

Cross-view action recognition method based on skeleton self-similarity
A technology of self-similarity and action recognition, applied in biometric feature recognition, neural learning methods, character and pattern recognition, etc., can solve problems affecting action recognition and achieve good results and high structural stability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0057] This embodiment proposes a cross-view action recognition method based on skeleton self-similarity, including the following steps:
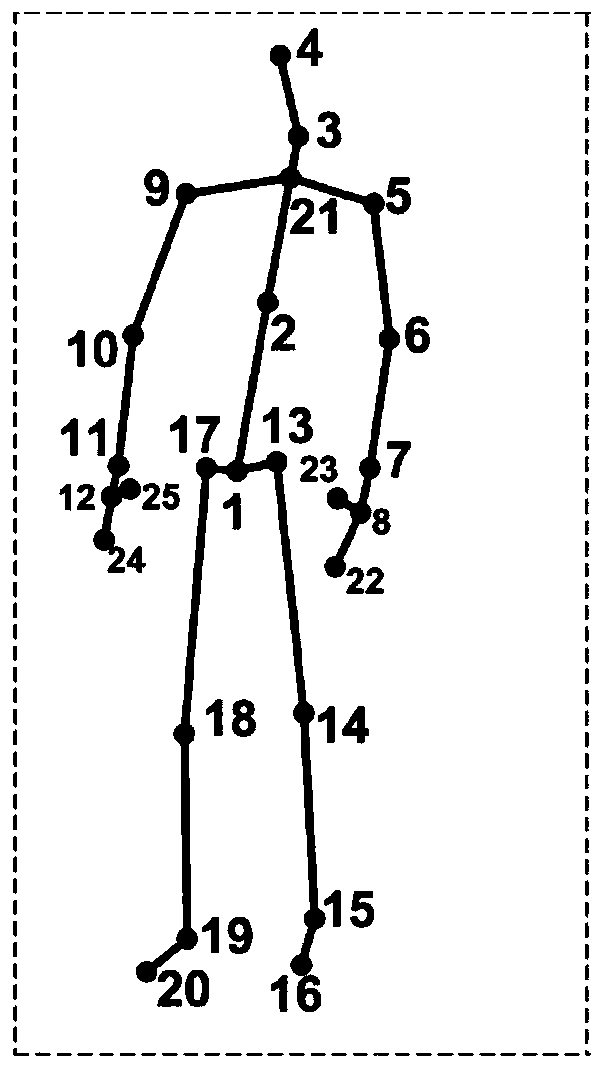
[0058] S1, acquire skeleton sequences at 3 scales in a fine-to-coarse manner;
[0059] S2, representing the skeleton self-similarity as a self-similar image SSI;
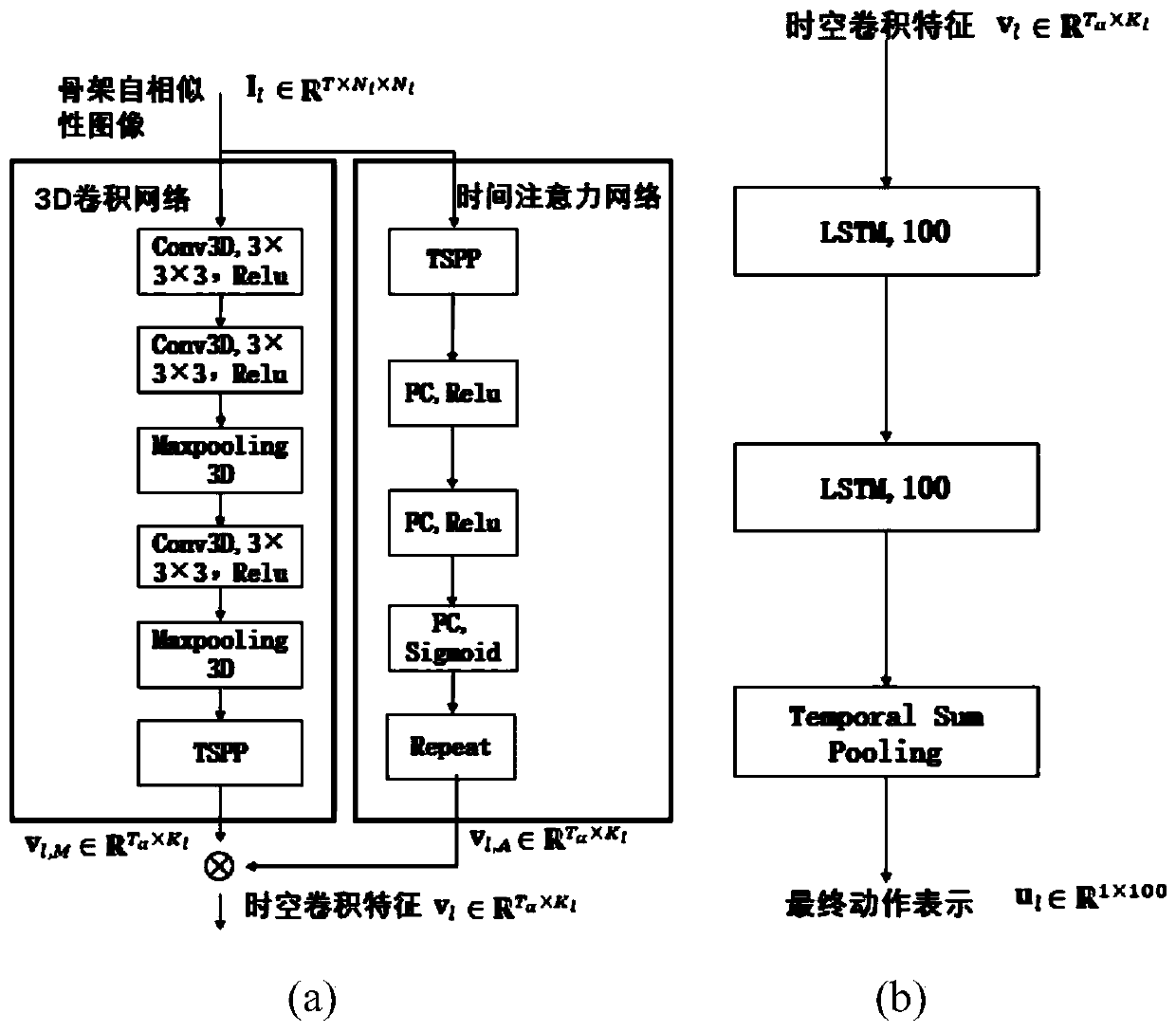
[0060] S3, constructing the space-time convolution module SCM;
[0061] S4, constructing the sequence encoding module SEM;
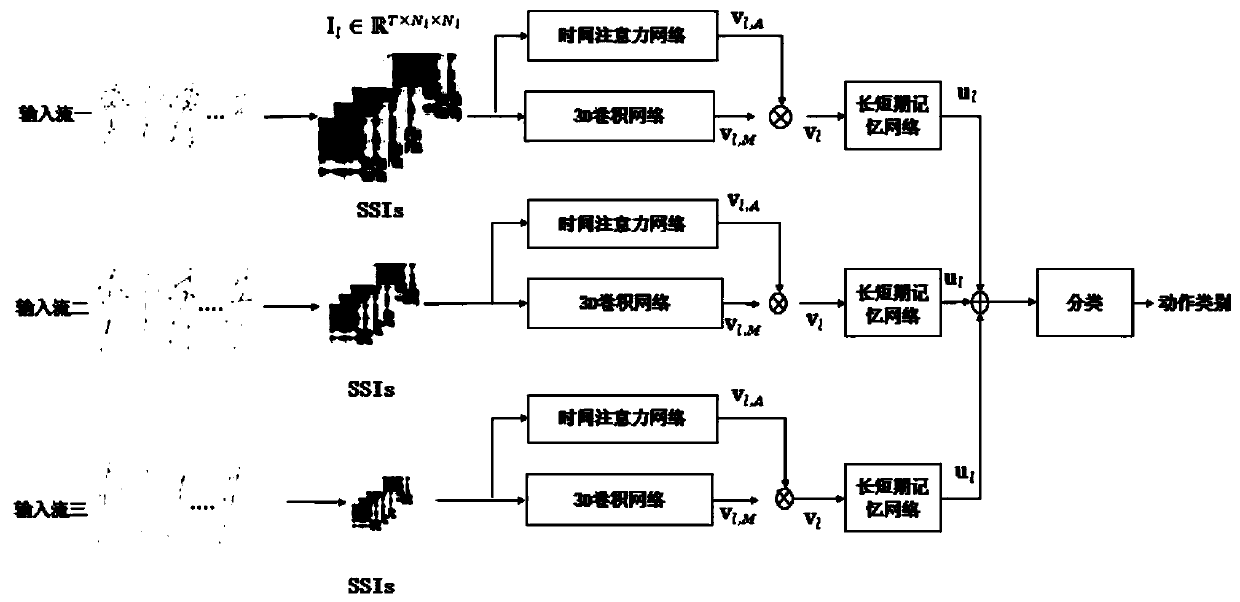
[0062] S5, a backbone network based on SCM and SEM, constructs a multi-stream neural network MSNN through multi-stream fusion.
[0063] The present invention considers that the use of skeleton information of different scales can effectively improve the recognition performance and deal with the occlusion situation well. Therefore, human skeletons at three scales are first acquired in a fine-to-coarse manner. On a finer scale, the corresponding human skeleton contains more joints; the proposal of the multi-scale SSI scheme makes the present invention more...
Embodiment 2
[0097] This embodiment proposes a cross-view action recognition method based on skeleton self-similarity. Compared with step S5 in Embodiment 1, the early fusion is replaced by late fusion. Refer to Figure 6 , step S5 specifically includes the following steps:
[0098] Using SCM and SEM as the backbone of building a multi-stream neural network MSNN, such as figure 1 shown. Among them, SCM is used to extract the spatio-temporal features of SSI images; the spatio-temporal features are further input into SEM to model the temporal dependencies between action sequences. Finally, action representations are learned from SSI images of different scales by fusing the three backbone networks to form a multi-stream neural network. Based on this backbone structure, the later fusion is to directly form an action combination representation U by concatenating the SEM output features of multiple streams;
Embodiment 3
[0100] For Examples 1 and 2, a batch normalization BN layer is added after U to eliminate the covariate shift in U; finally, the normalized U is input to the SoftMax classifier, and according to the given U, The predicted probability of belonging to the i-th category is,
[0101]
[0102] in, Indicates the probability that U is the i-th category, where w s,i (w s,i ) represents the weight matrix W in the SoftMax layer s The i-th row (j-th column) of , C represents the total number of classes;
[0103] Express the final optimization objective function of MSNN as a cross-entropy loss function L with L2 norm regularization:
[0104]
[0105] where y=(y 1 ,y 2 ,...,y C ) is the ground truth label, Indicates the predicted probability that the sequence U belongs to the i-th action category; W indicates the global matrix of network weights, here merged into one matrix; L2 regularization is applied to W to reduce network overfitting. scalar lambda 1 The role of is ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More