Distributed data-driven process modeling optimization method and system
A technology of distributed data and optimization methods, applied in data processing applications, neural learning methods, computing models, etc., to achieve the effect of saving manpower
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0082] In order to make the objectives, technical solutions and advantages of the present invention clearer, the present invention will be further described in detail below with reference to the accompanying drawings and embodiments. It should be understood that the specific embodiments described herein are only used to explain the invention, but not to limit the invention.
[0083] Federated machine learning is also known as federated learning, federated learning, and federated learning. Federated Machine Learning is a machine learning framework that can effectively help multiple agencies conduct data usage and machine learning modeling while meeting user privacy protection, data security, and government regulations. Federated learning, as a privacy-preserving distributed machine learning framework, protects user privacy by sharing update directions instead of private data, and has broad application prospects.
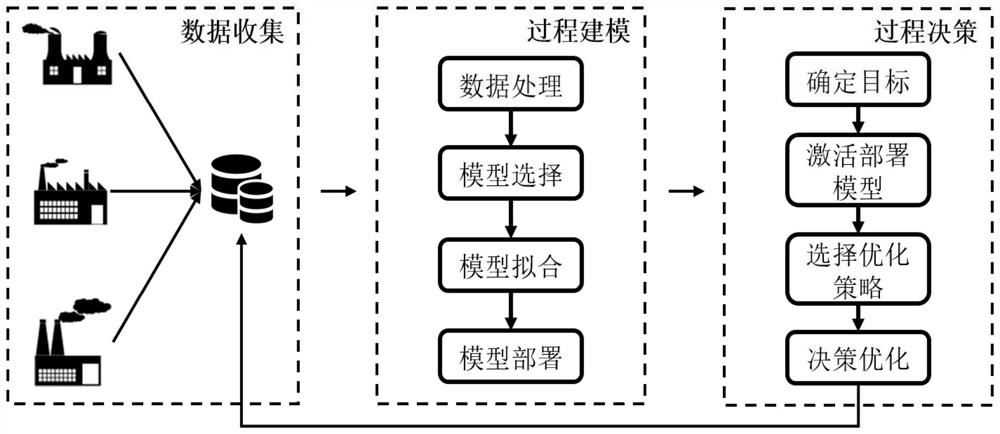
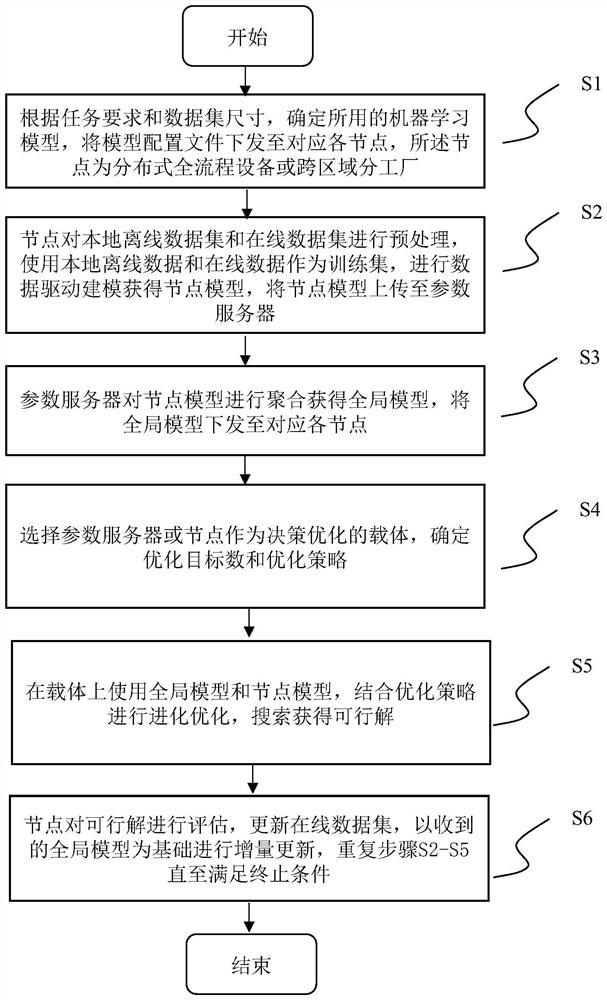
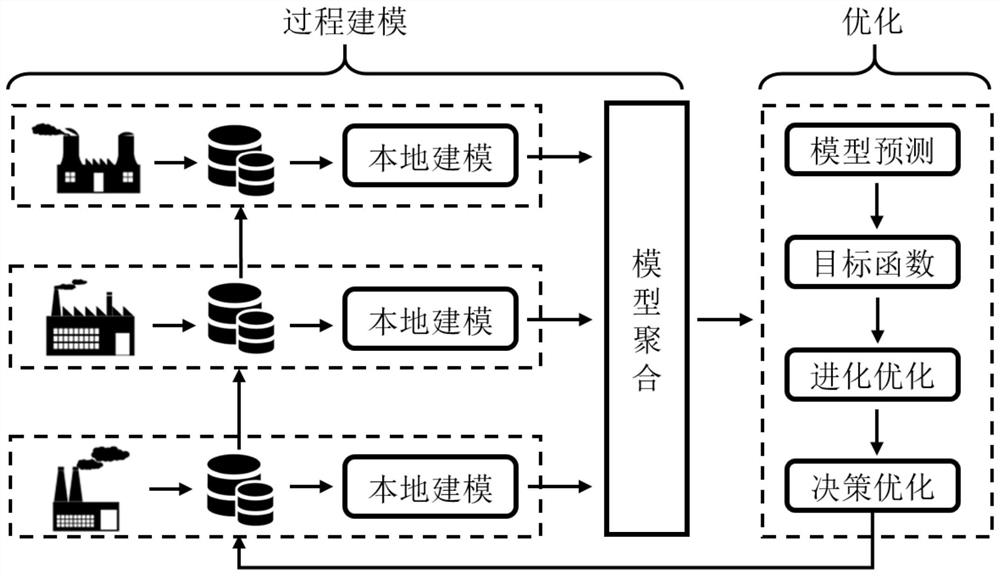
[0084] The invention proposes a distributed data-driven process...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More