Road network difference method and device, electronic equipment and storage medium
A differential method and differential technology, applied in the field of electronic maps, can solve the problems of erroneous differential results, affecting matching differential, poor accuracy of differential results, etc., to achieve the effect of improving generalization and accuracy.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

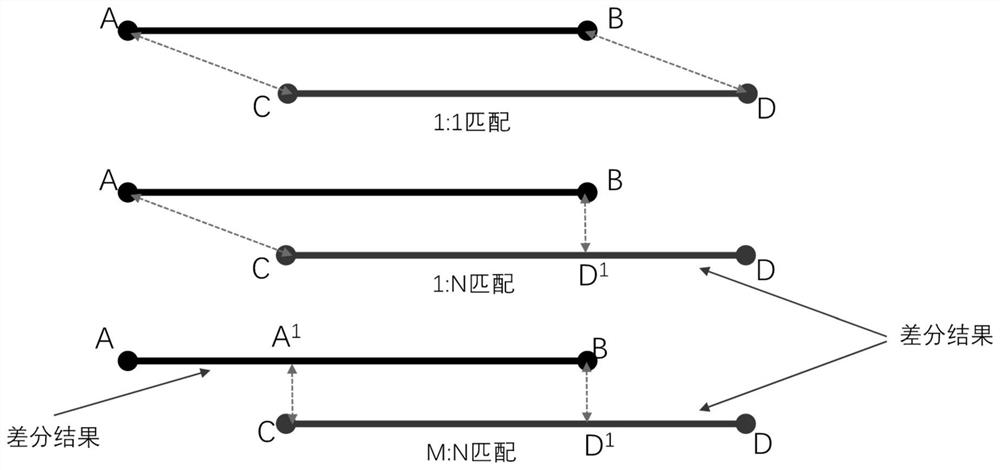
Examples
Embodiment 1
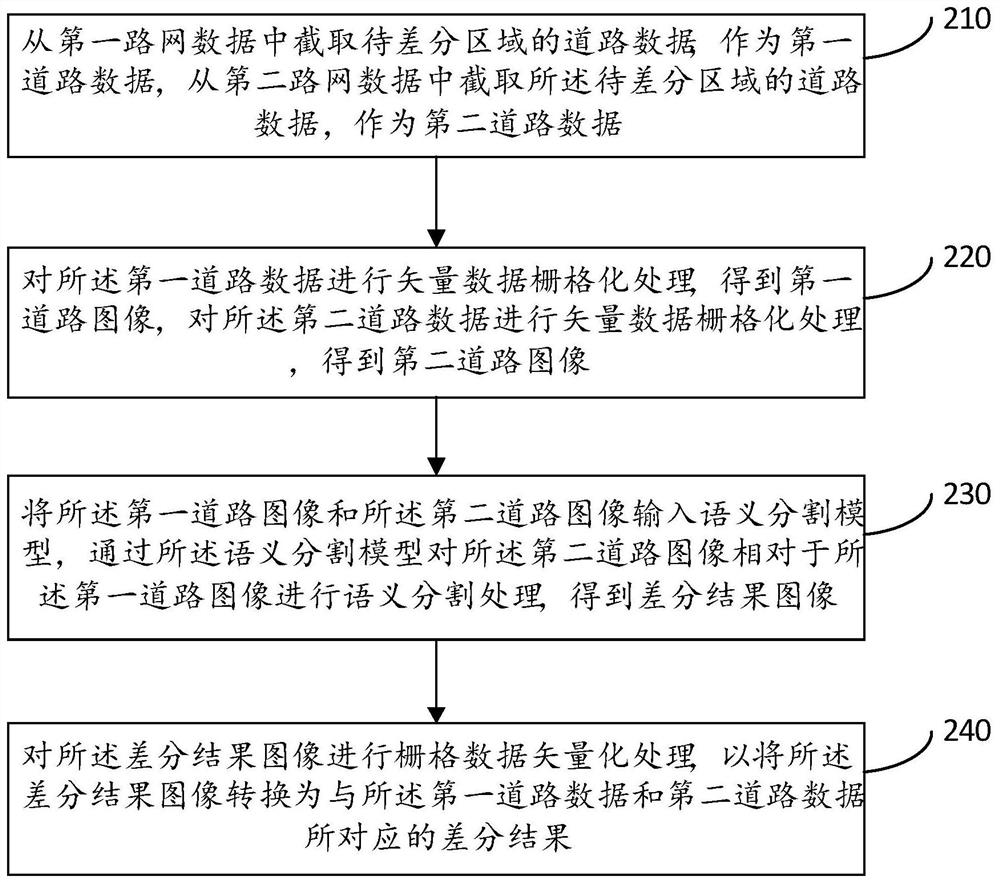
[0029] A road network difference method provided in this embodiment, such as figure 2 As shown, the method includes: Step 210 to Step 240.
[0030] Step 210, intercepting the road data of the area to be differentiated from the first road network data as the first road data, and intercepting the road data of the area to be differentiated from the second road network data as the second road data.
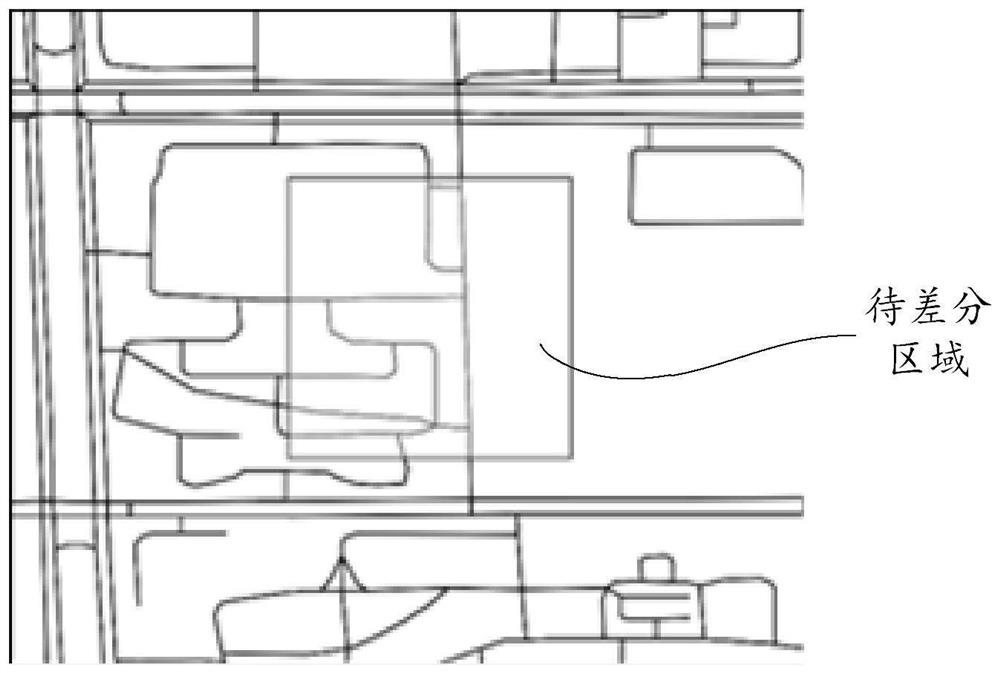
[0031] Wherein, the first road network data and the second road network data may be two copies of road network data from different sources, or may be road network data from the same source but in different versions. Both the first road network data and the second road network data are vector data. The area to be differentiated is a predetermined actual geographical area where road network differentiation is currently performed, and can be represented by latitude and longitude coordinates.
[0032] After the area to be differentiated is determined, according to the latitude and long...
Embodiment 2
[0072] A road network differential device provided in this embodiment, such as Figure 6 As shown, the road network difference device 600 includes:
[0073] The road data intercepting module 610 is used to intercept the road data of the area to be differentiated from the first road network data as the first road data, and intercept the road data of the area to be differentiated from the second road network data as the second road data;
[0074] The rasterization processing module 620 is configured to perform vector data rasterization processing on the first road data to obtain a first road image, and perform vector data rasterization processing on the second road data to obtain a second road image ;
[0075] A semantic segmentation module 630, configured to input the first road image and the second road image into a semantic segmentation model, and use the semantic segmentation model to perform semantic segmentation on the second road image relative to the first road image ...
Embodiment 3
[0106] The embodiment of the present application also provides an electronic device, such as Figure 7 As shown, the electronic device 700 may include one or more processors 710 and one or more memories 720 connected to the processors 710 . The electronic device 700 may also include an input interface 730 and an output interface 740 for communicating with another device or system. Program codes executed by the processor 710 may be stored in the memory 720 .
[0107] The processor 710 in the electronic device 700 invokes the program code stored in the memory 720 to execute the road network difference method in the above embodiment.
[0108] The aforementioned components in the aforementioned electronic device may be connected to each other via a bus, such as one of a data bus, an address bus, a control bus, an expansion bus, and a local bus, or any combination thereof.
[0109] The embodiment of the present application also provides a computer-readable storage medium, on whic...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com