

Text-independent voiceprint recognition method
A voiceprint recognition, text-independent technology, applied in voice analysis, instruments, etc., can solve the difficulties, limitations, and impossibility of fully connected neural networks, etc., to reduce the number of parameters and improve robustness Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

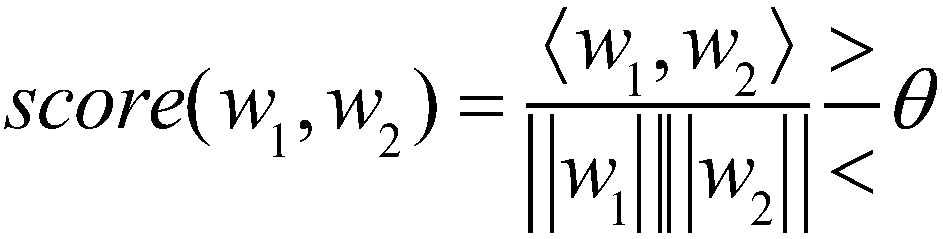
Examples
Embodiment Construction
[0036] The present invention will be further described below in conjunction with specific examples.
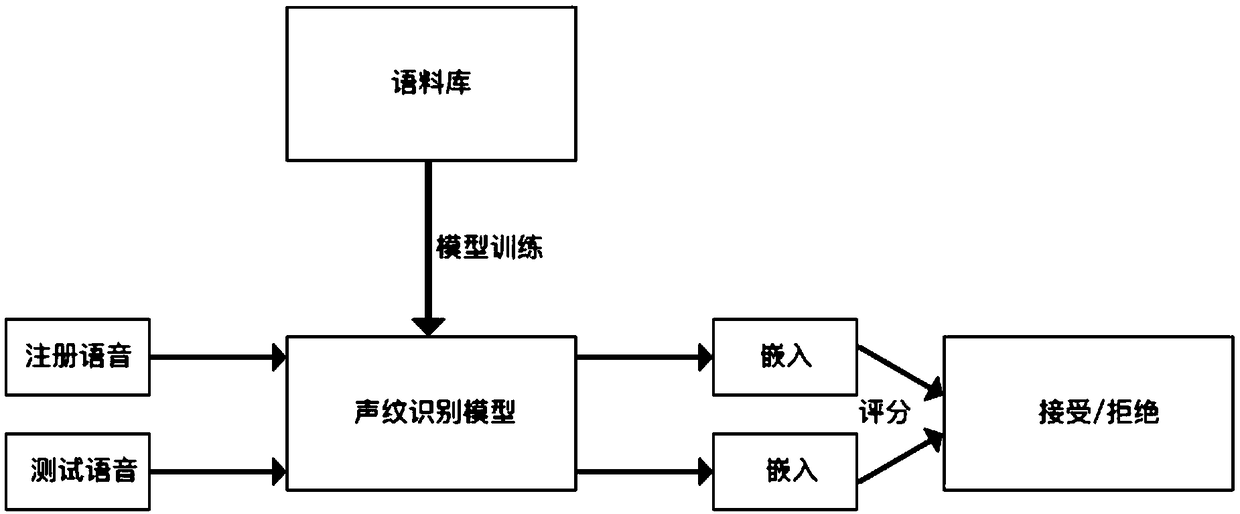
[0037] Such as figure 1 As shown, the text-independent voiceprint recognition method provided in this embodiment is divided into three stages: voiceprint recognition model training, extraction and embedding, and decision scoring.
[0038] First, train the voiceprint recognition model and select a suitable corpus, such as using the AISHELL-ASR0009-OS1 open source Chinese speech database, which includes a training library and a testing library.
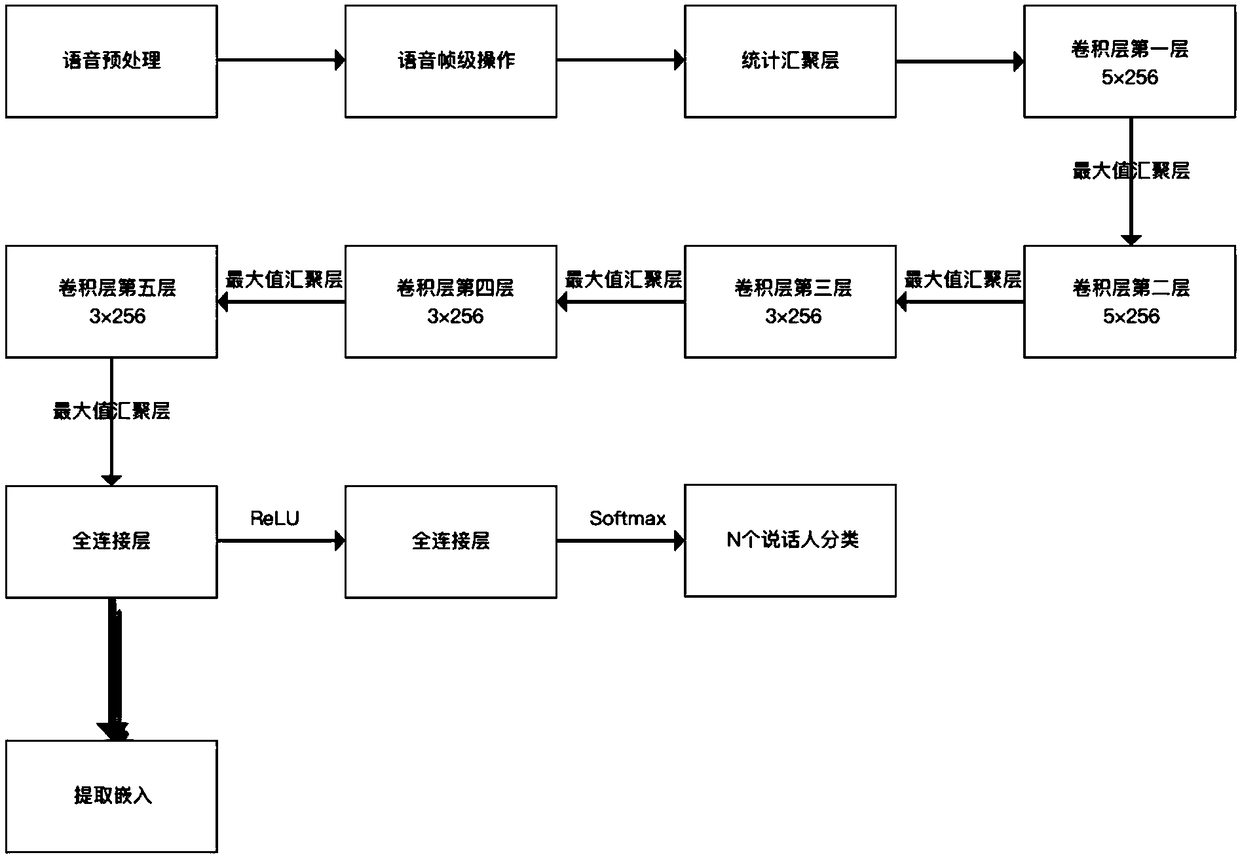
[0039] Such as figure 2 As shown, the voiceprint recognition model training steps are as follows:
[0040] 1) Speech signal preprocessing
[0041] Each segment of speech in the corpus is divided into 25ms frames, and speech activity detection is performed to identify and eliminate long periods of silence from the sound signal stream, generate 20-dimensional Mel spectrum cepstrum coefficient MFCC, and add first-order and second-order...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More