

Open domain video natural language description generation method based on multi-modal feature fusion
A technology of feature fusion and natural language, applied in the field of video analysis, can solve problems such as not considering other features, only using RGB image features, and not studying other information too much, so as to increase robustness and speed, improve accuracy, The effect of high robustness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
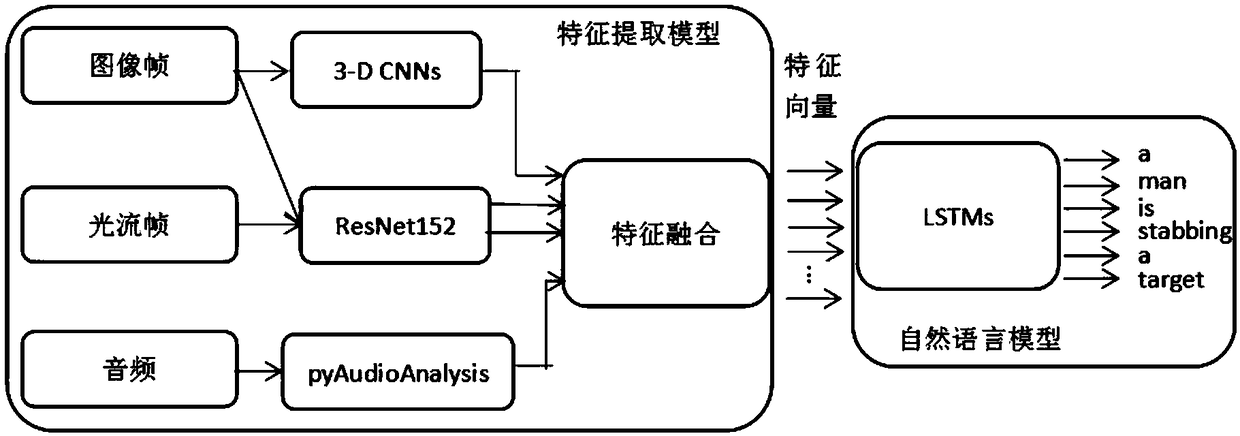
[0033] Such as figure 1 The shown open-domain video natural language description model based on multimodal feature fusion is mainly divided into two major models, one is the feature extraction model, and the other is the natural language model. The present invention mainly studies the feature extraction model, which will be divided into four major models: Partial introduction.
[0034] The first part: ResNet152 extracts RGB image features and optical flow features,
[0035] (1) Extraction of RGB image features,
[0036] Use the ImageNet image database to pre-train the ResNet model. ImageNet contains 12,000,000 images divided into 1,000 categories, which can make the model more accurate in identifying objects in open-domain videos. The batch size of the neural network model is set to 50, and the learning rate at the beginning Set to 0.0001, the MSVD (Microsoft Research Video DescriptionCorpus) dataset contains 1970 video clips, with a duration between 8 and 25 seconds, corres...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More