

Semantic-based audio-driven digital human generation method and system
An audio-driven and semantic technology, applied in the field of machine learning, can solve the problems of large limitations, errors in the positioning of facial feature points, and the lack of consideration of individual speech differences, etc., to achieve the effect of improving viewing experience
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
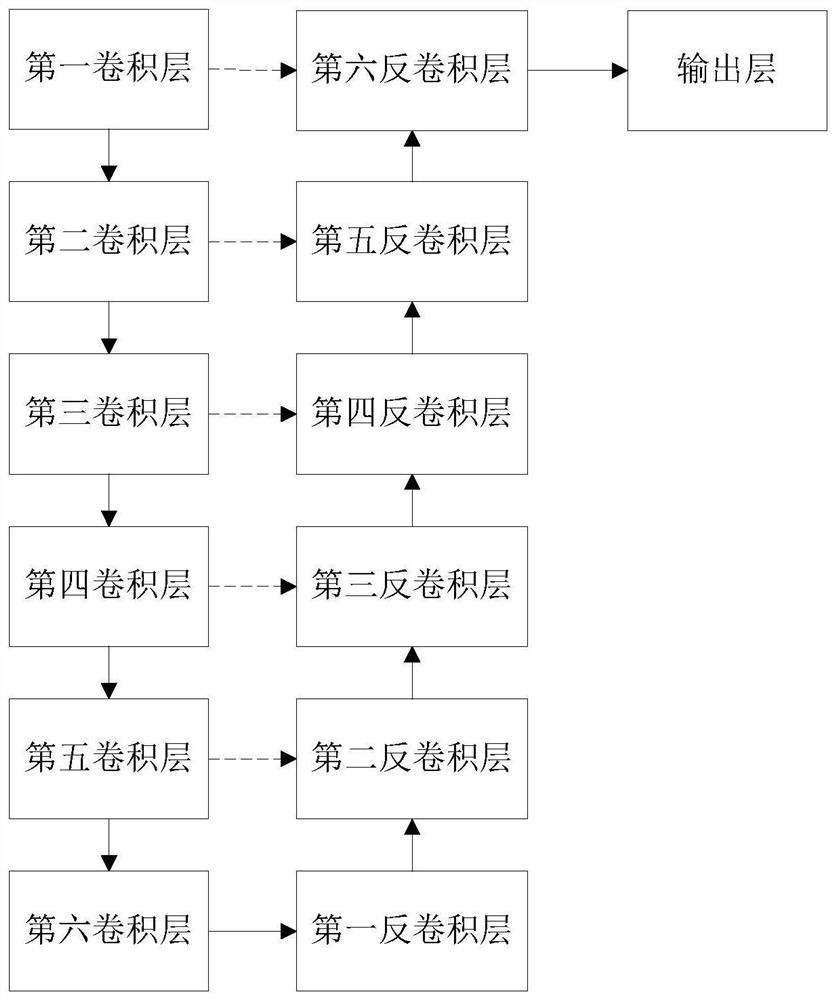
[0050] Embodiment 1. A semantic-based audio-driven digital human generation method, such as figure 1 shown, including the following steps:
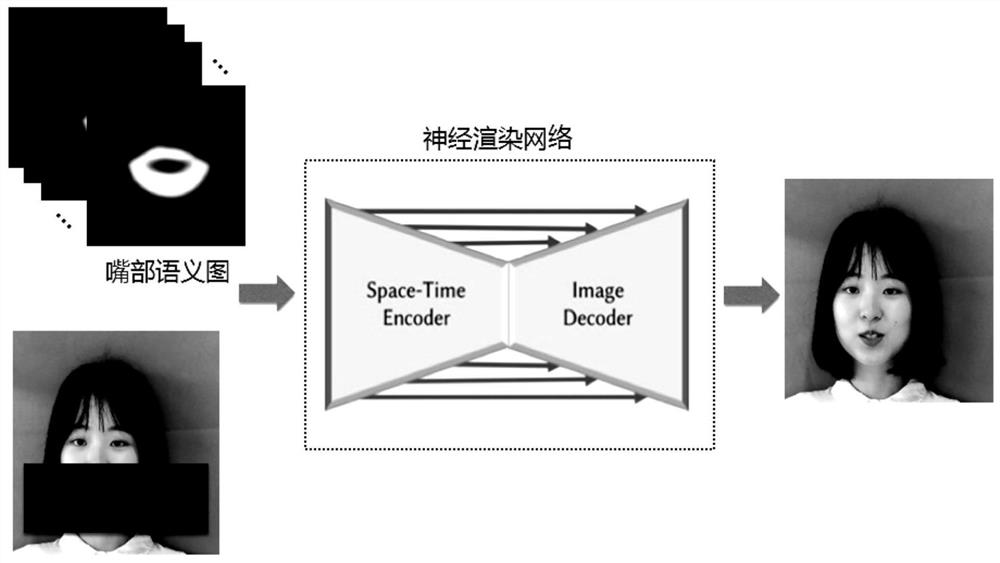
[0051] S100. Obtain a target audio and target face image sequence, and perform mask processing on the mouth area of each target face image in the target face image sequence to obtain a corresponding first face image sequence;
[0052] After the mouth area of the target face image is masked, the corresponding face images to be rendered are obtained, and the face images to be rendered corresponding to each target face image one-to-one constitute a first face image sequence.
[0053] S200. Perform feature extraction on the target audio to obtain corresponding audio features;
[0054] S300. Input the audio features into a pre-trained semantic conversion network, and perform semantic conversion on the audio features by the semantic conversion network to obtain a corresponding semantic motion sequence, the semantic motion sequence includi...
Embodiment 2
[0116] Embodiment 2, a kind of audio-driven digital human generation system based on semantics, such as Figure 4 shown, including:
[0117] The data acquisition module 100 is used to obtain the target audio and the target face image sequence, and after masking the mouth area of each target face image in the target face image sequence, obtain the corresponding first face image sequence ;
[0118] The feature extraction module 200 is used to perform feature extraction on the target audio to obtain corresponding audio features;
[0119] The semantic conversion module 300 is used to input the audio features into a pre-trained semantic conversion network, and the semantic conversion network performs semantic conversion on the audio features to obtain a corresponding semantic motion sequence, the semantic motion sequence includes several a mouth semantic map;
[0120] The composite rendering module 400 is configured to construct a second human face image sequence based on the ...
Embodiment 3
[0128] Embodiment 3. A computer-readable storage medium stores a computer program, and when the program is executed by a processor, the steps of the method described in Embodiment 1 are implemented.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More