Front-end text analysis method based on multi-task learning
A multi-task learning and text analysis technology, applied in the field of speech synthesis, can solve problems such as the complexity of the training process, and achieve the effects of simplifying the training process, reducing workload, and reducing computing resources
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
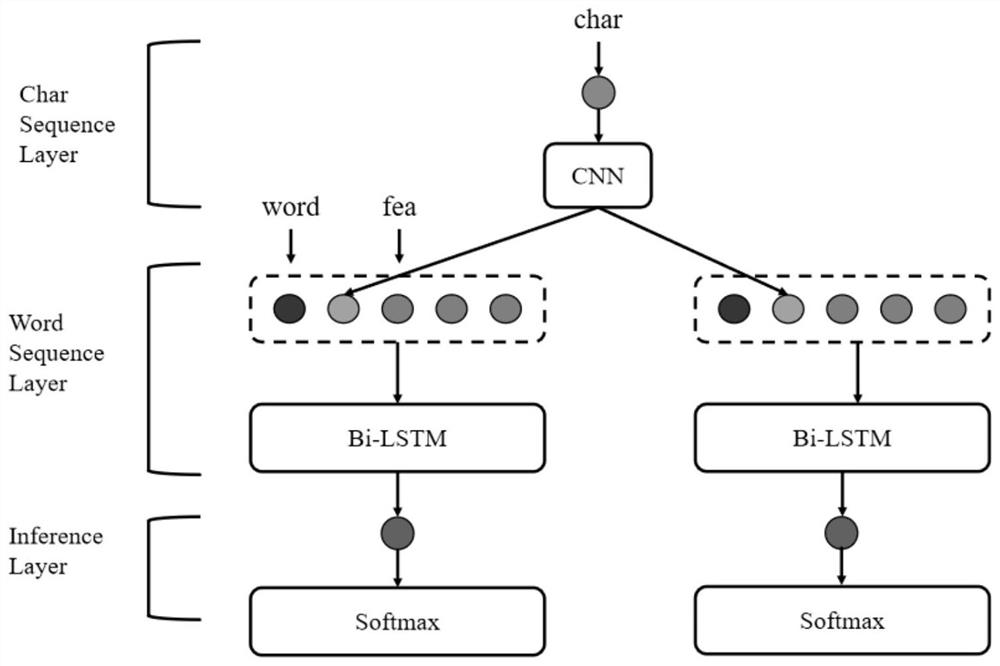
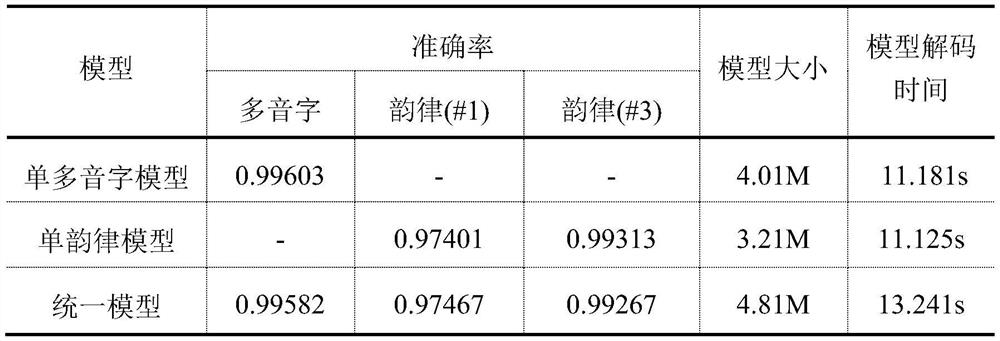
[0049] In order to verify the present invention, verification is performed on a self-built database. In this dataset, the training set contains 971,500 sentences, the test set and validation set are 3,000 sentences, the polyphonic word dictionary contains 312, and the prosody contains #1 and #3. The algorithm flow of the whole system is as follows figure 1 shown, the following combined with the appendix figure 1 The present invention is described in further detail.
[0050] figure 1 It is the model frame diagram of the front-end text analysis method based on multi-task learning of the present invention. like figure 1 It mainly includes the following steps:
[0051] S1. Data annotation:
[0052] First perform data processing: segment each sentence in the corpus by word, and filter out sentences with a length of more than 250;
[0053] Then manually perform data labeling on the same source corpus, and splicing the polyphonic label and prosodic label corresponding to each ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More