

Data missing processing method and system based on maximizing set partition information
A set division, data missing technology, applied in the direction of digital data processing, special data processing applications, patient-specific data, etc., can solve the problems of masking the original data rules, large amount of calculation, etc., to improve efficiency, reduce the amount of calculation, avoid The effect of data errors
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

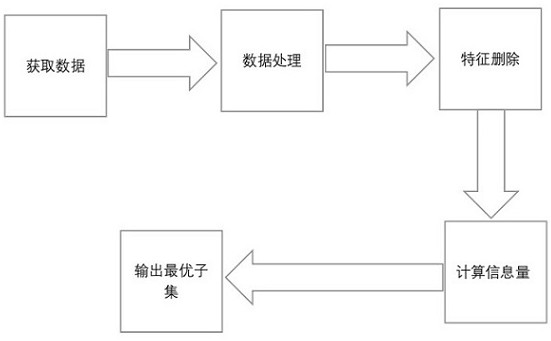
Examples
Embodiment 1
[0046] A data missing processing method based on maximizing the amount of set partition information, obtain patient data, the patient data contains N patient samples, each patient contains F features, there are missing values in the obtained data, and the acquired N The F characteristic data of the patient are saved in the form of matrix S,
[0047] Transform the matrix S to obtain the matrix T, and the mapping relationship of transforming the matrix S into the matrix T is: if S i,j Existence of acquired data, will define T i,j =C, C is a constant, if S i,j In the absence of acquired data, T i,j =a i / F×C, where a i For the number of non-missing data in the i-th sample data, calculate the sum of each column of the matrix T to get Sum 1 ,Sum 2 ,…,Sum F ,
[0048] where i=1,...,N,
[0049] j=1,...,F,
[0050] And i, j, N and F are all positive integers,
[0051] According to the sum of each column of the matrix T from small to large, the feature data under the colum...
Embodiment 2
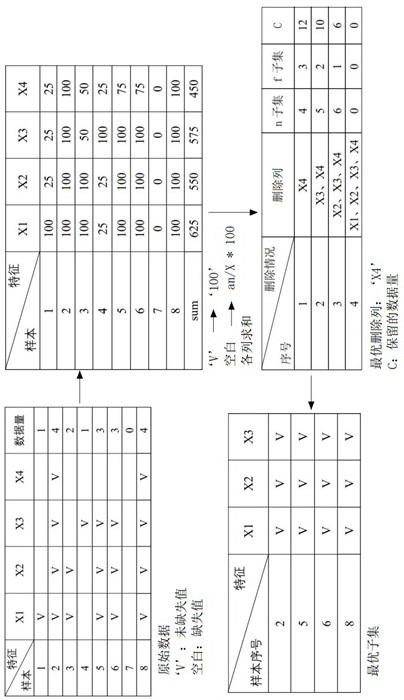
[0060] For a missing data set, where the number of samples = N and the number of features = F, different methods of deleting missing data can be used to obtain subsets with complete data containing different amounts of data, and the subset containing the largest amount of data can be selected. Set as the optimal subset for subsequent data analysis. Taking Table 1 as an example, V represents the observed value, and the blank is the missing value.
[0061]
[0062] Table 1 Raw data
[0063] For example, if you delete the fourth column and delete the corresponding row with missing data, you can get a subset containing samples 2, 5, 6, 8, and features 1, 2, and 3; similarly, delete the third column to get a subset containing samples 2, 8, a subset of features 1, 2, 4; delete the 3rd and 4th columns, you can get a subset containing samples 2, 3, 5, 6, 8, features 1, 2... But with the feature As the number increases, the number of deletion methods also increases. In this exampl...
Embodiment 3
[0076] Take the extreme data of table 6 as an example to analyze the method of the present invention, the data of the 6th characteristic of this data are missing data,
[0077]
[0078] The raw data of table 6 embodiment 3
[0079] The data set has 10 samples and 6 features, and the missing conditions of each column are different. It is assumed that the number of features observed in each sample is a n , replace all V in the data set with 100, and replace the missing data of each sample with m n =a n / F 100, for sample 1, m n =100 / 3, and so on, the observed variables and missing data in the data set are replaced accordingly, and the values of each column are summed, so Table 7 can be obtained,
[0080]
[0081] Table 7 The intermediate data after conversion of embodiment 3
[0082] Here, for the convenience of calculation, m n Rounding off is performed in the calculation. The obtained sum can reflect the data retention of each sample on the feature. The lar...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More