Method and system for eliminating duplication during data count as well as server and storage medium
A data counting and data storage technology, applied in the field of big data, can solve the problems of low accuracy rate, achieve the effect of improving accuracy, improving the efficiency of duplication check, and reducing the probability of data manslaughter
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
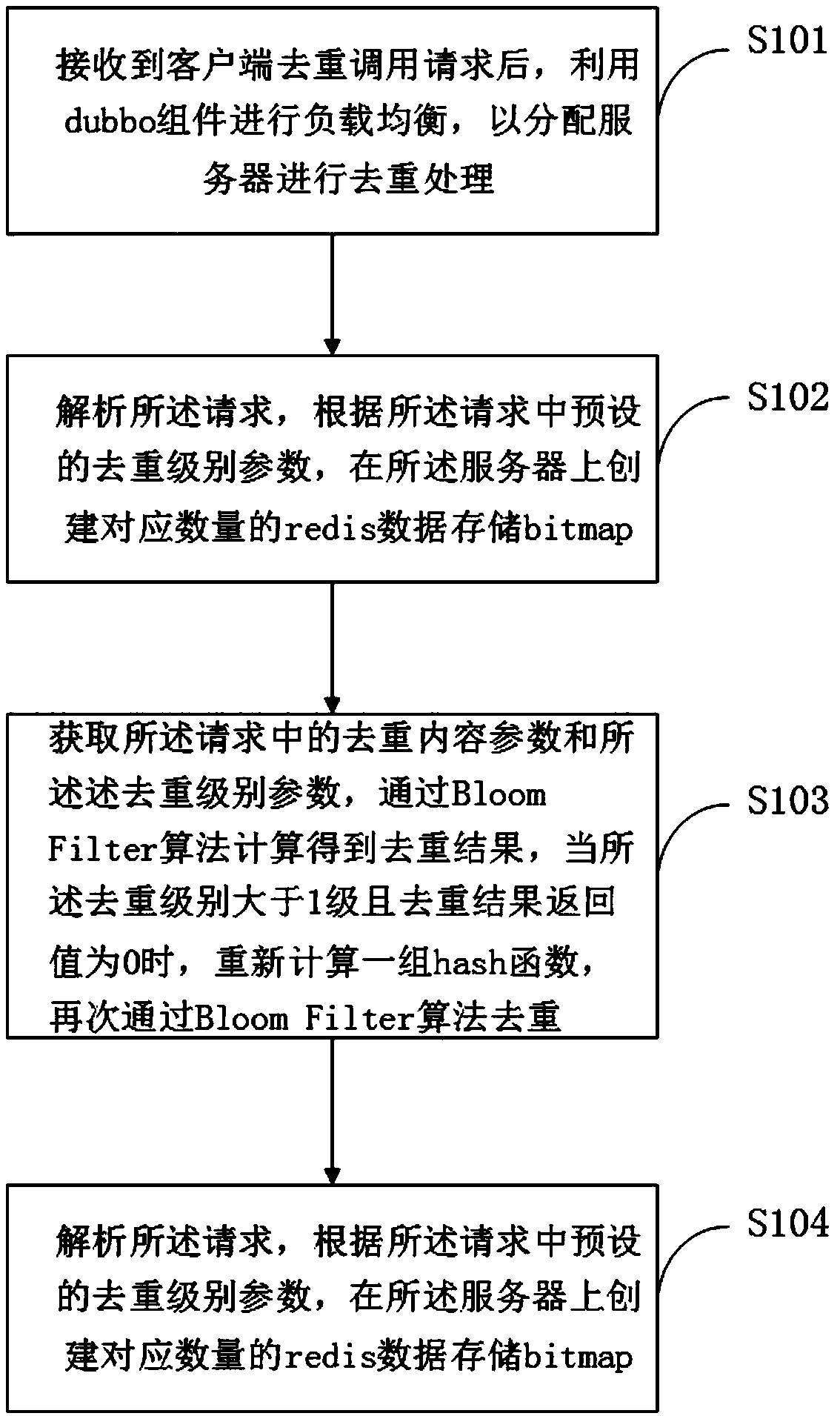
[0028] see figure 1 , a schematic flowchart of a data counting and deduplication method provided by an embodiment of the present invention, including the following steps:
[0029] S101. After receiving the deduplication call request from the client, use the dubbo component to perform load balancing, so as to assign servers to perform deduplication processing.
[0030] The client can provide a local service for the user, and can request a deduplication service from the server. The client may refer to a deduplication request program on the client computer, capable of invoking a deduplication component on the server side. After receiving the request, the server will verify the legitimacy of the request, and then distribute the server through load balancing of dubbo components. The dubbo component is a distributed service framework, which can provide transparent RPC (Remote Procedure Call) remote service invocation, and has a soft load balancing and fault tolerance mechanism. S...
Embodiment 2
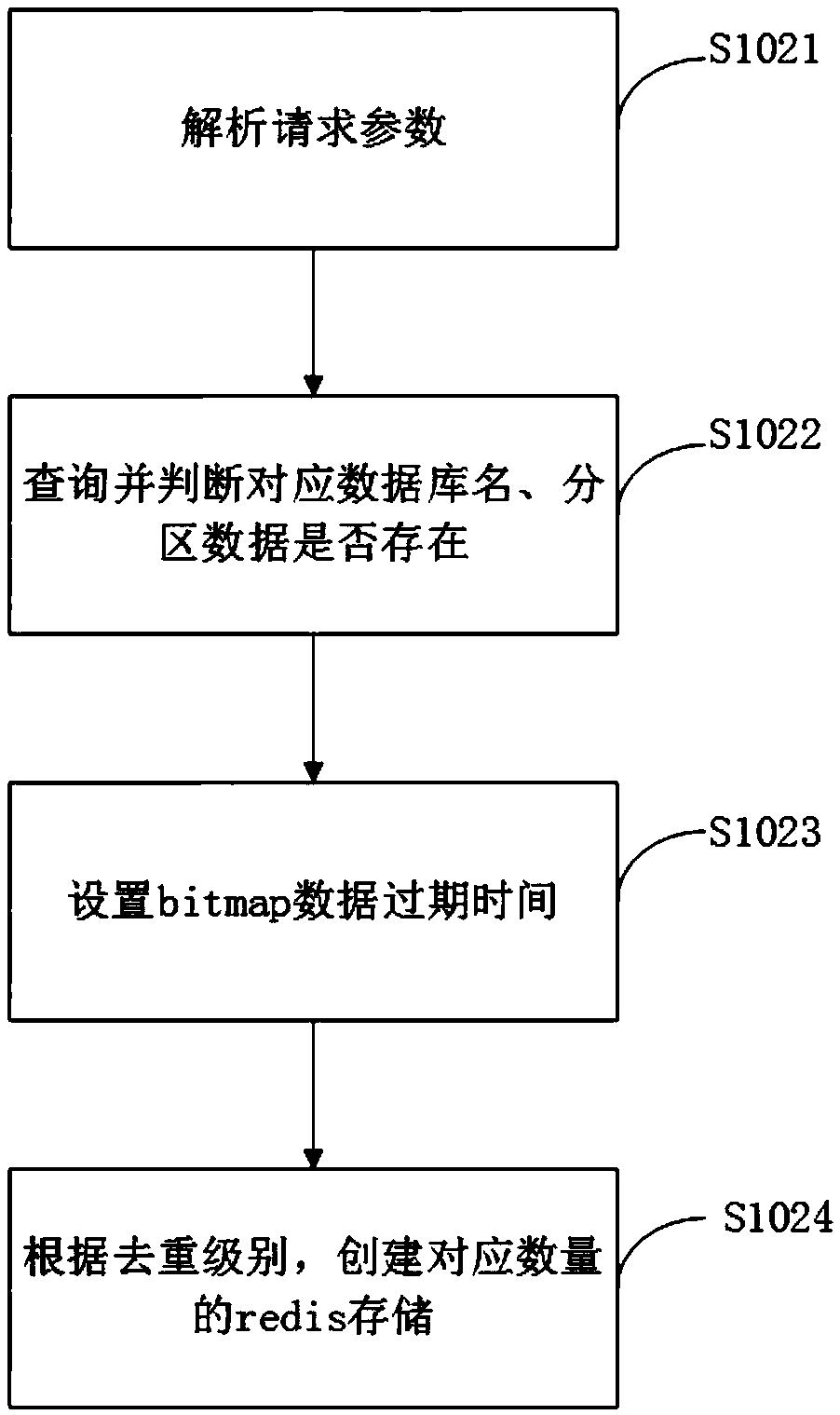
[0043] exist figure 1 on the basis of combining figure 2 Step S102 is described in detail, that is, to create a deduplication service data storage unit, as follows:
[0044] figure 2 The flowchart of step S102 provided for the embodiment of the present invention includes steps S1021, S1022, S1023, and S1024, and the above steps do not imply the sequence of execution.
[0045] In step S1021, by parsing the request parameters, the database name, partition data, and deduplication level can be obtained.
[0046] Before redis storage, you need to query the storage component redis to determine whether it has been stored, so as to avoid repeated data storage and occupy memory. Specifically, by obtaining the data name and partition data content in the request parameter, and then comparing it with the data traversal in the redis storage component, the interference can be eliminated through step S1022.
[0047] When there is no corresponding database name and partition data, creat...
Embodiment 3
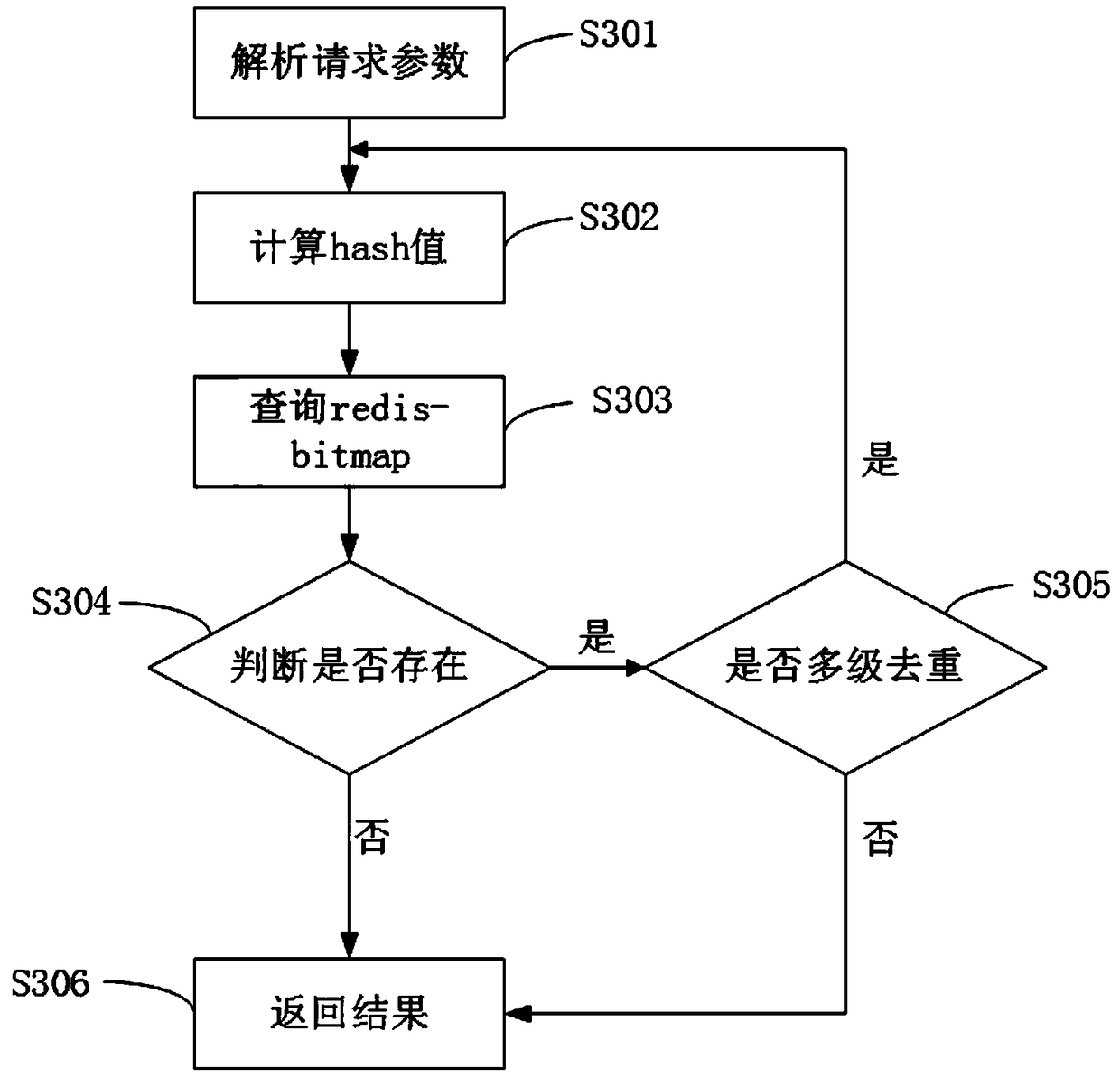
[0052] exist figure 1 on the basis of combining image 3 The process of creating the deduplication calculation unit in step S103 is described in detail as follows:
[0053] After parsing the application request parameters, it is necessary to obtain the set deduplication level parameters in step S103. The specific implementation process is performed in S301 and S302 through the Bloom Filter algorithm for deduplication counting. For example, when the deduplication level is level 1, calculate the hash value of a group of deduplication data, and find the corresponding redis storage unit according to the hash value result. Bitmap, and query in the bitmap, if it does not exist, then set 1 with the value of 0 in the corresponding bitmap bit, add the data to the storage unit of the deduplication result, and return the deduplication result. Each time the query result is returned according to the query process, if any bit returns a value of 0, it indicates that the query data does not...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com