

Speaker recognition method based on Triplet-Loss
A speaker recognition and speaker technology, applied in the field of neural network and deep learning, can solve the problems of channel environmental noise sensitivity, voice data sensitivity, and low accuracy, so as to improve reliability and accuracy, direct physical meaning, and improve The effect of discernment
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0045] The present invention will be further described below in conjunction with specific embodiment:
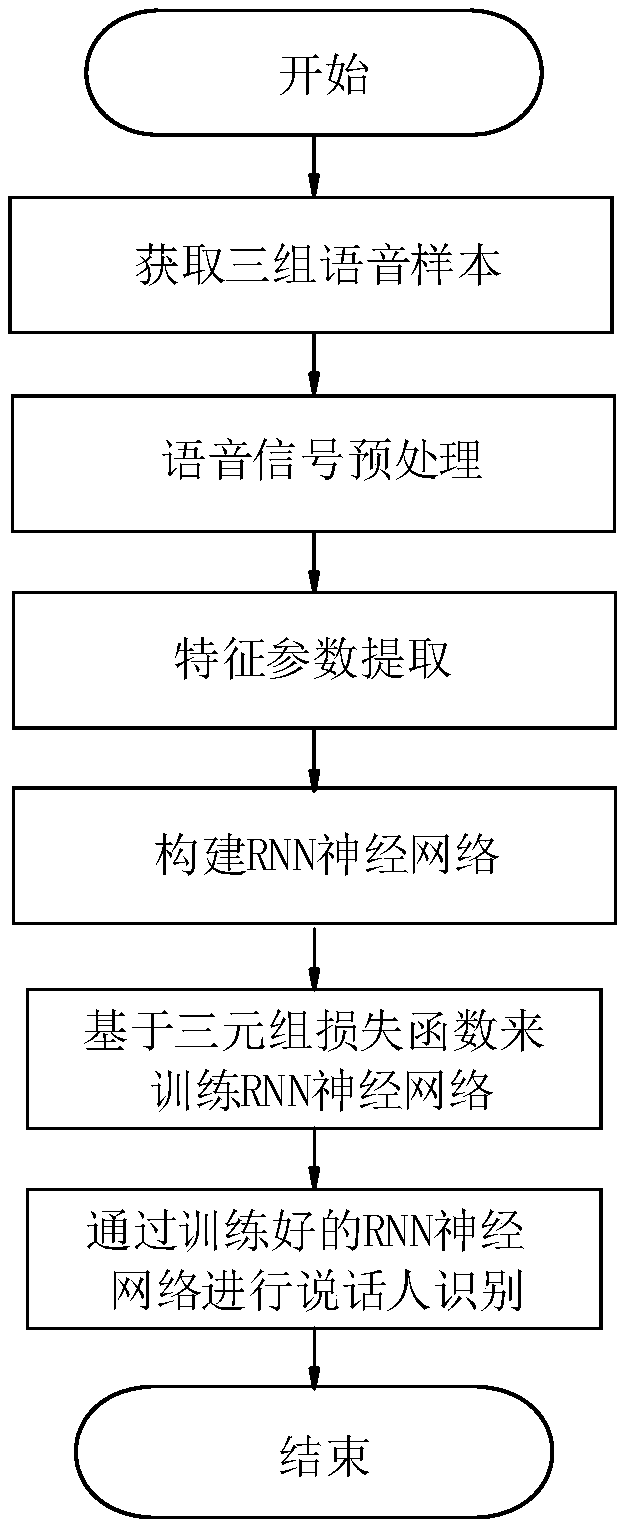
[0046] See attached figure 1 As shown, a kind of speaker recognition method based on Triplet-Loss described in this embodiment comprises the following steps:
[0047] S1: Acquire a speech signal, which includes three groups of samples, which are a group of speech sequences Xa of the speaker, another group of speech sequences Xp of the same speaker, and a group of speech sequences Xn of different speakers;
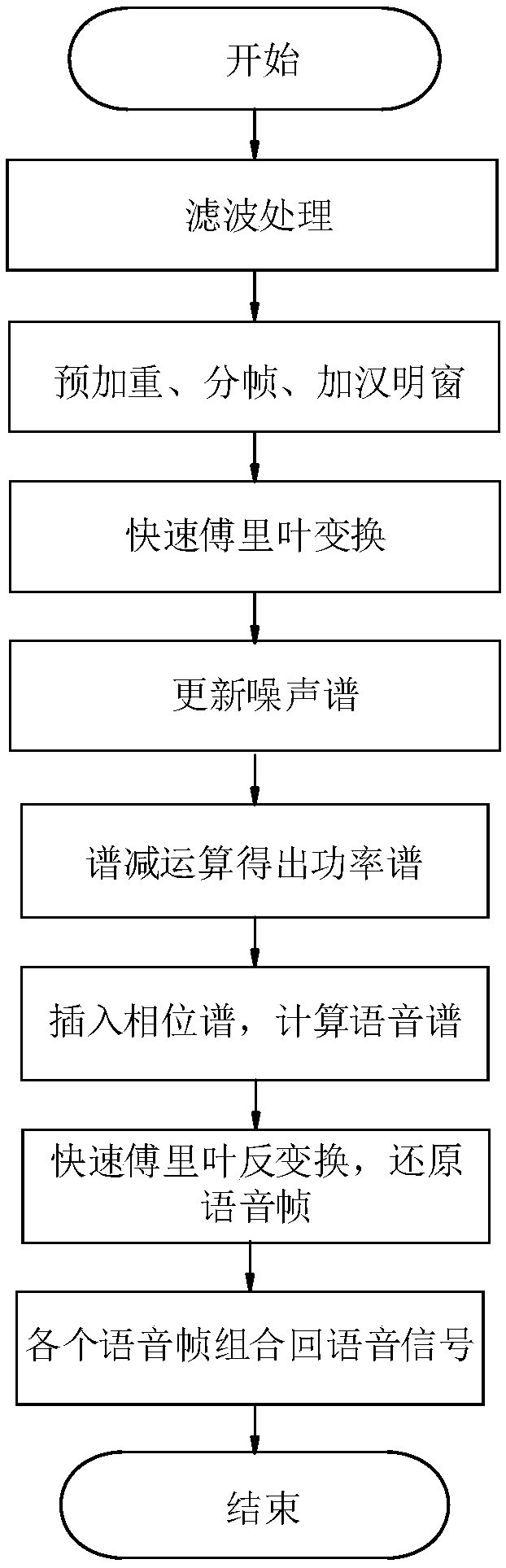
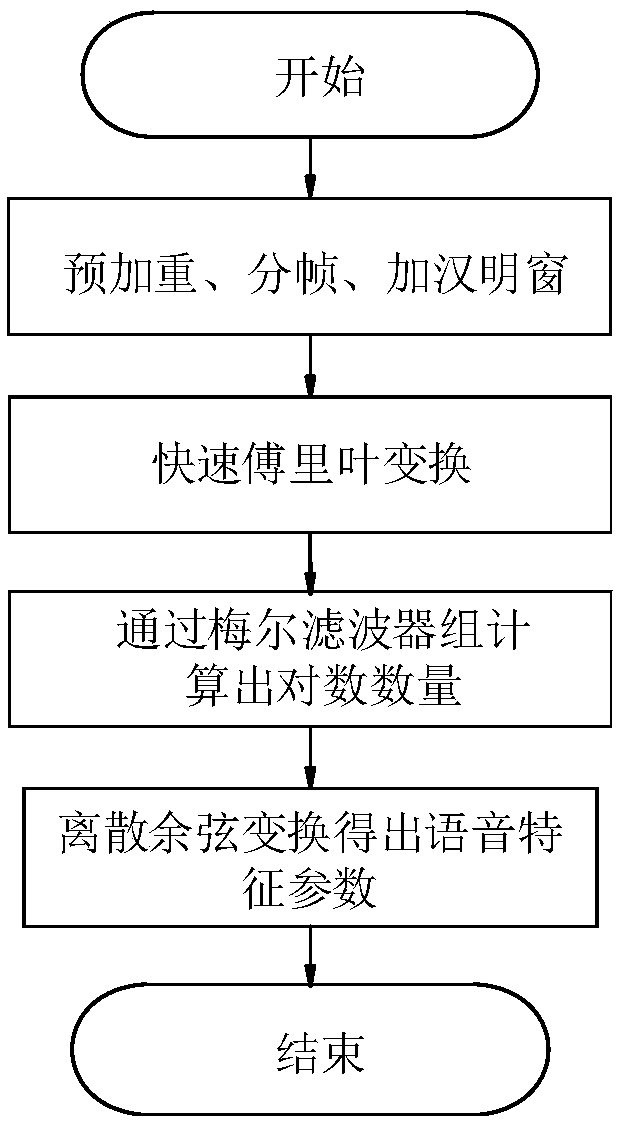
[0048] S2: Preprocessing the speech signal; more channel noise will be generated in the speech collection process, which will bring great difficulties to the recognition task, so firstly, the spectral subtraction method is used to denoise the input speech data, that is, from The noise spectrum estimate is subtracted from the noisy speech estimate to obtain the spectrum of the clean speech. What is eliminated here is the channel noise, which is the noise caused by the re...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More