

Voice synthesis method and apparatus
A technology of speech synthesis and speech data, applied in speech synthesis, speech analysis, instruments, etc., to improve user experience and reduce scale requirements
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
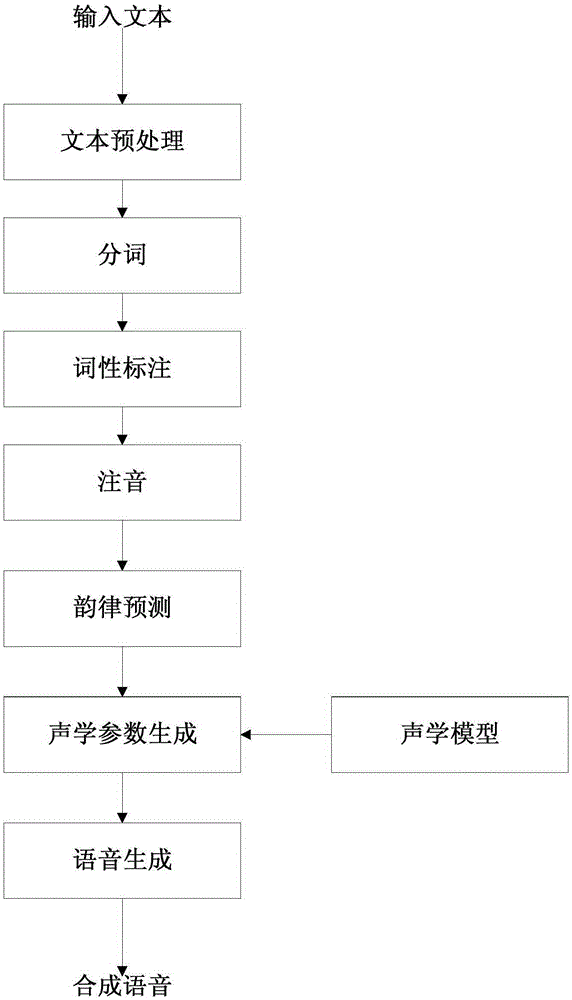
[0020] figure 2 This is a flowchart of a speech synthesis method provided in the first embodiment of the present invention. This embodiment is applicable to the case of personalized acoustic model training. The method is mainly executed by a speech synthesis device in a computer device, and the computer device includes But it is not limited to at least one of the following: user equipment and network equipment. User equipment includes but is convenient for computers, smart phones, and tablets. Network equipment includes, but is not limited to, a single network server, a server group composed of multiple network servers, or a cloud composed of a large number of computers or network servers for cloud computing. Such as figure 2 As shown, the method specifically includes the following operations:
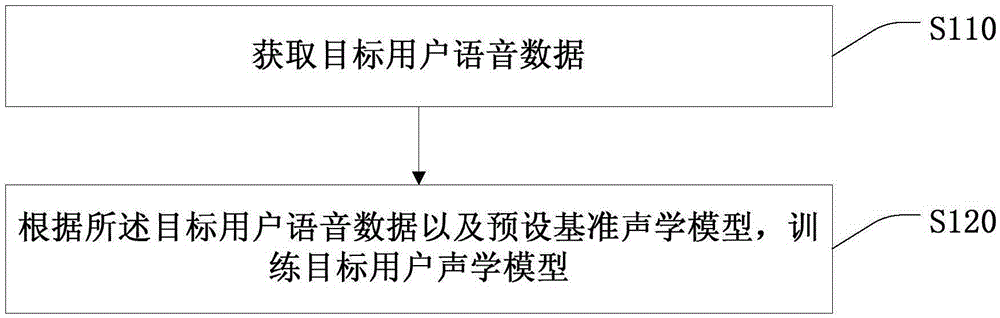
[0021] S110: Acquire voice data of the target user;
[0022] The target user voice data includes the voice characteristics of the target user. Generally, the recorded text is pre-design...
Embodiment 2
[0028] image 3 This is a schematic flowchart of a speech synthesis method provided in the second embodiment of the present invention, such as image 3 As shown, the method specifically includes:
[0029] S210: Acquire voice data of the target user;
[0030] This operation is similar to the operation S110 in the above-mentioned first embodiment, and will not be repeated in this embodiment.
[0031] S220: Perform voice annotation on the voice data of the target user to obtain text context information corresponding to the voice data of the target user.
[0032] Wherein, the voice labeling includes: syllable and phonetic segmentation labeling, accent and intonation labeling, prosodic labeling, boundary and part-of-speech labeling of the target user's voice data. In Chinese, a Chinese character represents a syllable, and the initials and vowels are phonemes. Prosody generally includes three levels of prosodic words, prosodic phrases and intonation phrases. One or more prosodic words cons...
Embodiment 3
[0048] Figure 4 This is a schematic flow chart of a speech synthesis method provided in Embodiment 3 of the present invention, such as Figure 4 As shown, the speech synthesis method specifically includes:
[0049] S310. Acquire voice data of the target user;
[0050] S320: Training the target user's acoustic model according to the target user's voice data and a preset reference acoustic model;
[0051] S330: Acquire text data to be synthesized;
[0052] Among them, the text data to be synthesized can be news text data, e-books, or text data received by mobile phone short messages and instant messaging software.
[0053] S340: Convert the text data to be synthesized into voice data according to the target user acoustic model.
[0054] When there is a voice synthesis requirement, the corresponding target user acoustic model is selected, and the text data to be synthesized is converted into text voice data, and the converted voice data has the voice characteristics of the target user.
[0...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More