

Dynamic extensible convolutional neural network accelerator
A convolutional neural network and accelerator technology, applied in the fields of computing, calculation, and counting, which can solve problems such as reducing bandwidth, reducing neural network operation delay, and low latency.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0034] The present invention is further illustrated below in conjunction with specific embodiments, should be understood that these embodiments are only used to illustrate the present invention and are not intended to limit the scope of the present invention, after having read the present invention, those skilled in the art will understand the various equivalent forms of the present invention All modifications fall within the scope defined by the appended claims of this application.
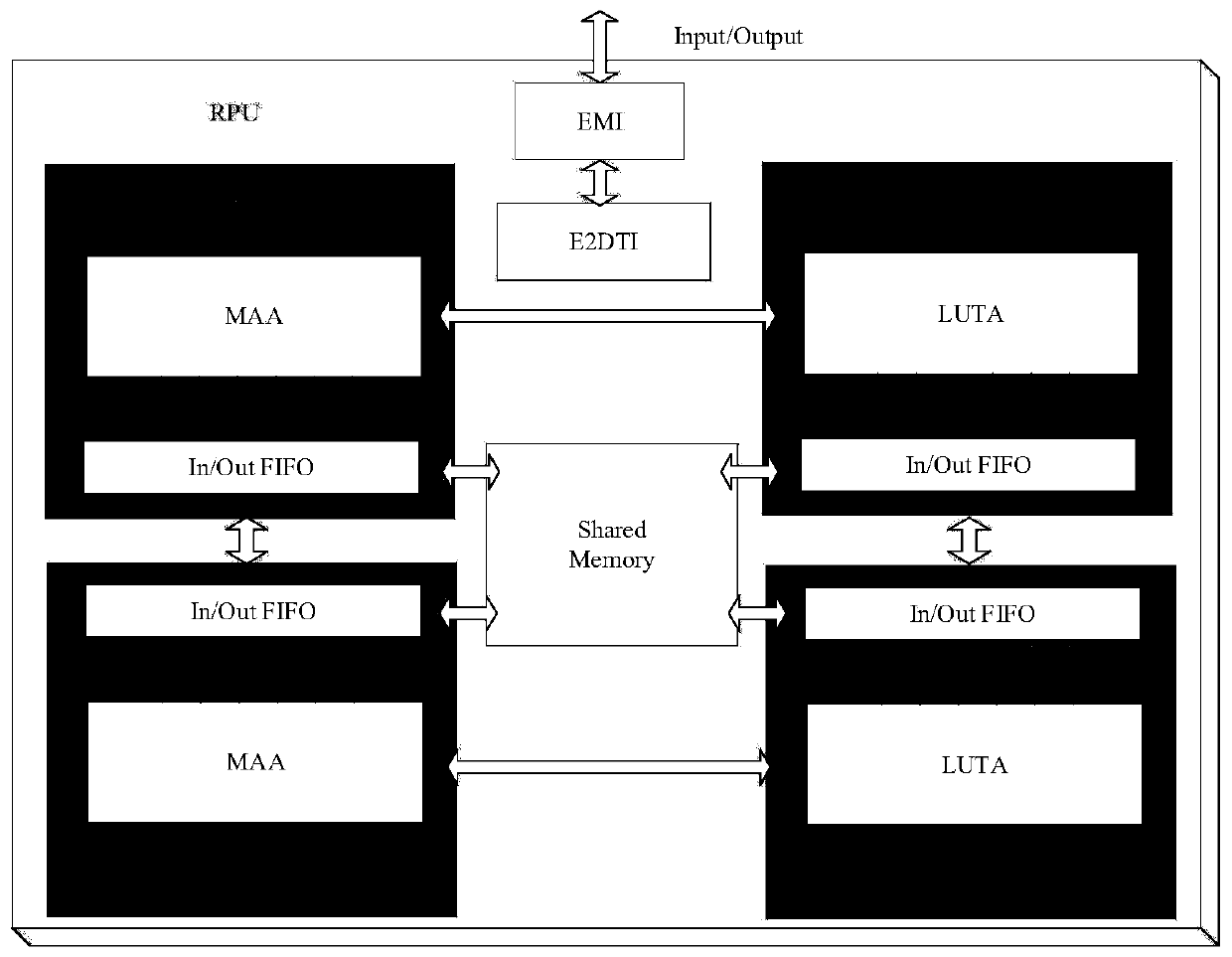
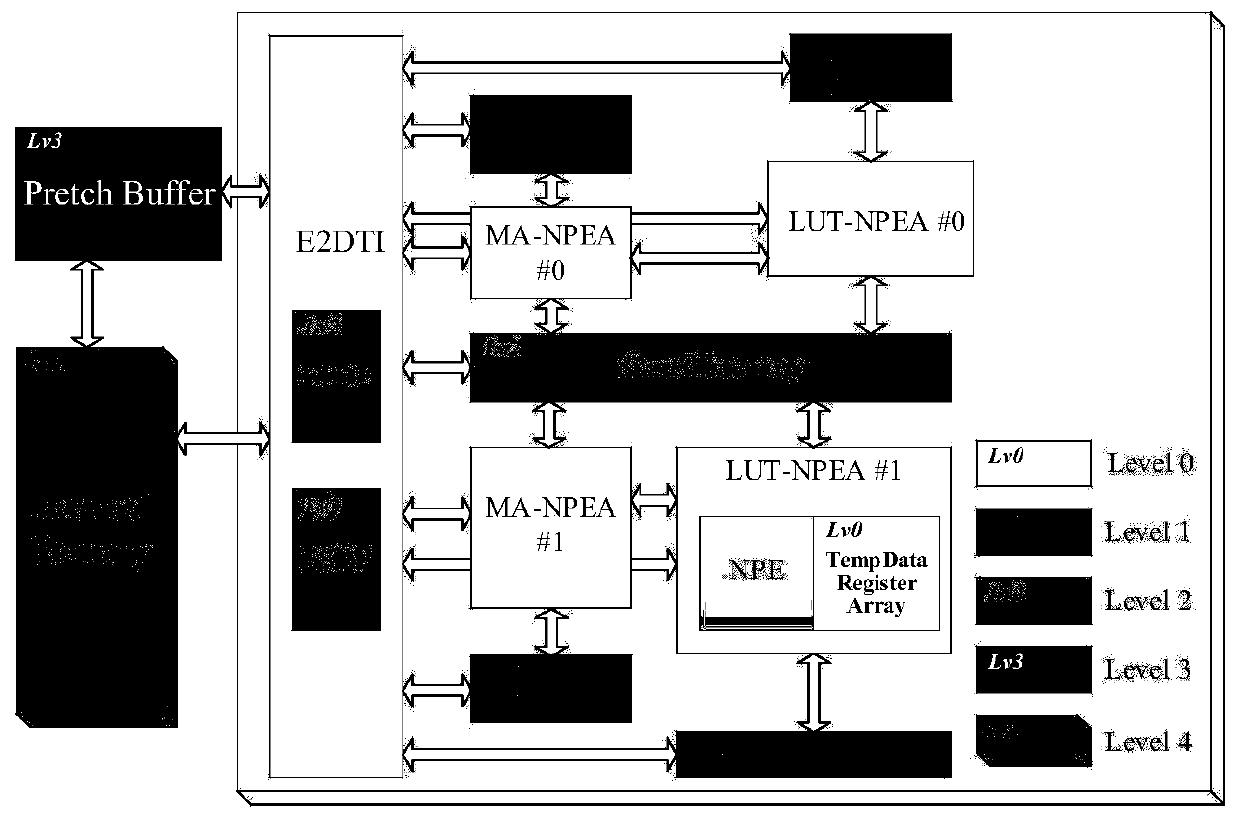
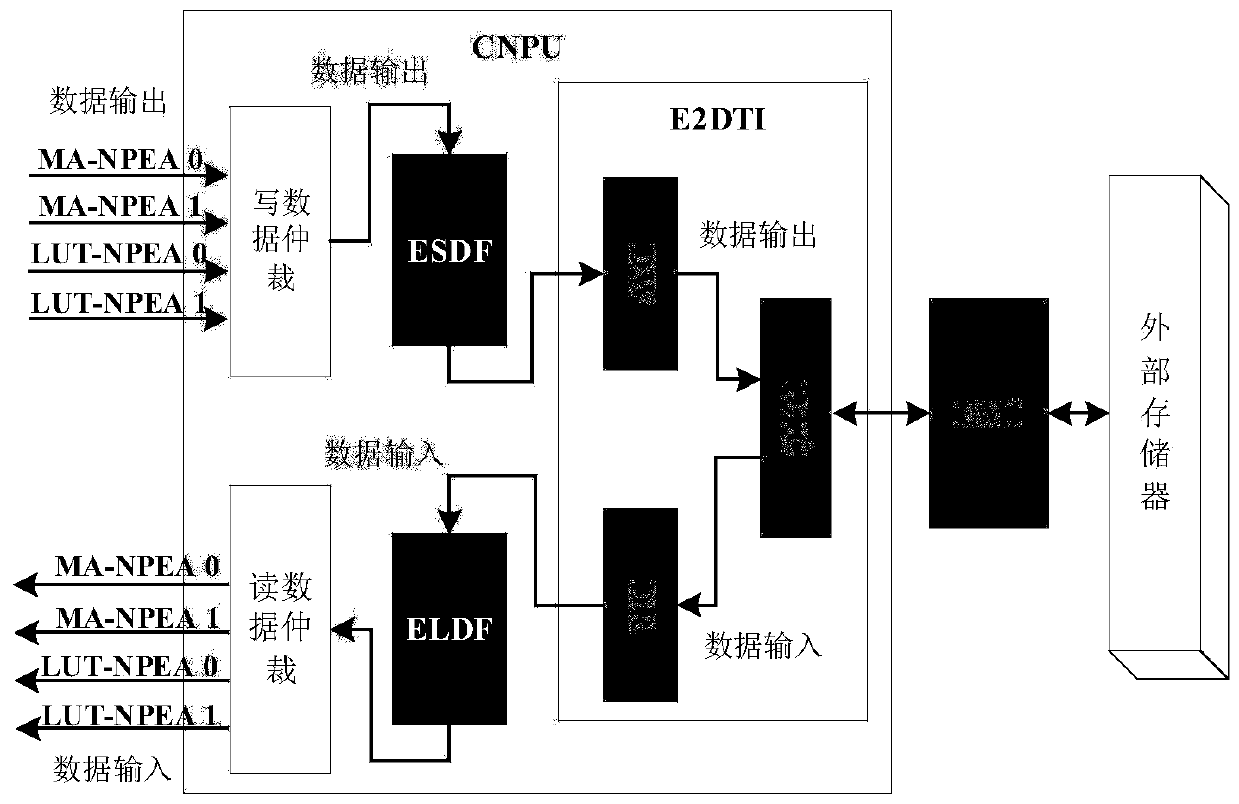
[0035] Such as figure 1 As shown, the computing array of the Convolutional Neuron Processing Unit (CNPU) adopts a heterogeneous design. The CNPU calculation subsystem includes the calculation array MA-NPEA based on the multiply-accumulate circuit, the calculation array LUT-NPEA based on the look-up table multiplier, and the shared memory between the arrays (Shared Memory). Two of each computing array. MA-NPEA consists of basic circuits such as approximate multipliers and approximate adders, and...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More