

System and method for cluster fault toleration
A cluster and operating system technology, applied in the direction of response to error generation, error detection/correction, redundant data error detection in calculations, etc., can solve checkpoint operation failure, system reliability decline, cluster system components Increased number and other issues to achieve good scalability
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

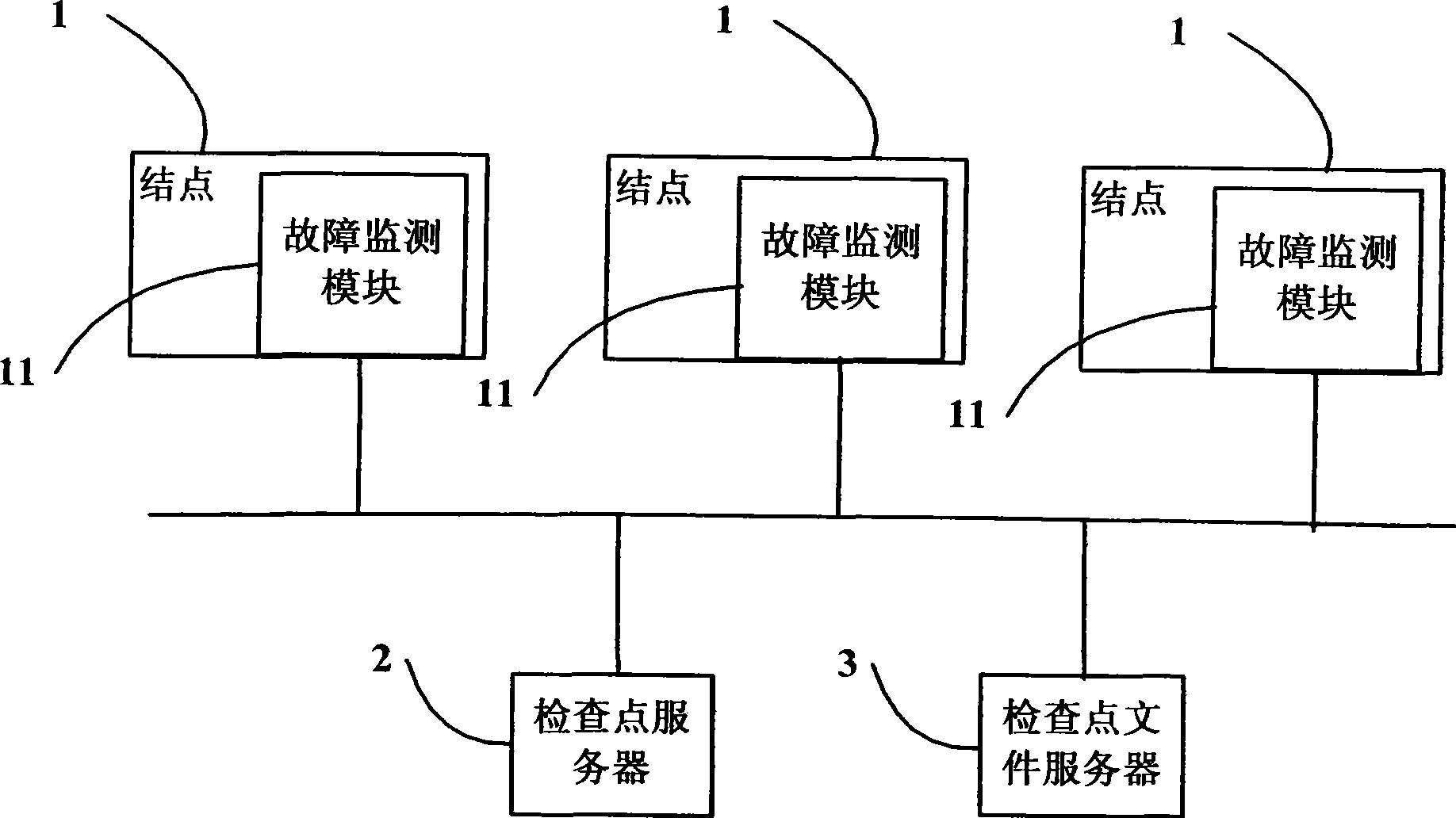
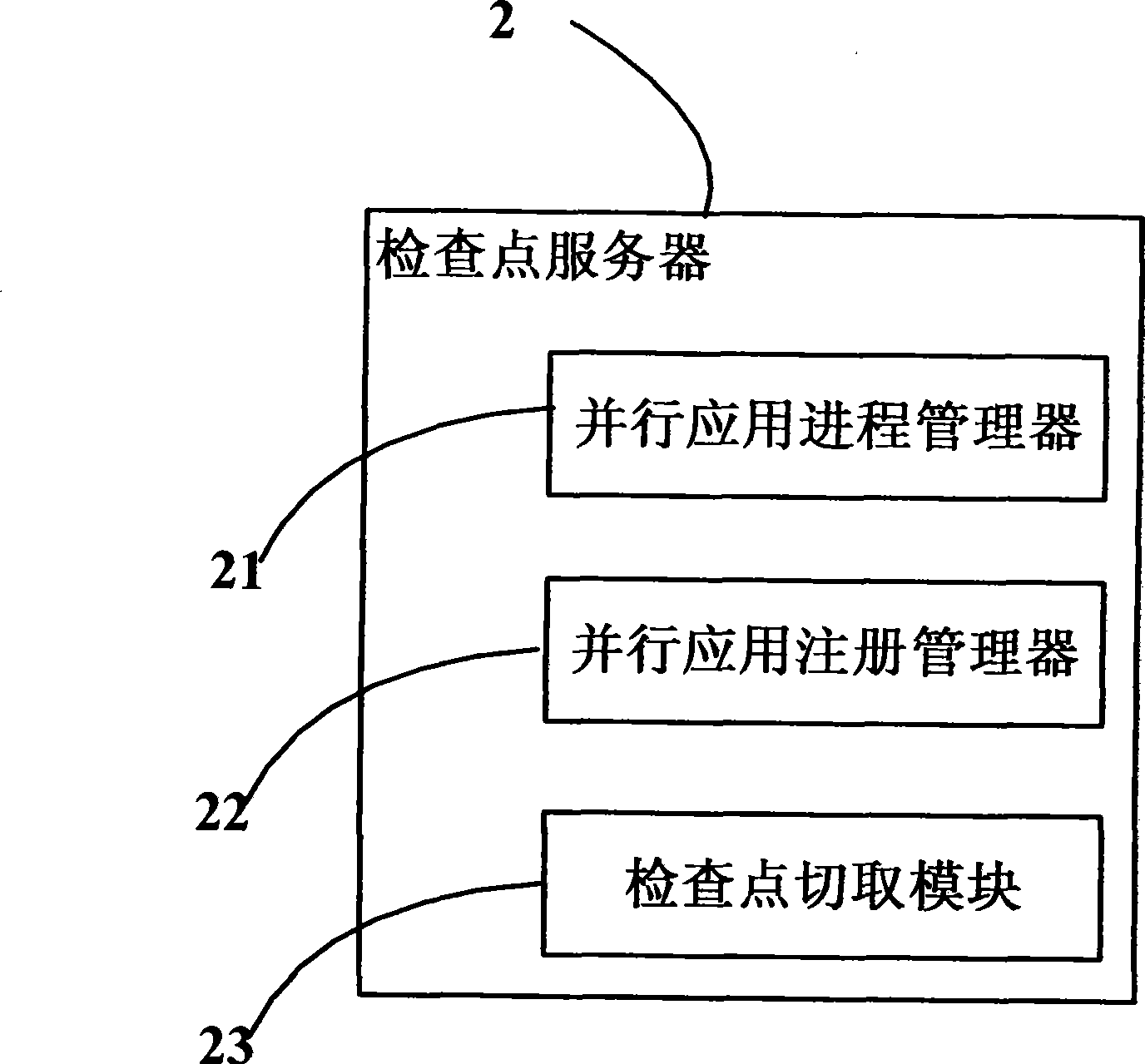
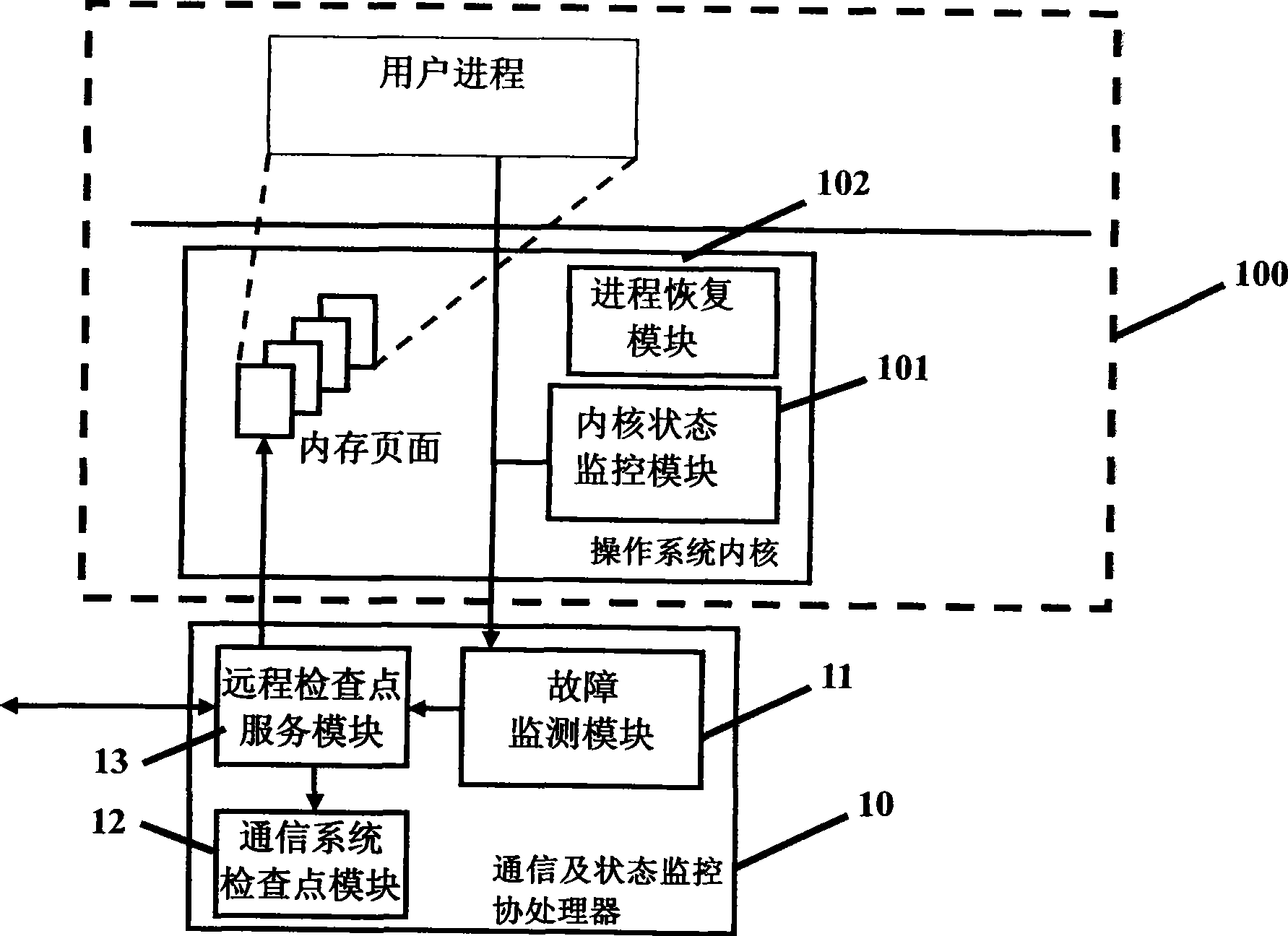
Examples
specific Embodiment approach
[0100] As a specific implementation, the method for monitoring faults described herein includes:
[0101] (1) Judging the failure of the operating system according to the clock interruption count; when the clock interruption count does not increase within a predetermined time, it is judged as the failure of the operating system.
[0102] For common general-purpose operating systems such as Unix and Linux, operating system functions such as process scheduling, system resource monitoring, and system time maintenance all depend on clock interrupts. The frequency of the clock interrupt is generally set at 100 to 1000 times per second. Each operating system uses a specific variable as the count of clock interrupts processed. If the clock interrupt count variable does not increase within a specified period of time, such as 0.05 seconds, it can be determined that the operating system is seriously malfunctioning.
[0103] (2) According to the failure of calling the internal interfac...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More