

Model training method, server and computer readable storage medium
A model training and model technology, applied in computers, digital computer parts, computing, etc., can solve problems such as inability to exert parallel computing capabilities, waste of hardware resources, and low system acceleration ratios, to eliminate computing power bottlenecks and bandwidth bottlenecks. , Improve the effect of model training acceleration ratio
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
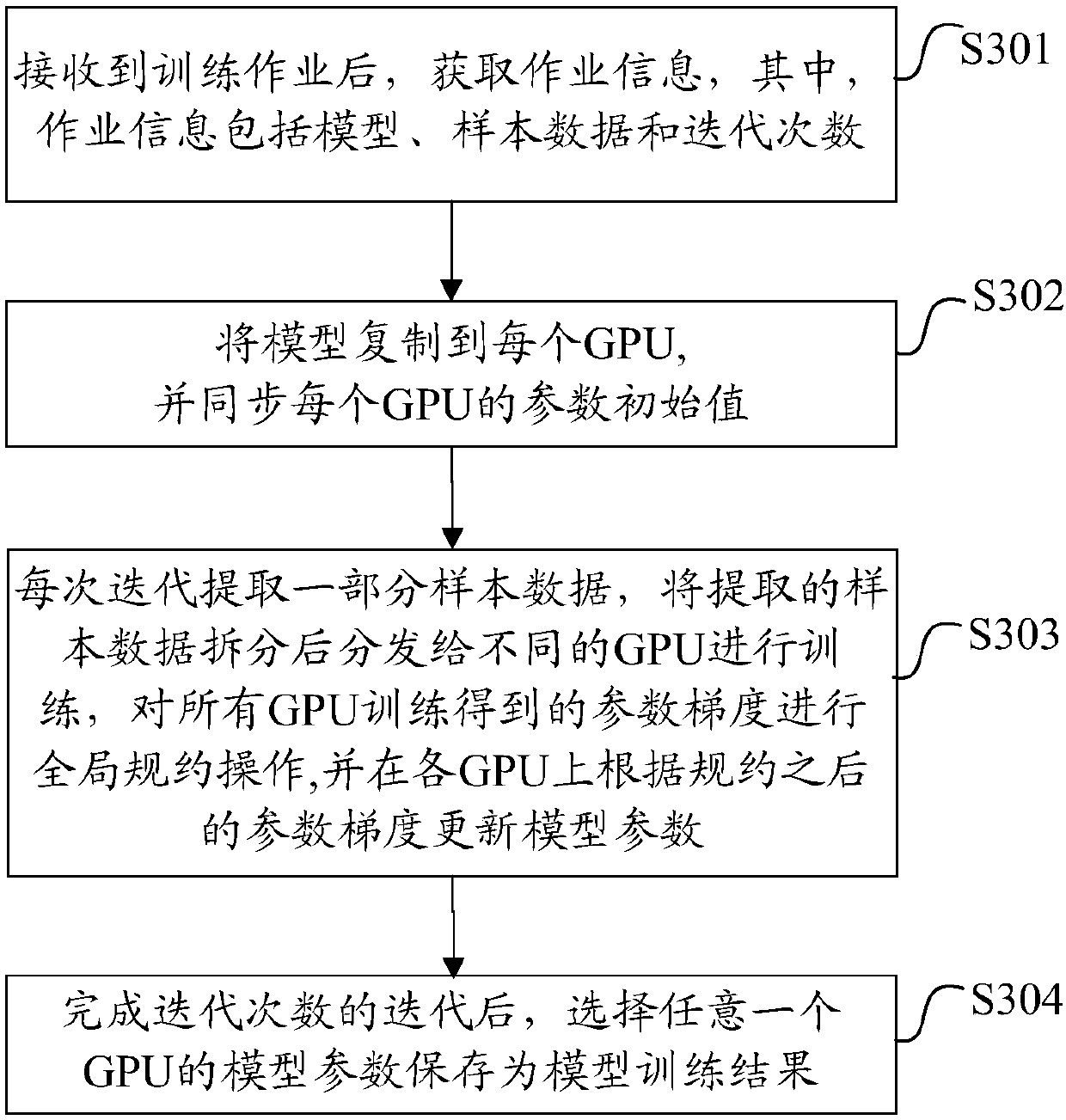
[0029] Such as image 3 As shown, the embodiment of the present invention provides a model training method, the method includes:
[0030] S301. After receiving a training job, acquire job information; wherein, the job information includes a model, sample data, and iteration times.
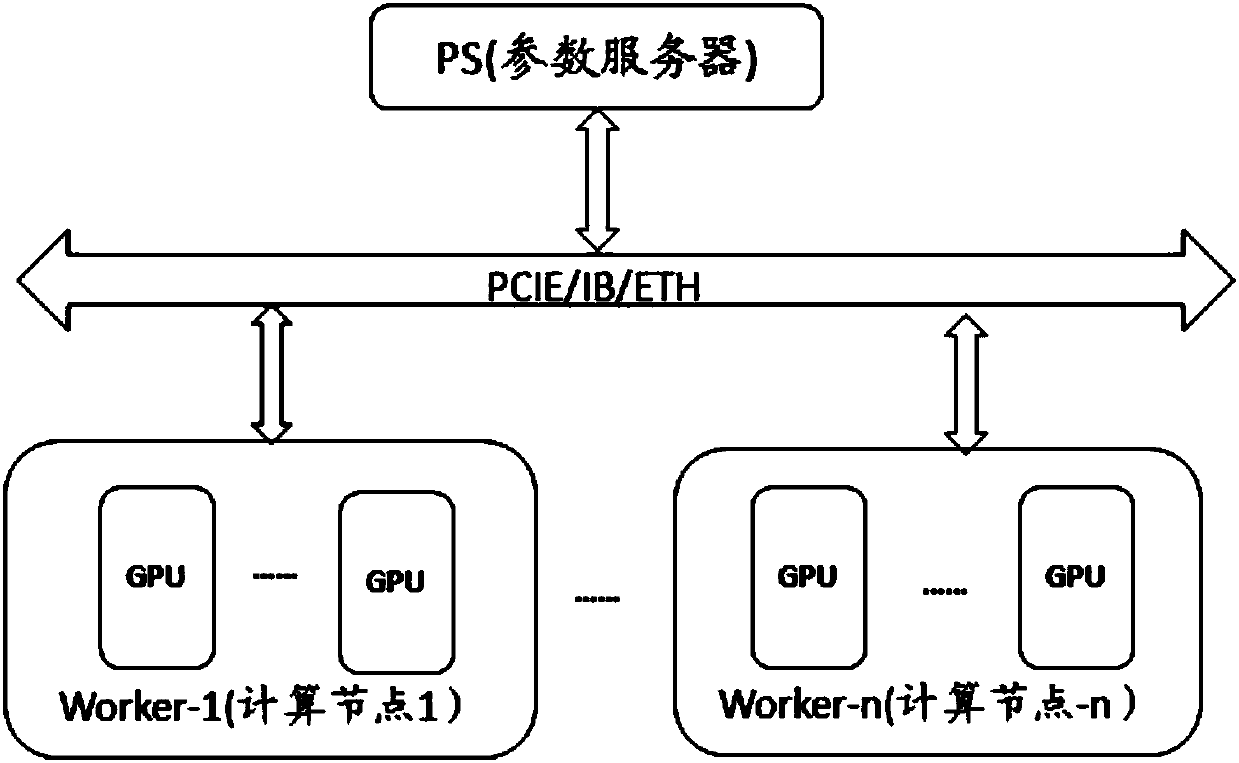
[0031] Specifically, after receiving the training job submitted by the user, the task management system extracts job information from it. Job information can include information such as deep learning models, sample data, resource requirements, and number of training iterations. Among them, the general form of the model is the program code written in the computer programming language, and the training system refers to the task management system that manages GPU clusters and general training platforms (such as matrix array Tensorflow, caffe2, etc.).
[0032] S302. Copy the model to each GPU, and synchronize the initial values of the model parameters of each GPU.
[0033] Specifically, the traini...
Embodiment 2
[0041] After the first embodiment of the above invention is implemented, the global specification of parameter gradients between GPUs needs to be completed between all GPUs. Typical deep learning models have parameters on the order of millions, tens of millions, or hundreds of millions. These parameter gradients are usually composed of a large number of multidimensional matrix arrays. Organized, the global reduction operation of parameter gradient multi-dimensional matrix array needs to be carried out among all GPUs one by one, and the additional overhead is also very large. In order to solve this problem, Embodiment 2 of the present invention utilizes the characteristics of low overhead for processing long messages by various communication protocols, and adds aggregation and splitting operations before and after the parameter gradient global reduction operation, so that the initial N small parameter gradient multidimensional matrices The arrays are merged into M (1≤M Figure 4 ...
Embodiment 3
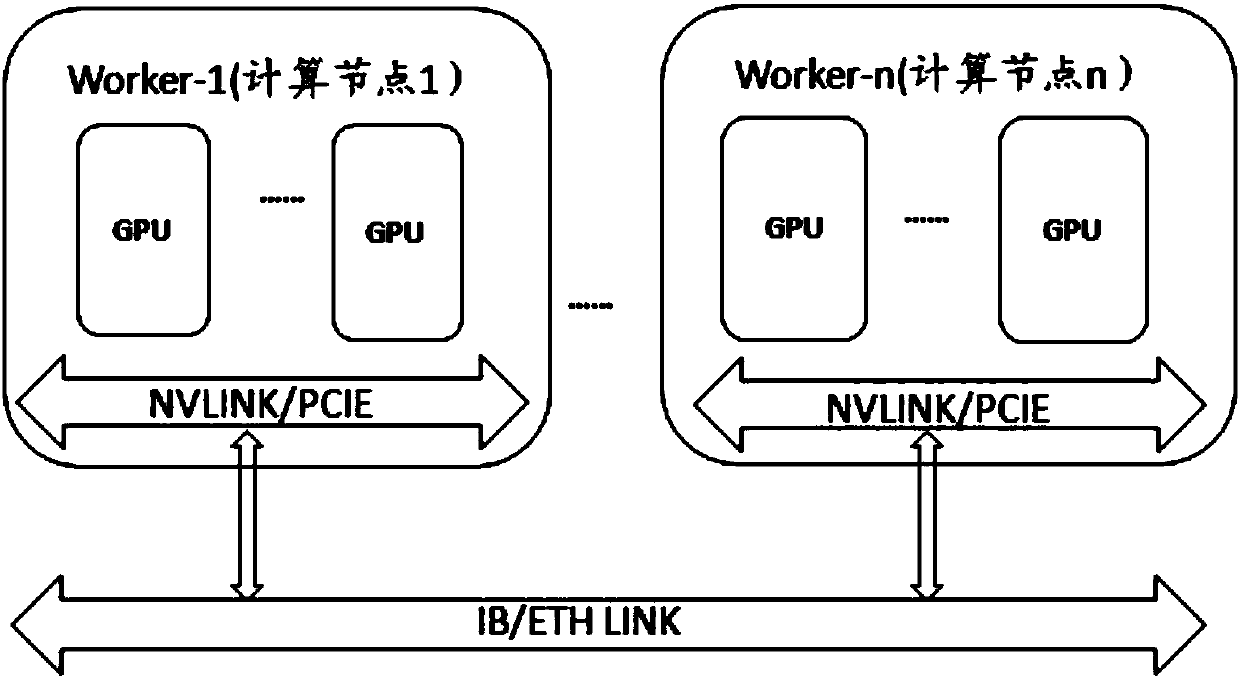
[0052] When performing parameter gradient global protocol operations on single-node or multi-node GPU clusters, the communication between nodes and within nodes may pass through various transmission media such as NVLink / PCIe / IB / ETH. In general, inter-GPU media within nodes (such as NVLink / PCIe) has high bandwidth, while inter-node bandwidth is low, directly synchronizing all inter-node and intra-node parameter gradients can make lower-bandwidth media (such as IB / ETH) a bottleneck. In order to solve this problem, in order to solve this problem, the third embodiment of the present invention splits the parameter gradient global statute process into multiple steps, and divides the high-bandwidth interconnected GPUs in the node into logical global statute groups. First, in the global statute The GPU in the group performs a global protocol operation, and then performs inter-group synchronization through the "representatives" selected in the group, so that the global protocol reduces ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More