

Large spatial data clustering algorithm K-DBSCAN based on density
A technology of spatial data and clustering algorithm, applied in computing, computer components, instruments, etc., can solve the problems that DBSCAN cannot be applied
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
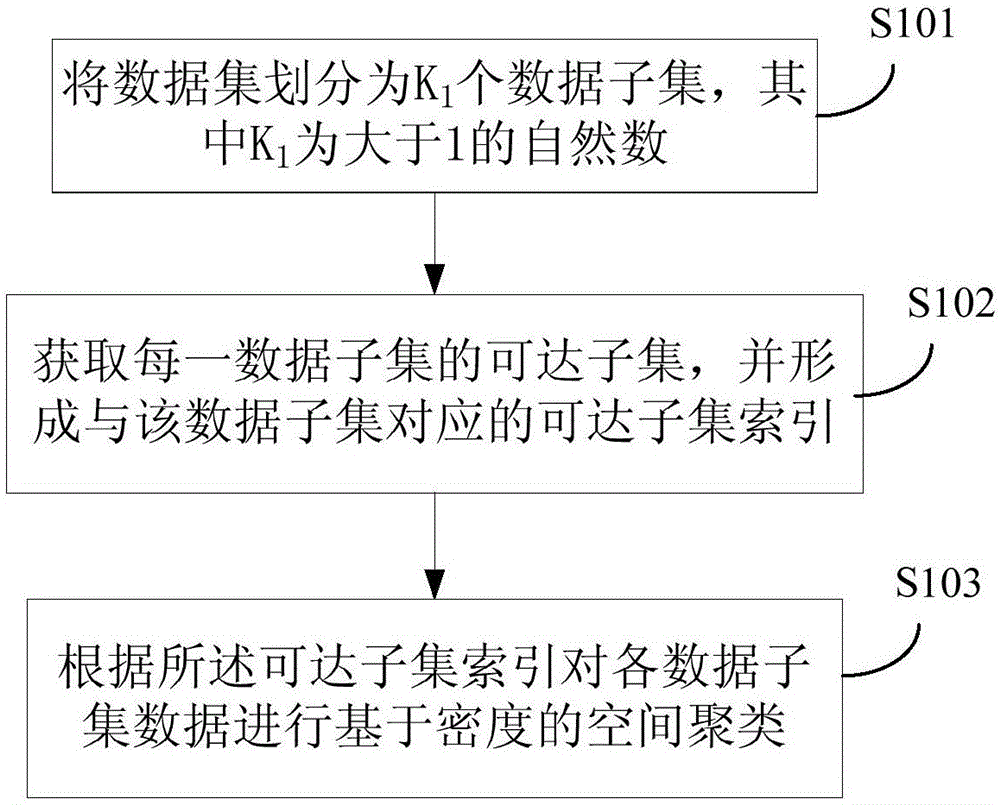
[0119] This embodiment provides a density-based large-scale spatial data clustering algorithm K-DBSCAN, such as figure 1 shown, including:
[0120] S101: Divide the dataset into K 1 data subsets, where K 1 is a natural number greater than 1.
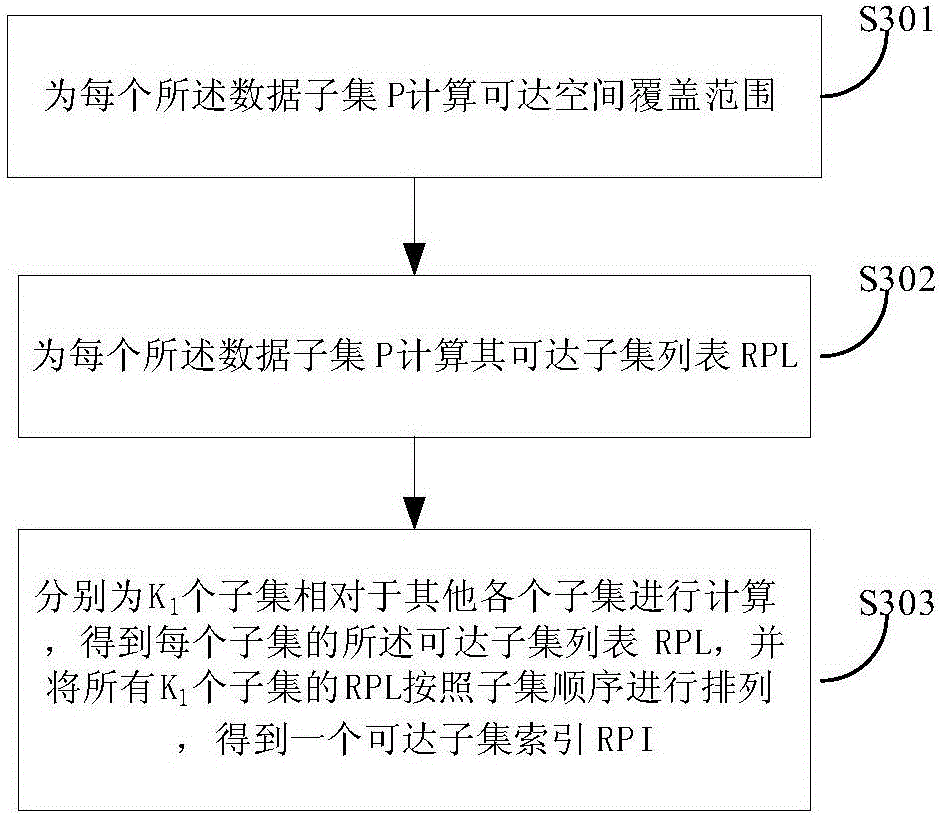
[0121] S102: Obtain an accessible subset of each data subset, and form an accessible subset index corresponding to the data subset.
[0122] S103: Perform density-based spatial clustering on the data of each data subset according to the reachable subset index.
[0123] In the above scheme, the data set is firstly divided into data subsets to obtain multiple data subsets, and then a reachable subset index is used to guide clustering, and finally a clustering algorithm is used for each divided data subset to carry out spatial analysis. clustering. This algorithm greatly reduces the computational complexity of density-based spatial data clustering, making the algorithm widely applicable to mass data clustering.
Embodiment 2
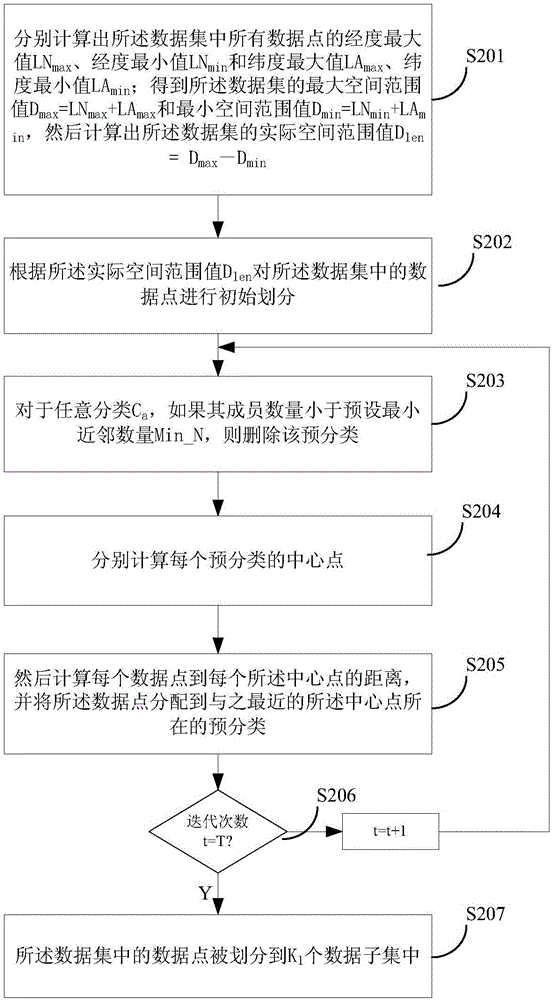
[0125] In the above step S101, the data set can be divided in various ways, specifically, it is necessary to ensure that each divided data subset has a specific space and data points. An implementation is provided in this embodiment, using an improved k-means clustering algorithm to perform spatial division and clustering on the data set, including:
[0126] Specifically, such as figure 2 shown, including the following steps:
[0127] S201: Calculate the maximum longitude LN of all data points in the data set respectively max , longitude minimum LN min and latitude maximum LA max , latitude minimum LA min ; Get the maximum spatial range value D of the data set max =LN max +LA max and the minimum spatial extent value D min =LN min +LA min , and then calculate the actual spatial extent value D of the data set len =D max -D min .
[0128] S202: According to the actual space range value D len The data points in the data set are initially divided, and the specific a...
Embodiment 3
[0212] Figure 9 It is a schematic diagram of the hardware structure of an electronic device that implements the density-based large-scale spatial data clustering algorithm K-DBSCAN provided in this embodiment, such as Figure 9 As shown, the equipment includes:
[0213] one or more processors 701 and memory 702, Figure 9 A processor 701 is taken as an example.
[0214] The device for executing the density-based large-scale spatial data clustering algorithm K-DBSCAN may further include: an input device 703 and an output device 704 .
[0215] The processor 701, the memory 702, the input device 703 and the output device 704 may be connected via a bus or in other ways, Figure 9 Take connection via bus as an example.
[0216] The memory 702, as a non-volatile computer-readable storage medium, can be used to store non-volatile software programs, non-volatile computer-executable programs and modules, such as the density-based large-scale spatial data aggregation in the embodim...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More