

Speaker recognition method based on semantic cell mixing model
A speaker recognition and hybrid model technology, applied in speech analysis, instruments, etc., can solve problems such as limited accuracy and poor pertinence
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

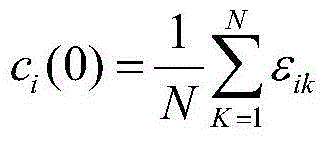
Examples
Embodiment Construction
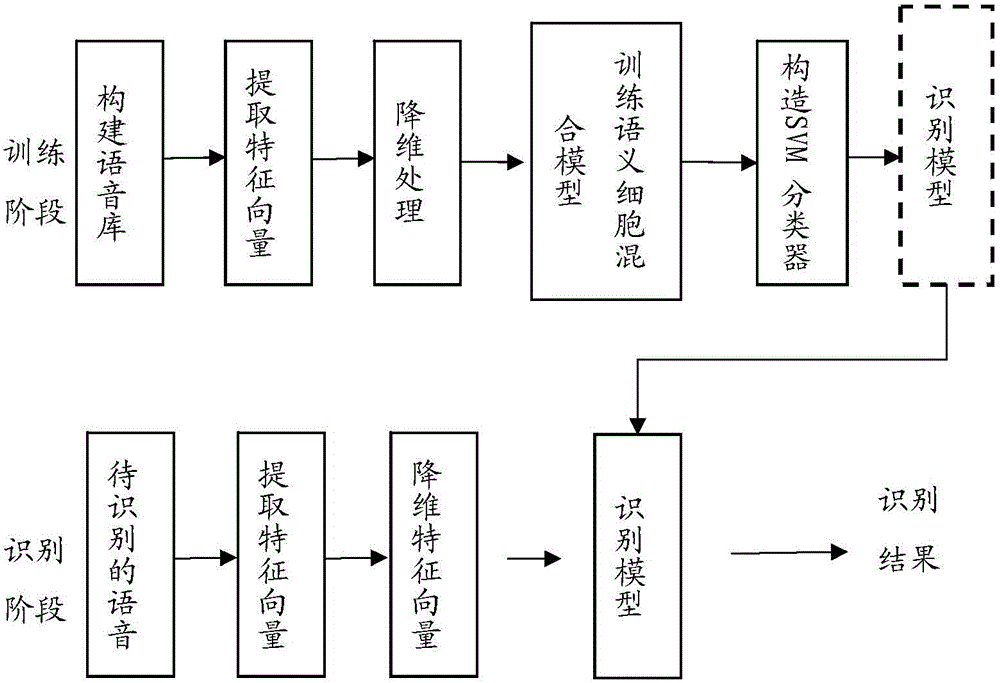
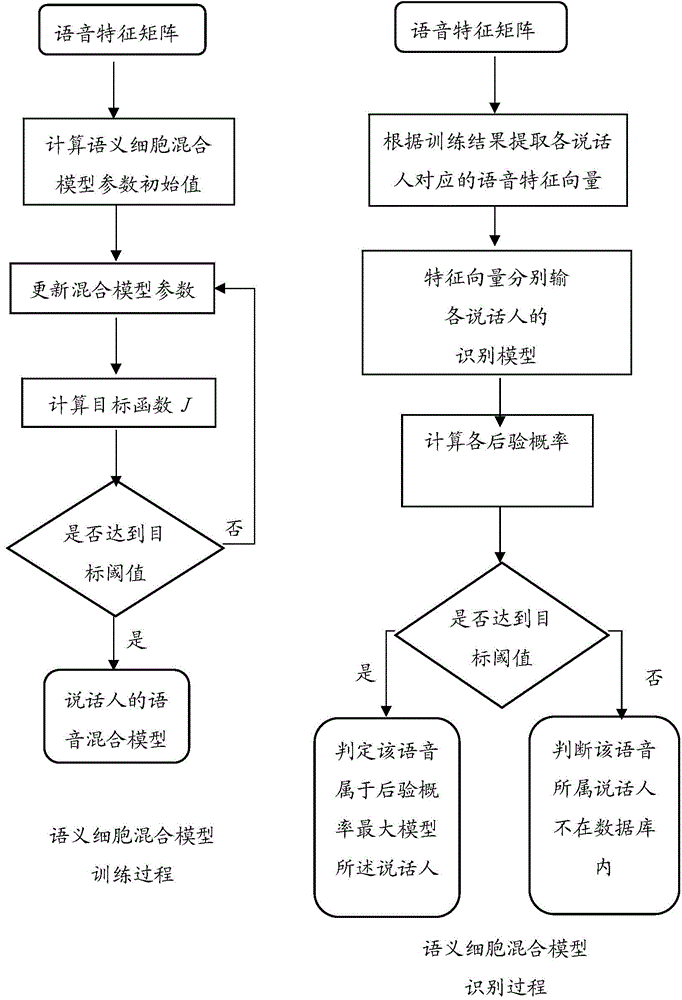
[0094] Combine below figure 1 and 2 The present invention is further described. The implementation method of the present invention comprises five steps.
[0095] Step (1) Constructing the speech library: the input speech signal must contain the identifier of the speaker, such as name.
[0096] The speech database constructed in this embodiment includes 138 speakers (106 males and 32 females), each with 10 speeches, and a total of 1380 speech data.
[0097] The preprocessing in step (2) includes pre-emphasis, framing and windowing. For the specific process, please refer to the patent application with publication number CN104200814A.
[0098] (2-1) The power spectrum of the speech signal decreases with the increase of frequency, and most of its energy is concentrated in the low frequency range. As a result, the signal-to-noise ratio at the high-frequency end of the speech signal may drop to an unacceptable level. However, because the energy of the higher frequency component...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More