

Cross-modal image text retrieval method of hybrid fusion model
A fusion model and image fusion technology, applied in the field of cross-modal retrieval, can solve problems such as roughness, insufficient cross-modal learning, and general performance, so as to improve accuracy, promote cross-modal information exchange, and enhance expression ability Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
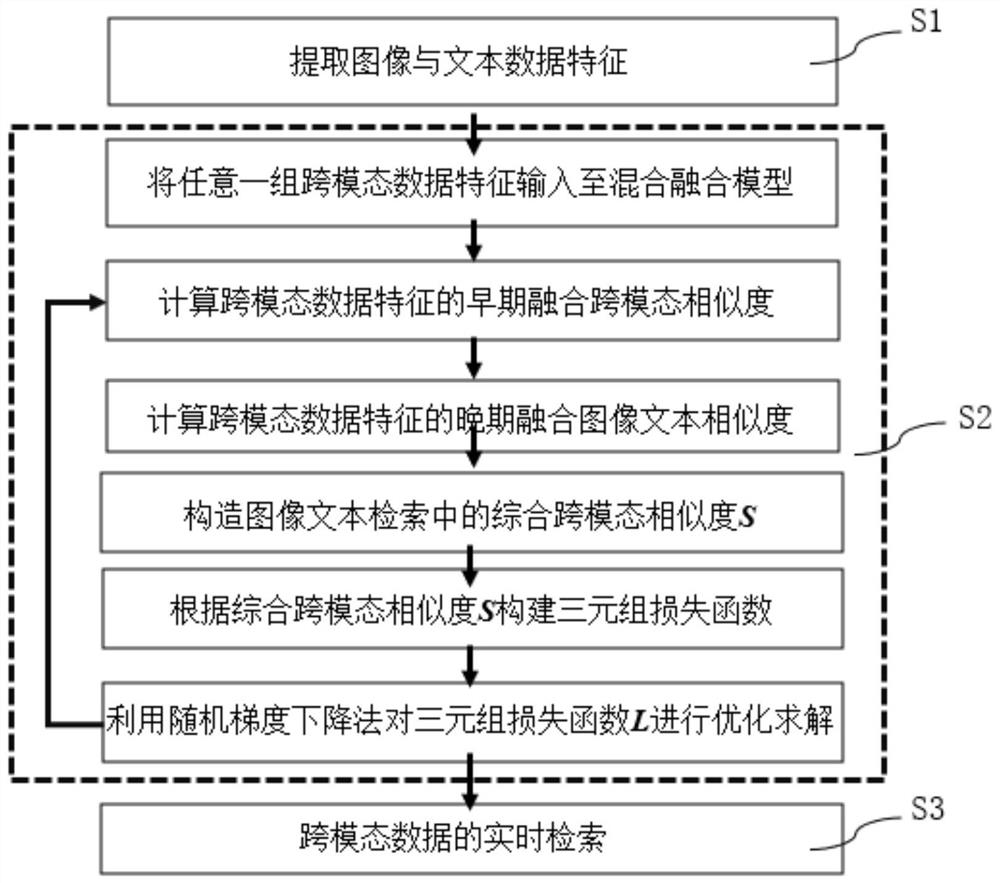
[0054] figure 1 It is a flowchart of a cross-modal image text retrieval method of a hybrid fusion model of the present invention.
[0055] In this example, if figure 1 As shown, a cross-modal image text retrieval method of a hybrid fusion model of the present invention comprises the following steps:
[0056] S1. Extracting cross-modal data features;
[0057] S1.1. Download cross-modal image-text pair data including N groups of images and their corresponding descriptive texts;
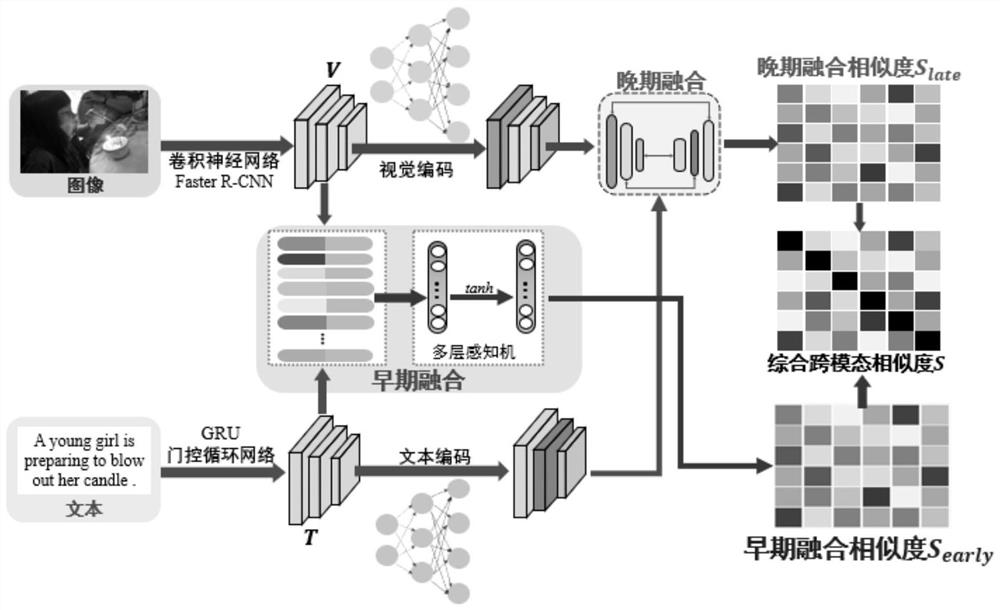
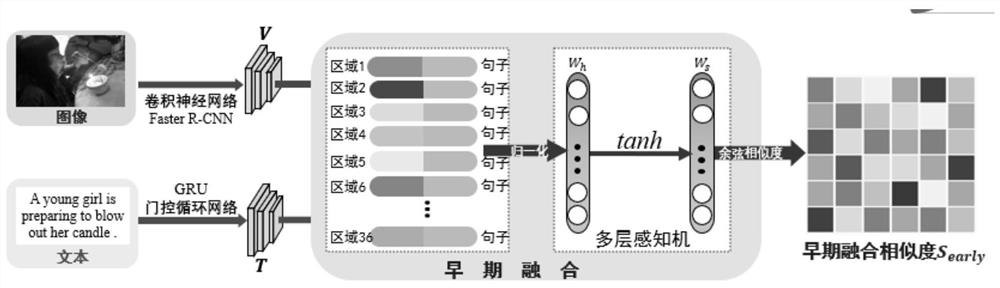
[0058] S1.2. In each set of cross-modal image-text pair data, use the region-based convolutional neural network FasterR-CNN to extract the image region feature set V={v i}, where v i Represent the i-th image region feature, i=1,2,...,k, k represents the number of elements in the image region feature set, and k is taken as 36 in the present embodiment; Utilize the text word feature based on the gated recurrent unit GRU Set T = {t j}, where t j Represent the jth text word feature, j=1,2,...,l, l is...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More