Method for solving cache failure of mass data distributed index cluster
A massive data, distributed technology, applied in the direction of digital data information retrieval, electronic digital data processing, special data processing applications, etc., can solve the problems of massive data distributed index cluster cache failure, to improve the cluster query speed, solve the system Cache invalidation, the effect of saving cluster resources
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

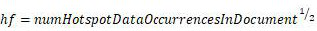
Examples
Embodiment Construction
[0050] In order to make the objectives, technical solutions and advantages of the present invention clearer, the present invention will be further described in detail below with reference to the accompanying drawings and embodiments. It should be understood that the specific embodiments described herein are only used to explain the present invention, but not to limit the present invention.
[0051] The specific implementation of the present invention will be described in detail below with reference to specific embodiments.
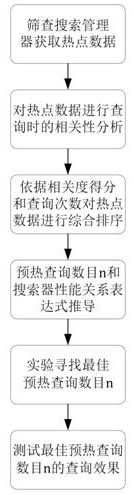
[0052] like Figure 1-2 As shown, a method for solving the cache invalidation of massive data distributed index cluster provided by an embodiment of the present invention includes the following steps:
[0053] Step 1: Screen the search manager to filter out the hotspot data;
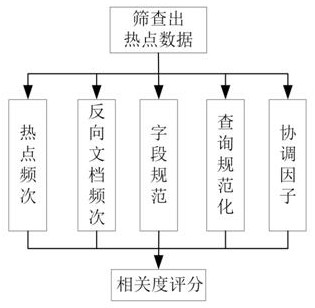
[0054] Step 2: Perform a correlation analysis of the selected hotspot data, and conduct a comprehensive ranking according to the correlation and the number of searches;
[0055] S...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com