

Chinese text category recognition system and method for unbalanced data sampling
A data sampling and text technology, which is applied in text database clustering/classification, neural learning methods, electrical digital data processing, etc., can solve problems such as single use, feature loss, and low extraction granularity
Pending Publication Date: 2020-08-25
XI AN JIAOTONG UNIV
View PDF3 Cites 16 Cited by
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Among them, the undersampling method refers to screening some representative samples so that the positive and negative samples reach a proportional balance; however, the current two types of undersampling methods based on clustering and integration only consider the selection of important features, and feature loss exists to a certain extent. The risk, and the redundancy problem in the negative sample data also needs to be considered
Oversampling refers to generating new positive samples from a small number of existing positive samples through the model to balance the positive and negative samples in the data set; currently there are two types of methods: filter-based sample generation and limited sample space to generate data. When using space, the diversity of sample generation is more limited, so that the features cannot be evenly distributed in the sample space, and the filtering-based method is often not enough to construct a good sample due to the low granularity of feature extraction and single use of positive samples. Selector to select better samples to complement the data
In the process of mixed sampling, the relationship between positive and negative sample features is not fully utilized, and the undersampling and oversampling methods are simply stacked.
Method used
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
View moreImage
Smart Image Click on the blue labels to locate them in the text.
Smart ImageViewing Examples

Examples
Experimental program
Comparison scheme
Effect test
Embodiment
[0122] The present invention has carried out a large number of experiments on the Wenyin Internet competition data set held by AI100, and carried out comparative experiments with basic sampling methods such as random undersampling, random oversampling, etc., and improved models based on these models, confirming the advantages of the present invention The performance of the Chinese text category recognition method (MUDS) of unbalanced data sampling reaches optimal (experimental results as shown in Table 1); Show).
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More PUM
 Login to View More
Login to View More Abstract
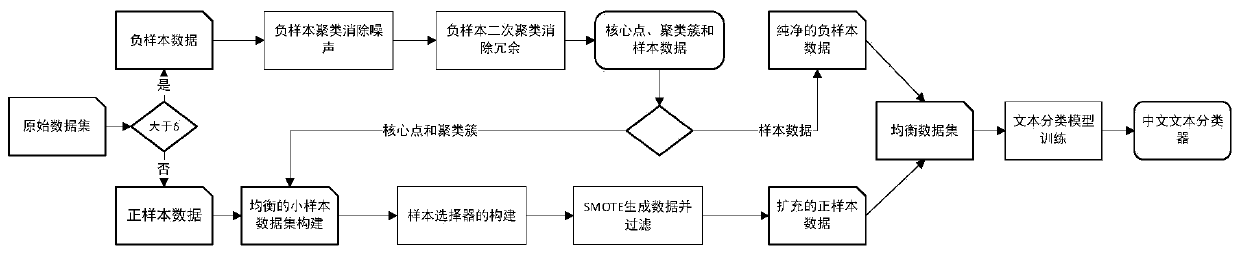
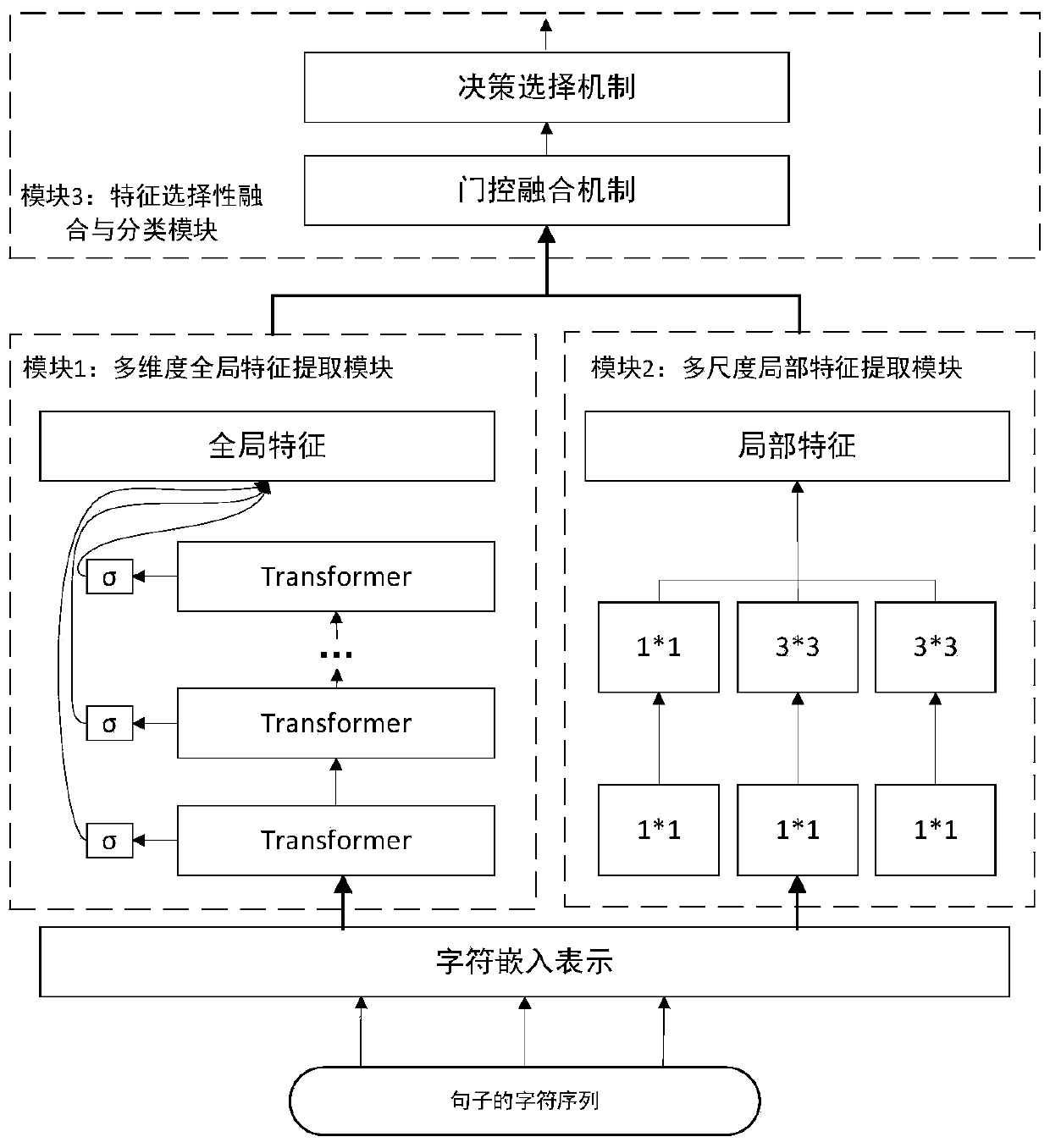
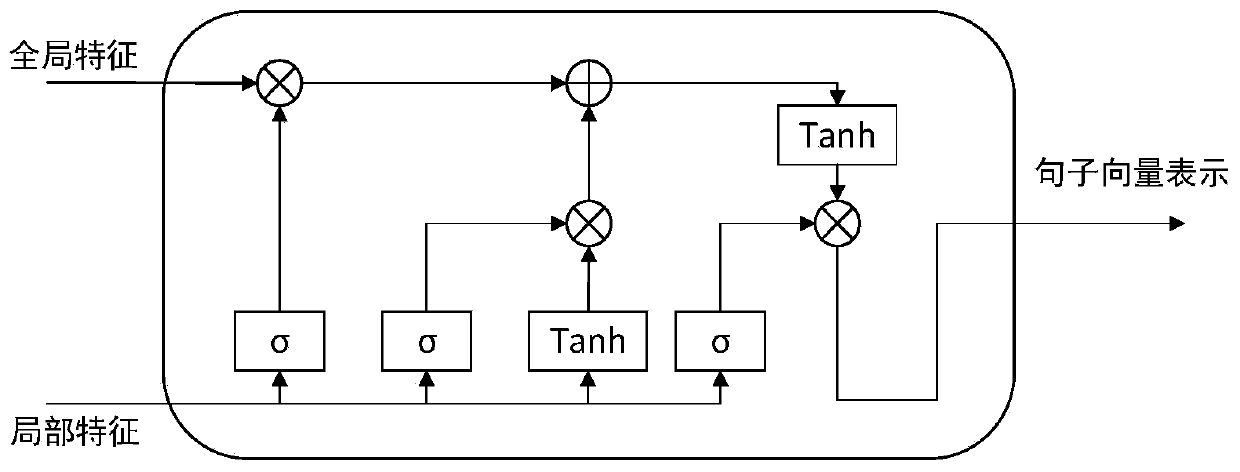
The invention discloses a Chinese text category recognition system and method for unbalanced data sampling. The method comprises the following steps: firstly employing a text encoder to encode a Chinese text, and forming sentence vector representation; secondly, redundant and noise data are removed by adopting a multi-time DBSCAN clustering algorithm for negative sample data, and a deep learning sample selector is constructed for positive sample data to filter samples and select high-quality sample data to supplement positive samples while the samples are randomly generated; and finally, decoding the selected sample data through a text decoder to form text data, and forming a balanced data set together with the processed negative sample data so as to be applied to a text classification model. According to the method, a mixed sampling method is adopted to process data, particularly redundant data processing is performed on negative samples, a deep learning sample selector is constructedfor positive samples to filter generated samples, a high-quality sample training classifier is selected, and the text classification performance is improved.
Description
【Technical field】 [0001] The invention belongs to the technical field of natural language processing, and relates to a method for unbalanced data processing and text classification, in particular to a Chinese text category recognition system and method for unbalanced data sampling. 【Background technique】 [0002] In recent years, the rapid development of science and technology has promoted the explosive growth of data in various fields. The phenomenon of the number of data categories and the uneven distribution of features exists in almost every practical data set in real life. It is of great significance to effectively classify unbalanced data in reality. For example, enterprises can use classified user review information for different departments to make targeted improvements to related products and services. Specifically, there are the following two states in the real unbalanced data: one is that the amount of negative sample data is large, and there are certain noise da...
Claims
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More Application Information
Patent Timeline
 Login to View More
Login to View More Patent Type & AuthorityApplications(China)
IPC IPC(8): G06F16/35G06F40/126G06F40/289G06F40/216G06N3/04G06N3/08
CPCG06F16/355G06F40/126G06F40/289G06F40/216G06N3/08G06N3/045Y02D10/00
Inventor饶元祁江楠贺龙贺王卜
OwnerXI AN JIAOTONG UNIV