

Big-data-oriented cloud disaster tolerant backup method
A disaster recovery backup and big data technology, which is applied in the direction of data error detection and response error generation, can solve the problem of limiting the throughput of big data storage systems, failing to meet real-time system requirements, and aggravating the client. Load and other issues, to achieve the effect of enhancing the remote disaster recovery function, saving disaster recovery costs, and reducing the risk of data leakage
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0028] The present invention will be further described in detail below in conjunction with the embodiments and the accompanying drawings, but the embodiments of the present invention are not limited thereto.
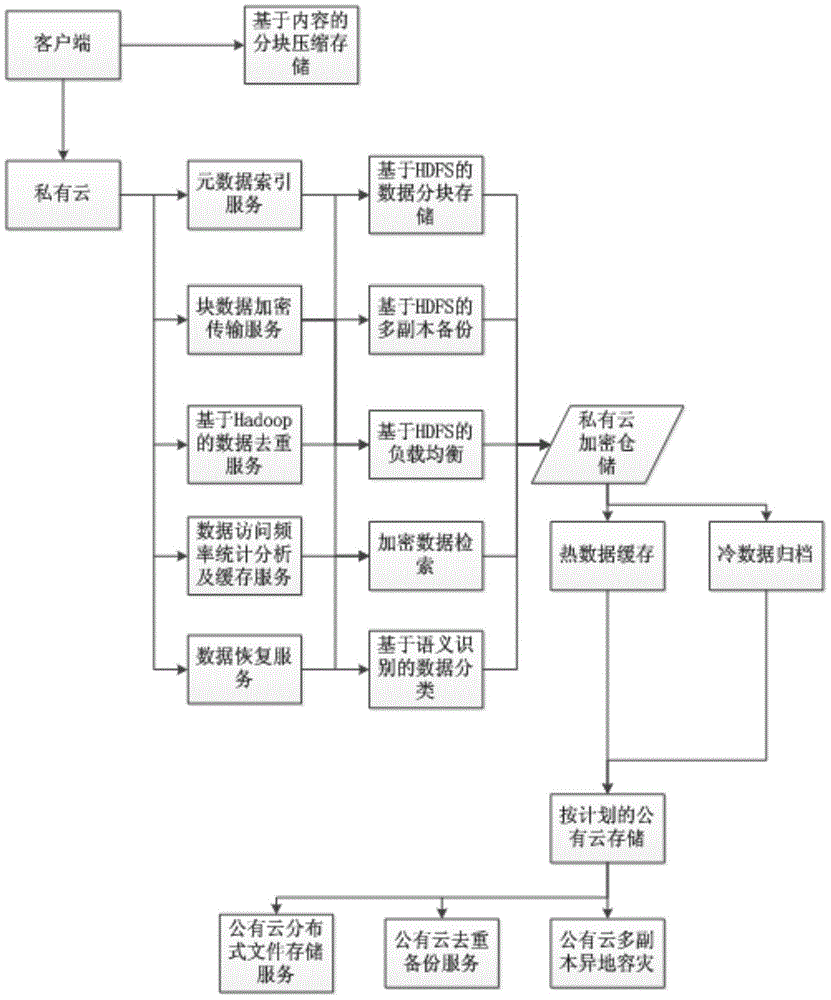
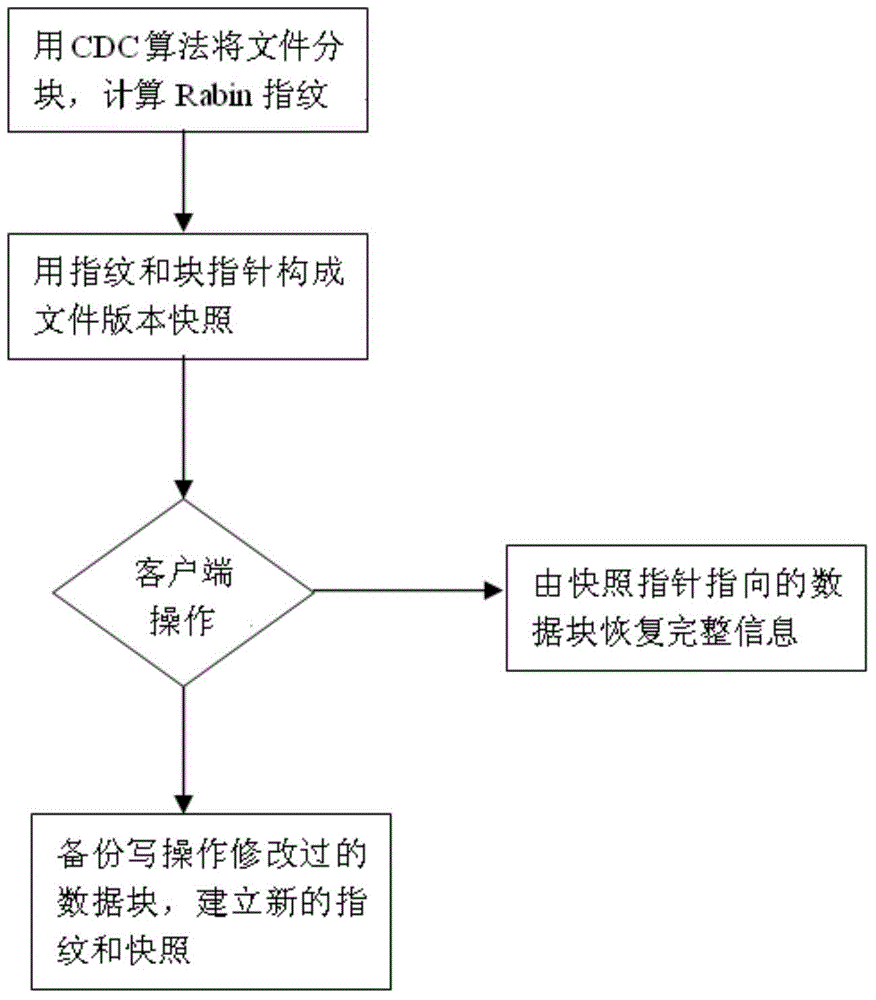
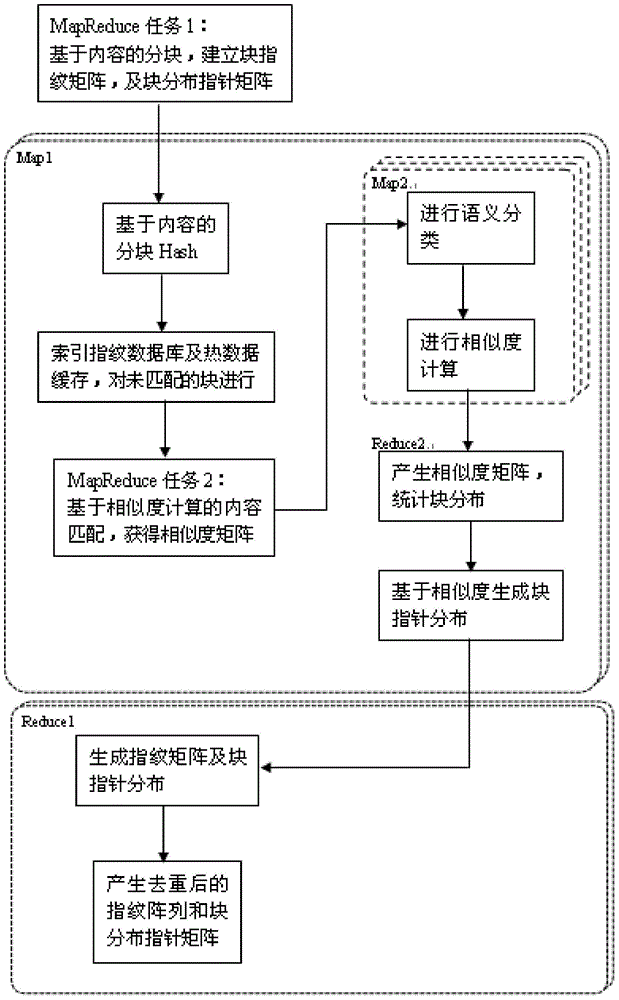
[0029] The present invention utilizes the repeated data deletion technology based on content recognition to perform distributed data deduplication. After the server of the cloud storage network performs disaster recovery backup for the client of the production system, it reads and extracts the metadata of the data objects in the backup set, and stores them in the cache nodes of the cloud storage network. When new metadata enters, the old and new Compare the metadata array spaces of different versions, and if metadata of the same version is found, further compare the data objects byte by byte, so as to find changed data (even if the metadata versions are the same). If the data object is repeated, assign a pointer to the data object, and finally delete the data object. Th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More