

False information early detection method based on text structure algorithm
A technology of false information and text structure, applied in the field of false information detection based on text structure algorithm, can solve the problem of ignoring the advanced text structure of documents and effective modeling of key context information, consuming a lot of time and human resources, and increasing the difficulty of false information detection tasks and workload issues, to achieve the effect of safety and reliability, not easy to detect and fight, and facilitate the difficulty of data collection
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
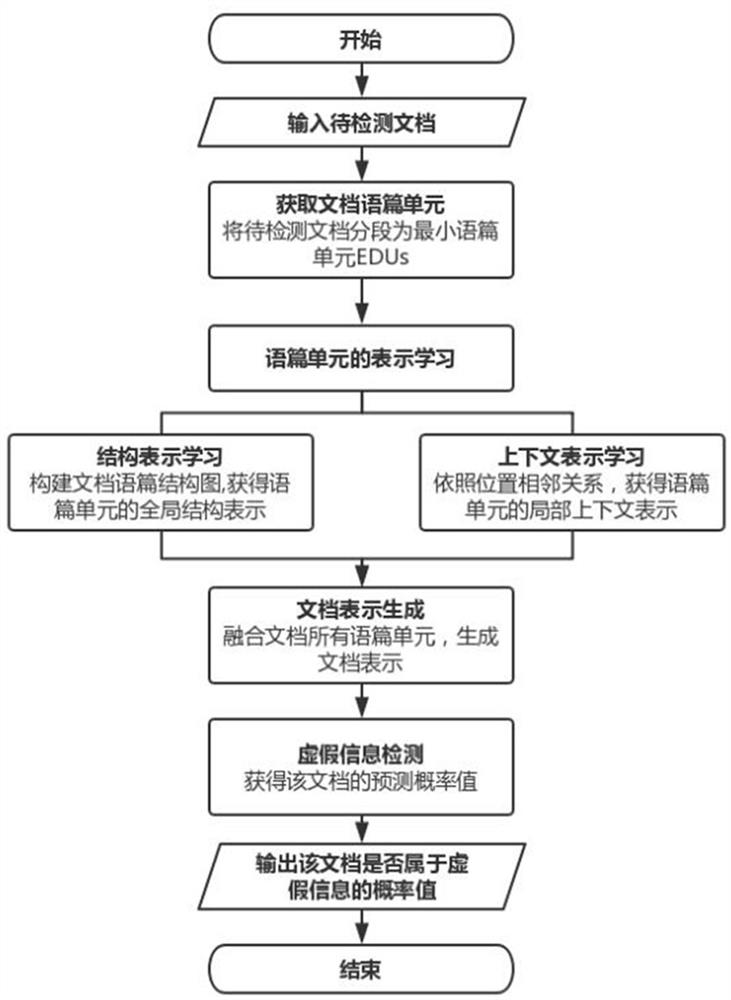
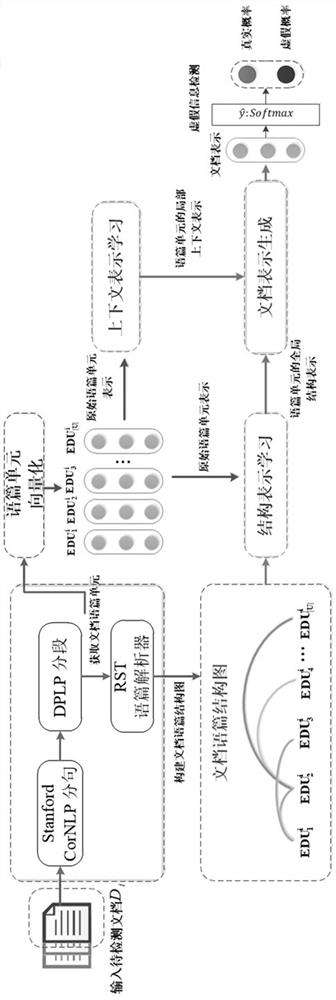
[0067] like figure 1 and figure 2 As shown, since the purpose of the present invention is to detect the true or false situation of information, the specific task target can be summarized as a binary classification problem of whether the document to be detected is classified as false information, and the embodiments of the present invention are as follows:
[0068] Establish calculation module 1, which is used to obtain the textual unit of the document. This module divides the document to be detected into segments to obtain its smallest textual unit.
[0069] The present invention takes the discourse unit as the calculation object, and abandons the problems generated in the model learning process with words or sentences as the object, so the design scheme is used to obtain the smallest discourse unit at first. The smallest discourse unit (EDU: Elementary DiscourseUnit) is the basic language unit of a document, generally expressed as a clause, and the shortest can be a phrase....
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More