

Automatic sound identifying treating method for embedded sound identifying system
An automatic speech recognition and speech recognition technology, applied in speech recognition, speech analysis, sound input/output, etc., can solve the problems of not considering the distinguishing performance of speech command templates, the rejection of non-command words is too simple, and the performance needs to be further improved. , to achieve the effect of strong representation, high recognition rate and low cost
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0019] Embodiments of the present invention are described in detail in conjunction with each figure as follows:
[0020] The structure of the embedded speech recognition core is as follows: Figure 4 As shown, it includes DSP unit for calculation and control; FlashROM for storing programs and voice recognition templates; A / D converter and microphone for voice input, and programmable logic device CPLD for decoding and output control . Description: MIC: microphone, A / D: analog-to-digital converter, DSP: digital signal processor, RAM: random access memory, FlashROM: flash memory, CPLD: programmable logic device.
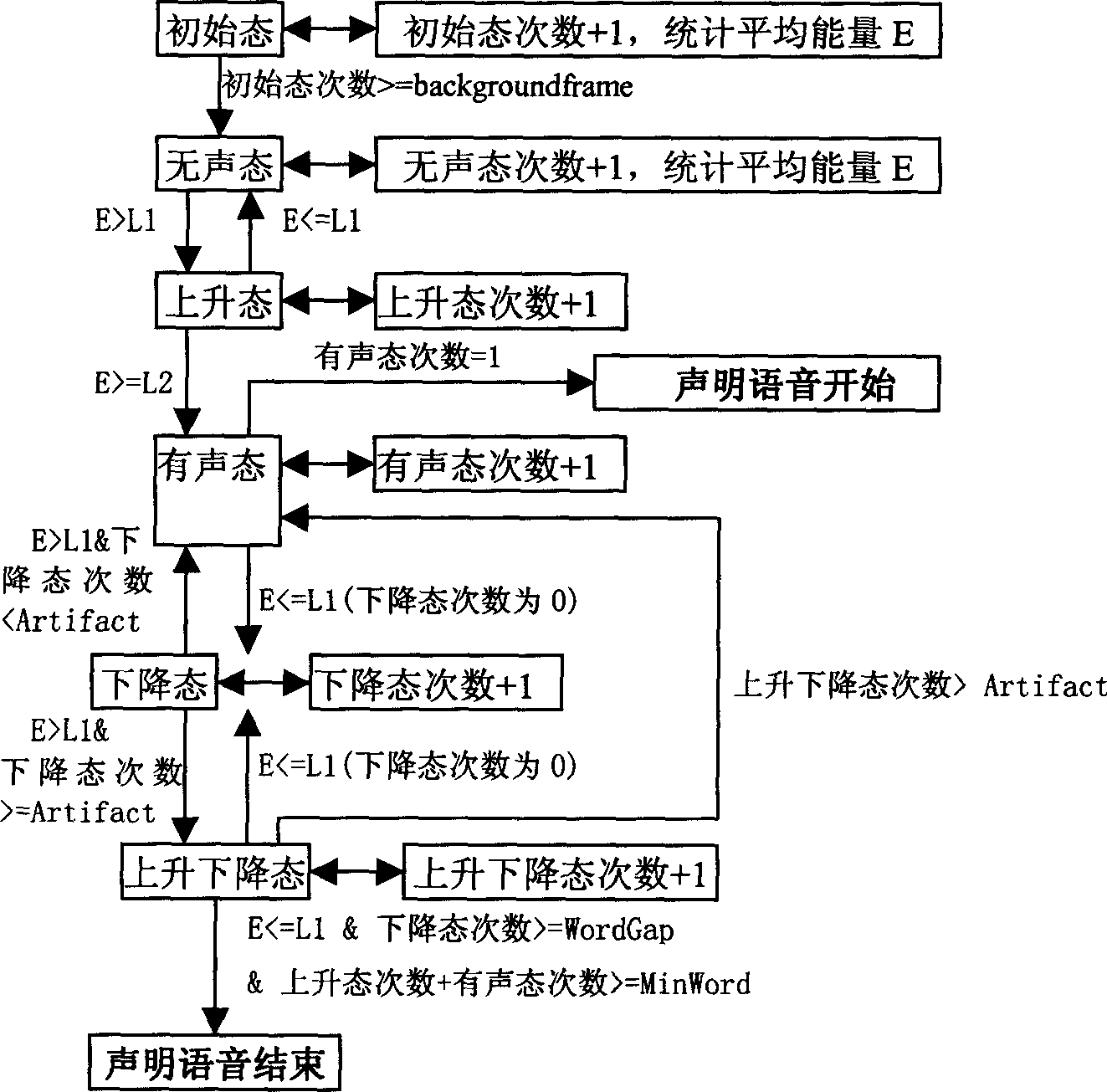
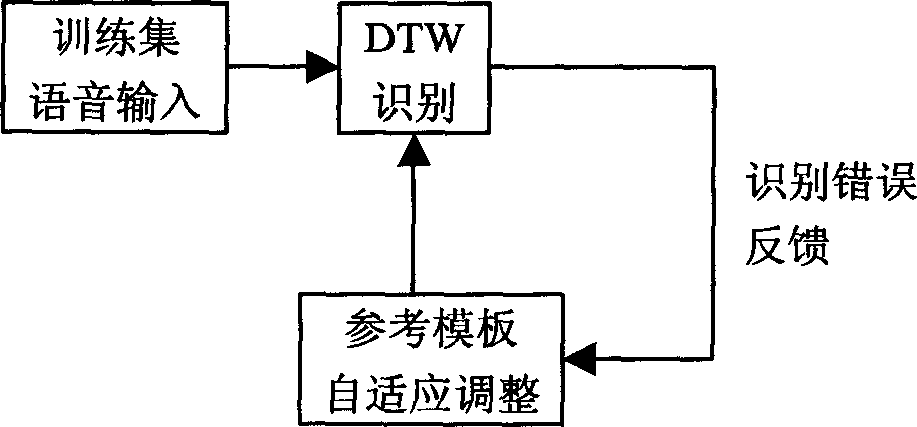
[0021] The voice processing process of the present invention can be divided into four parts: front-end processing, real-time recognition, back-end processing and template training. figure 1 described as follows:
[0022] 1. Front-end processing:
[0023] (1) Sampling the speech signal through an A / D (analog-to-digital) converter, and pre-emphasizing and windowing an...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More