

Large-scale data mining method capable of guaranteeing quality monotony
A technology of large-scale data and monotonicity, which is applied in the direction of electrical digital data processing, special data processing applications, instruments, etc., and can solve problems such as difficulty in mining result quality and resource limitations, and approximate result quality monotonicity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


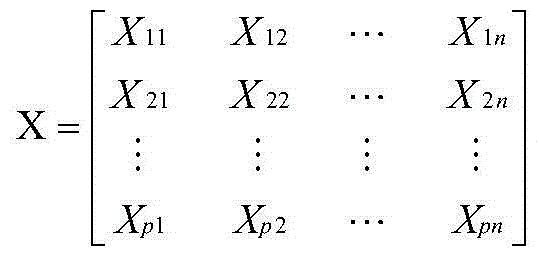
Examples
Embodiment Construction
[0046] The following examples describe the present invention in more detail.
[0047] The present invention provides a big data mining method that guarantees monotonic quality. The process of the method is as follows: figure 1 Shown. The specific implementation of the present invention is:
[0048] The first stage: Perform data preprocessing and other operations on the data set to represent the data as a representation that can be processed by the mining part.
[0049] Step 1) Obtain the original iris data set (see Table 1).
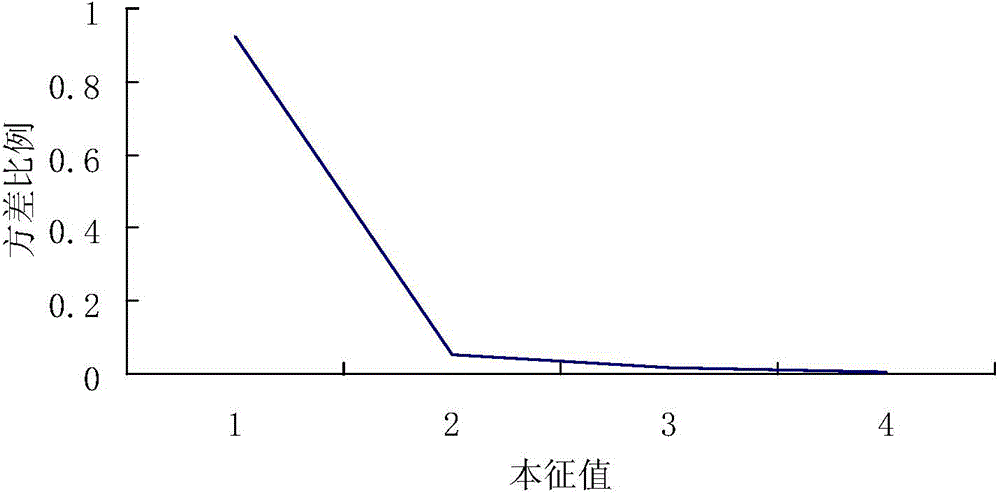
[0050] Step 2) Use the principal component analysis method to reduce the dimensions of the data. Prevent the occurrence of maintenance disasters.
[0051] In this example, the iris flower data set contains information about 150 species of iris, and each 50 species are taken from one of the three iris species: Setosa, Versicolour, and Virginica. The characteristics of each flower are described by the following 5 attributes:
[0052] (1) Sepal length (cm)
[0053]...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More