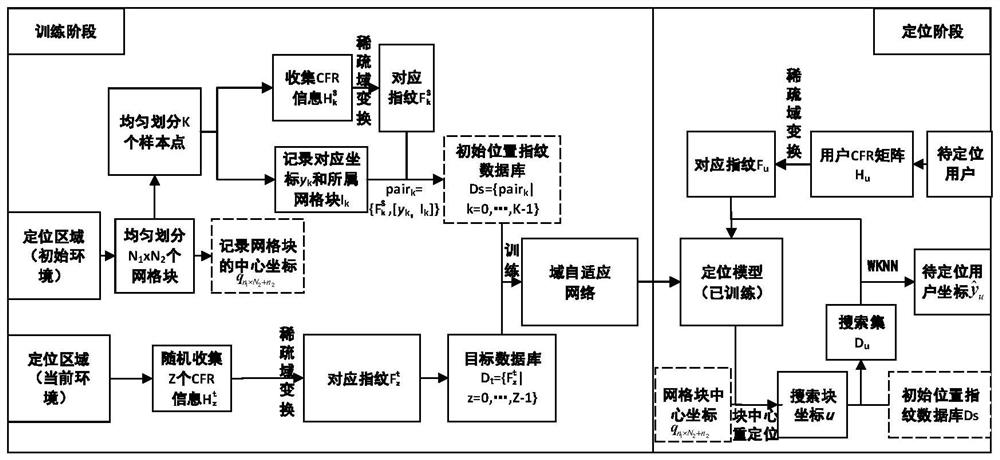
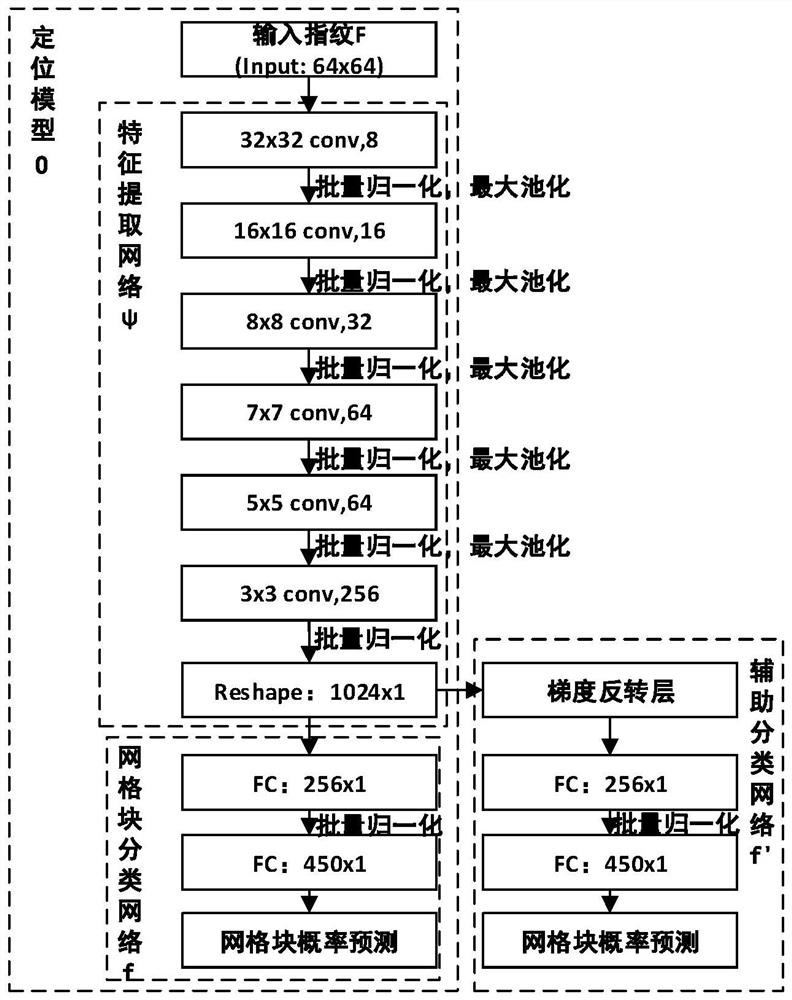
[0070] like figure 1 As shown, the large-scale MIMO (multiple input multiple output) dynamic environment fingerprint positioning method based on the domain adaptive network disclosed in the embodiment of the present invention mainly includes two parts: a training phase and a positioning phase.
[0071] Training phase: Divide the two-dimensional positioning area into uniform N block =N 1 ×N 2 grid blocks and numbered, N 1 ,N 2 are the total number of rows and columns for dividing grid blocks, and record the center coordinates of each grid block in corresponds to the nth 1 line n 2 The horizontal and vertical coordinates of the center position of the column grid block. In the initial environment, K sample points are divided at equal intervals, a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More