

Semantic-based document clustering method and system and computer equipment
A document clustering and document technology, applied in the field of artificial intelligence, can solve the problem of low clustering accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
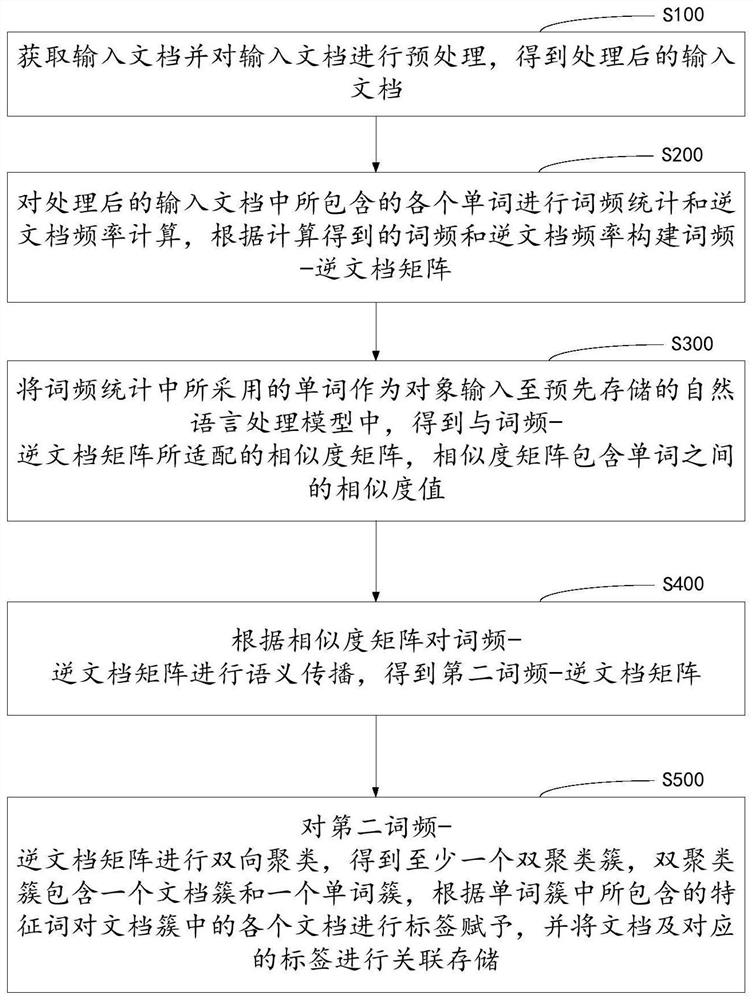
[0058] see figure 1 , shows a flow chart of steps of a semantic-based document clustering method according to an embodiment of the present invention. It can be understood that the flowchart in this method embodiment is not used to limit the sequence of execution steps.
[0059] details as follows:
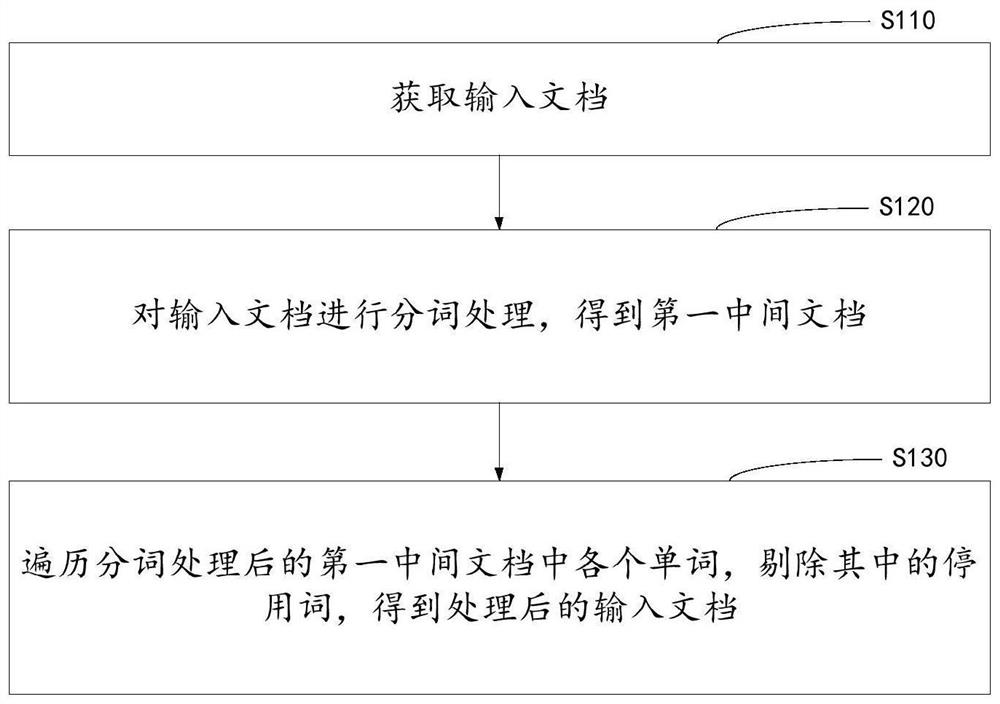
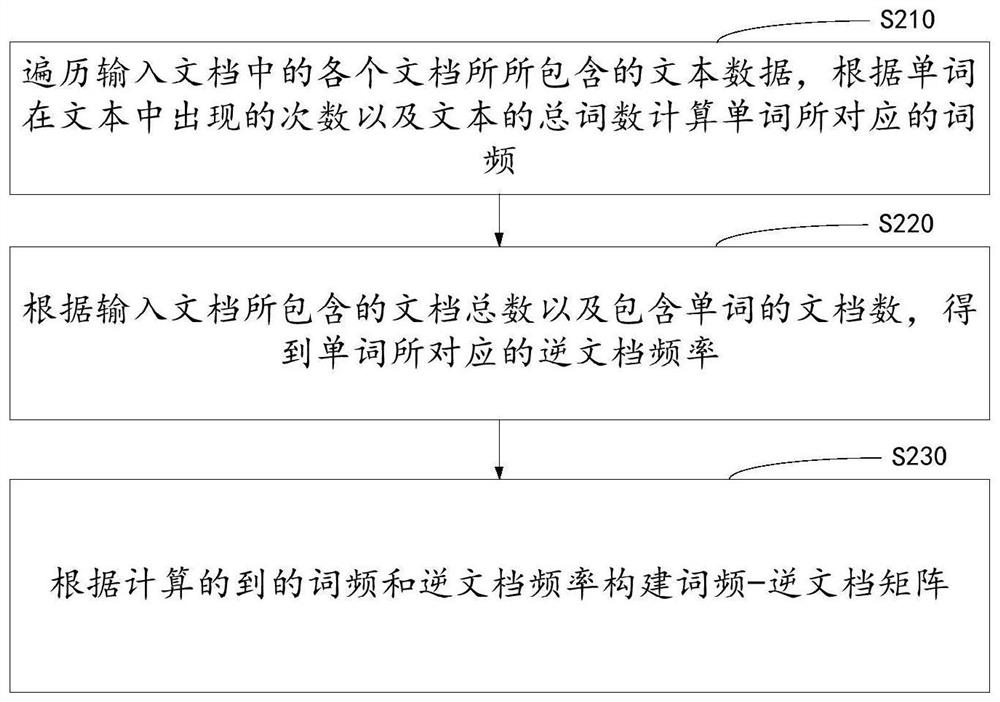
[0060] Step 100 obtains an input document and preprocesses the input document to obtain a processed input document;
[0061] Specifically, a document represents an article or a sentence or paragraph around a central meaning, and the input document can be one document or multiple documents.
[0062] The processor pulls the input document along the preset path information, or it can set a cache area, the server puts the newly uploaded document into the cache area, and the processor in the server periodically extracts the cache area according to the set pull frequency All the documents in the document are used as input documents to perform a series of preprocessing to complete the ...
Embodiment 2
[0165] see Figure 6 , shows a schematic diagram of program modules of the semantic-based document clustering system of the present invention.
[0166] In this embodiment, the semantic-based document clustering system 20 may include or be divided into one or more program modules, and one or more program modules are stored in a storage medium and executed by one or more processors , to complete the present invention, and realize the above-mentioned semantic-based document clustering method. The program module referred to in the embodiment of the present invention refers to a series of computer program instruction segments capable of completing specific functions, which is more suitable for describing the execution process of the semantic-based document clustering system 20 in the storage medium than the program itself. The following description will specifically introduce the functions of each program module of the present embodiment:
[0167] The preprocessing module 200 is ...
Embodiment 3
[0177] refer to Figure 7 , is a schematic diagram of the hardware architecture of the computer device according to Embodiment 3 of the present invention. In this embodiment, the computer device 2 is a device that can automatically perform numerical calculation and / or information processing according to preset or stored instructions. The computer device 2 may be a personal digital assistant (Personal Digital Assistant, PDA), a smart phone, a notebook computer, a netbook, a personal computer and other similar devices. As shown in the figure, the computer device 2 at least includes, but is not limited to, a memory 21, a processor 22, a network interface 23, and a semantic-based document clustering system 20 that can communicate with each other through a system bus. in:
[0178] In this embodiment, the memory 21 includes at least one type of computer-readable storage medium, and the readable storage medium includes flash memory, hard disk, multimedia card, card-type memory (for...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More