

Data-field-based automatic clustering method
An automatic clustering and data field technology, applied in the field of cluster analysis, to achieve good robustness, improve computing speed, and avoid noise processing
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
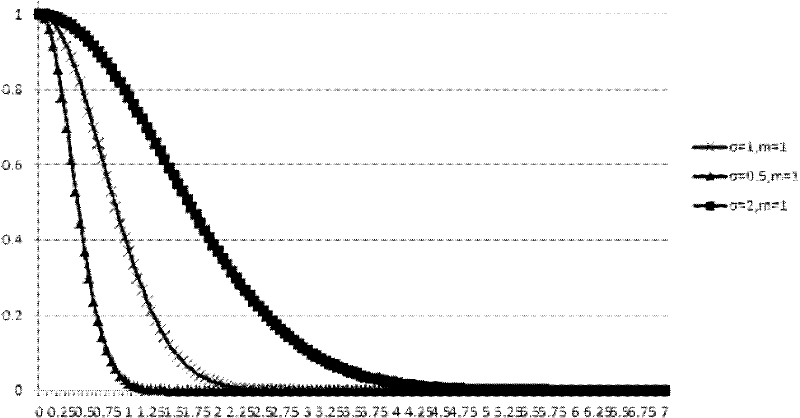
[0026] Inspired by the field theory in physics, Wang Shuliang and others put forward the idea of data field. Data radiates its data energy from the sample space to the entire parent space through data radiation, and the space that receives data energy and is covered by data radiation is called data field. The data field can be regarded as a space full of data energy, the data transmits energy to another data in the field through its own data field. The data points in the data field radiate energy to each other, and these energies superimpose each other to form the potential of the data field. According to different data objects, the field strength function of the data field can be defined in various forms. In the present invention, the nuclear radiation derived field is used, and the corresponding potential function is as formula (1).
[0027] Formula (1)
[0028] Among them, x, y are two data points, σ is the influence factor of the data field, ||x-y|| 2 is the Eucli...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More