

Broadcast signal prejudging and preprocessing method
A broadcast signal and preprocessing technology, applied in voice analysis, voice recognition, instruments, etc., can solve problems such as low efficiency, operator fatigue, easy to cause mistakes, and high misrecognition rate
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
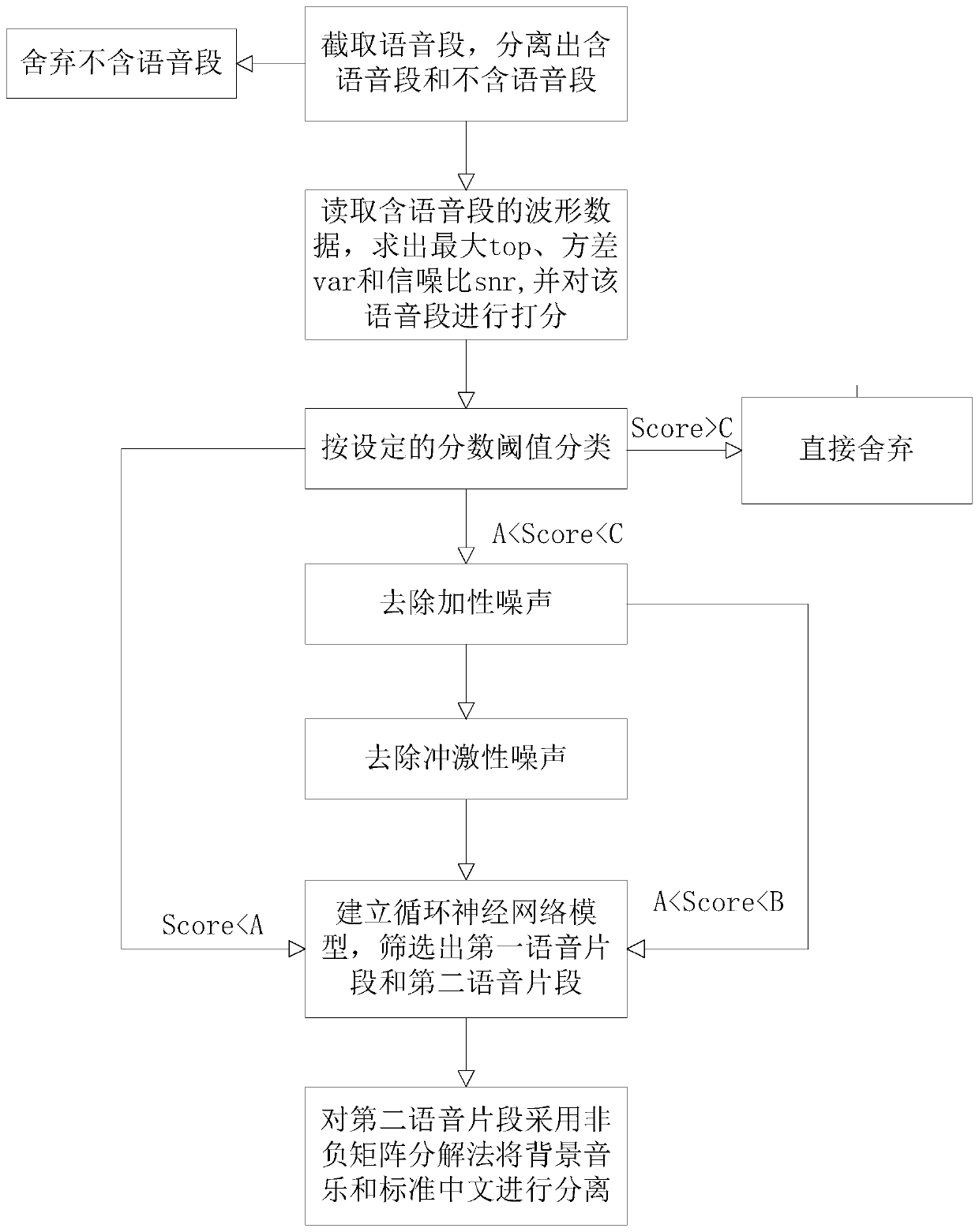
[0087] Such as figure 1 As shown, a broadcast signal prediction preprocessing method includes the following steps:
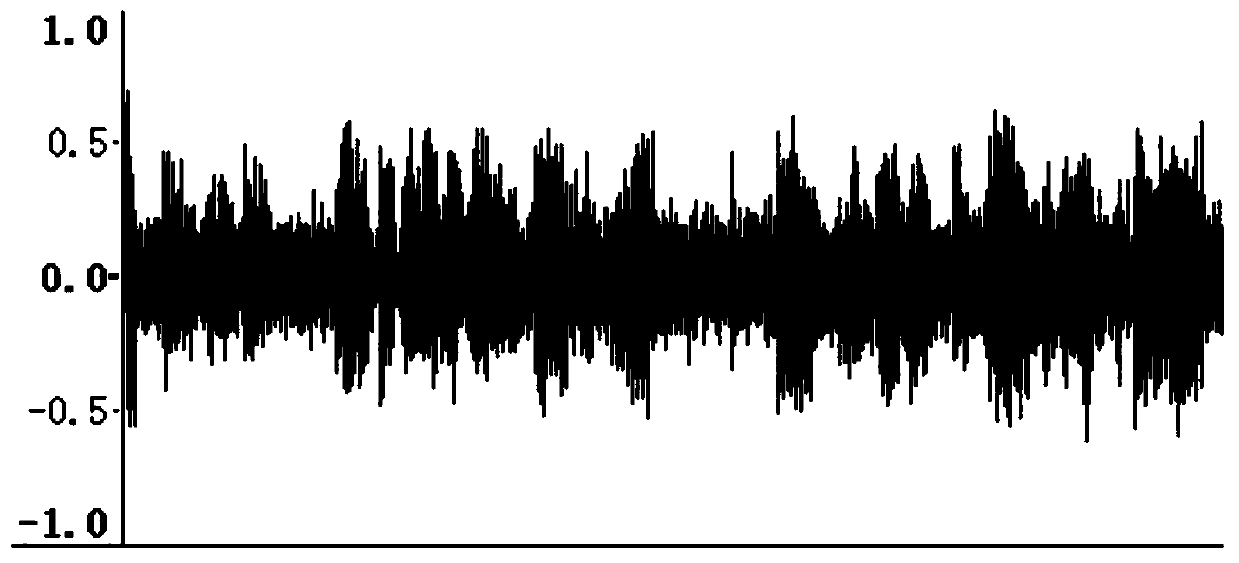
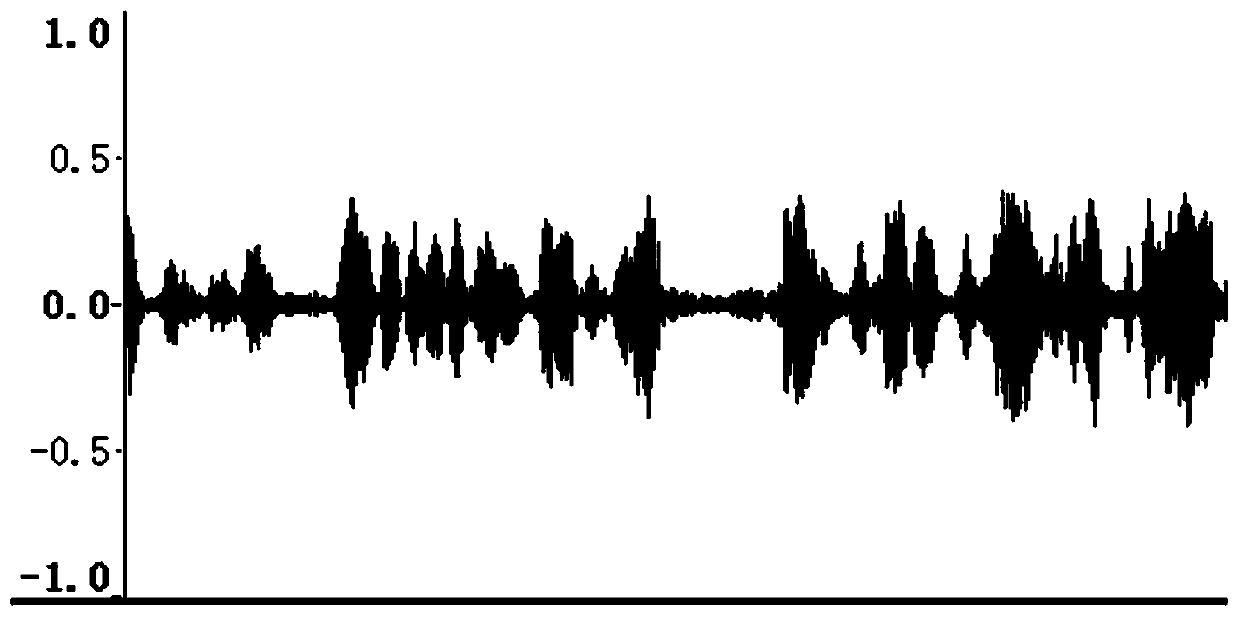
[0088] Step 1, intercept the speech segment, carry out coarse segmentation to it, and separate out containing the speech segment and not containing the speech segment; Definition contains the speech time domain sequence of the speech segment as X (n), abandons not containing the speech segment;
[0089] Specifically in this embodiment, the broadcast audio segment to be identified is divided into several sub-sections with a length of 3-5 seconds per segment, and the total number of segments obtained is recorded, and the Mel spectrogram of each sub-section is loaded into the convolutional network for The standard of "speech-based / non-speech-based" is classified into two categories, and the segment containing speech and the segment without speech are separated; the segment containing speech is defined as X(n), and the segment without speech is discarded;
[0090] ...
Embodiment 2
[0145] The difference between this embodiment and Embodiment 1 is that this embodiment adds the following steps in Step 4:
[0146] Step 4.7, compare the speech time domain sequence Yi(n)" or Xi(n)" obtained in step 4.6 with the speech time domain sequence Yi(n) or Xi(n) obtained in step 3, and calculate the residual sequence C i (m);
[0147] Step 4.8, for residual sequence C i (m) Execute the filtering process in step 4 to obtain a smooth residual sequence C i (m)";
[0148] Step 4.9, smoothing the residual sequence C i (m)” is compensated to the speech time-domain sequence Yi(n)” or Xi(n)” obtained in step 4.6 to obtain a new speech time-domain sequence Wi(n).
[0149] Since the initial signal has a lot of impulsive noise, it is smoothed after the filtering in step 4, so the residual error corresponding to this frequency band is often very large, so the residual error is processed by median smoothing and linear smoothing, so that Get a set of "normal" and "clean" resi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More