Data management method and system based on data consanguinity analysis
A blood relationship and data technology, applied in the field of data processing, can solve the problems of difficulty in data traceability, verification, and correlation analysis, and achieve the effect of improving data governance efficiency and facilitating data analysis and utilization.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
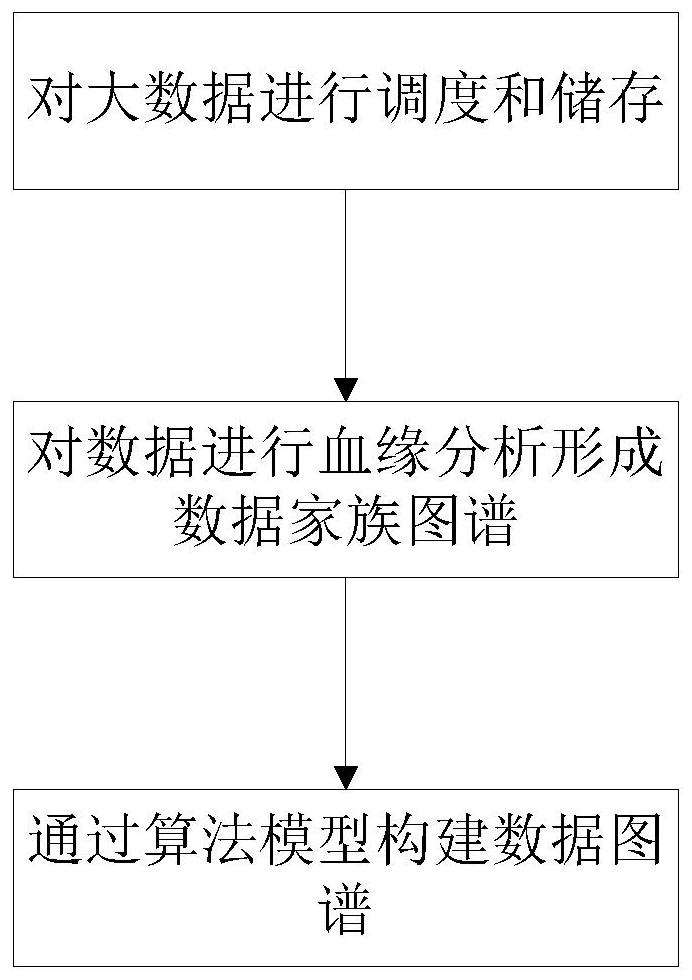
[0062]Appendfigure 1 As shown, the present invention is based on the data control method of data-based blood analysis. The method is to analyze the data family relationship mesh map, and confirm each other's data in the mesh spectrum, which helps data governance to complete Trace data, verify, supplement, and standardize data, improve data management efficiency; specifically as follows:
[0063]S1, scheduling and storing big data;
[0064]S2, the data is performed to form a data family map;
[0065]S3, construct a data map through an algorithm model.
[0066]In this embodiment, the maximum data of S1 is scheduled and stored as follows:
[0067]S101, the relevant data resource is scheduled to the database of the HBASE through NIFI data scheduler;
[0068]S102, during the scheduling process, standardize the field name, cleaning the key field, convenient for blood analysis.
[0069]In this embodiment, the data family map is made in this embodiment, and the data family is specifically as follows:
[0070]S201,...
Embodiment 2
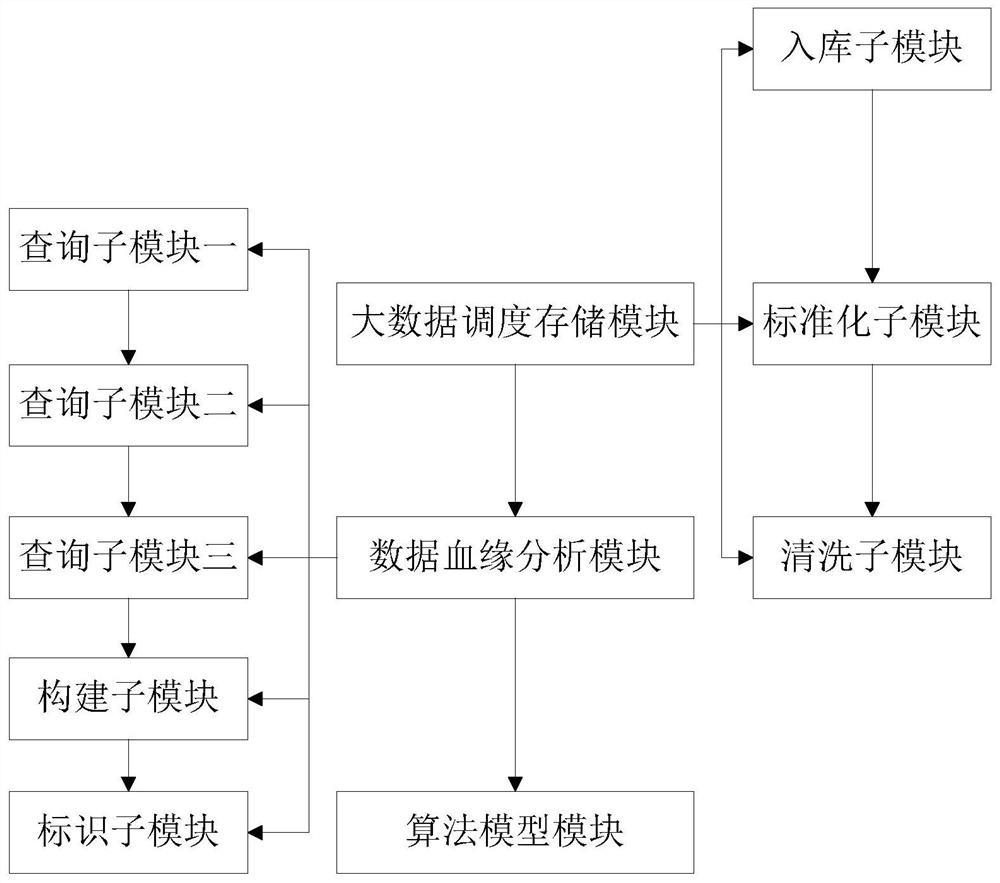
[0090]Appendfigure 2As shown, a data governance system based on a data-based blood analysis, including a large data scheduling storage module for scheduling storage;
[0091]Data blood analysis module, used to analyze the data relationship, generate data family maps;
[0092]The algorithm model module is used to automatically analyze the data-related relationship to form a data map through each node key field index, and is also used to manage data quality and analyze data relationships, extract data value.
[0093]The large data scheduling storage modules in this embodiment include,
[0094]The library module is used to schedule the data;
[0095]Standardized submodules for normalization of data fields during scheduling;
[0096]Cleaning the child module for cleaning the key field.
[0097]The data blood analysis module in this embodiment includes,
[0098]Quroom submodule 1. Used to query master data nodes;
[0099]Subsequent submodulation 2 for querying data flow nodes;
[0100]The query submodule is used to q...
Embodiment 3
[0104]The embodiment of the present invention also provides a computer readable storage medium in which a plurality of instructions are stored, and the instruction is loaded by a processor, and the processor performs a data governance method based on data-based blood analysis based in either embodiment of the present invention. Specifically, a system or apparatus equipped with a storage medium can be provided, and a software program code that implements a function of any of the embodiments in the above embodiment, and a computer (or CPU or MPU) of the system or device (or MPU) ) Read and execute program code stored in the storage medium.
PUM
 Login to view more
Login to view more Abstract
Description
Claims
Application Information
 Login to view more
Login to view more - R&D Engineer
- R&D Manager
- IP Professional
- Industry Leading Data Capabilities
- Powerful AI technology
- Patent DNA Extraction
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic.
© 2024 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap