Data classification method based on depth-width variable multi-kernel learning
A technology of multi-core learning and data classification, which is applied in the field of data classification based on deep-width variable multi-core learning, and can solve problems such as the reduction of classification results
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0090] A data classification method based on deep-width variable multi-kernel learning, the learning method comprising the following steps:
[0091] Step 1: Preparation of the data set, randomly divide 50% of the samples in the data set as the training set to train the model parameters, and the remaining 50% of the samples are used as the test set to verify the performance of the algorithm. The data set with n samples is input to the algorithm Previously sorted into n×(m+1)-dimensional vectors, m is the number of features of the sample, the last dimension defaults to label information, and the data labels with M samples are 0~M;
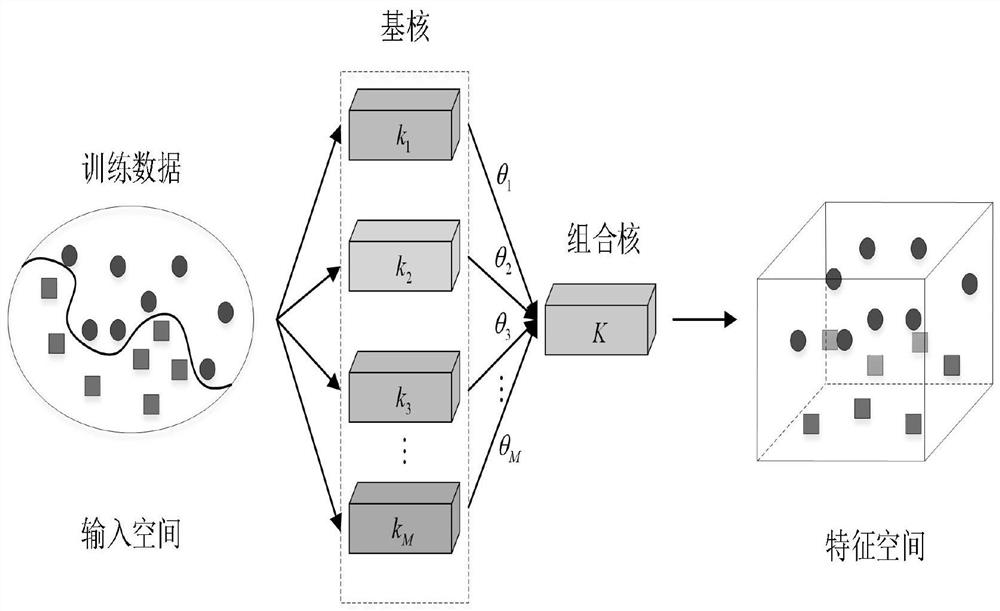
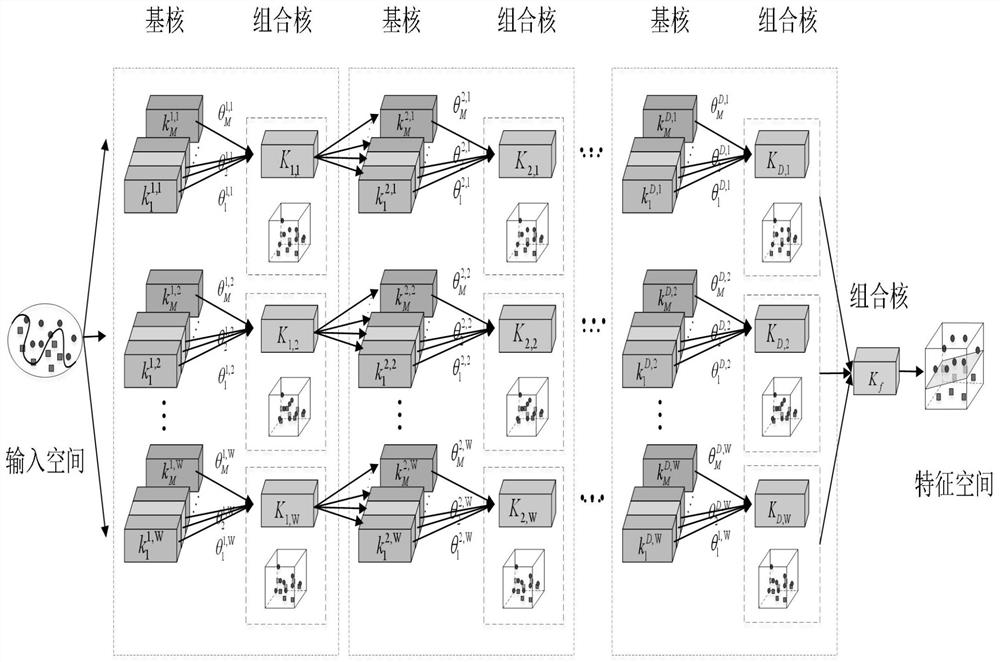
[0092] Step 2: The algorithm structure for classifying data sets is as follows. The DWS-MKL algorithm combines the hierarchical cascading ideas of MKL and deep learning to construct a unified architecture for multi-core learning with multi-layer and multi-channel combinations. Each channel is independent of each other. The number of layers of the arc...
Embodiment 2
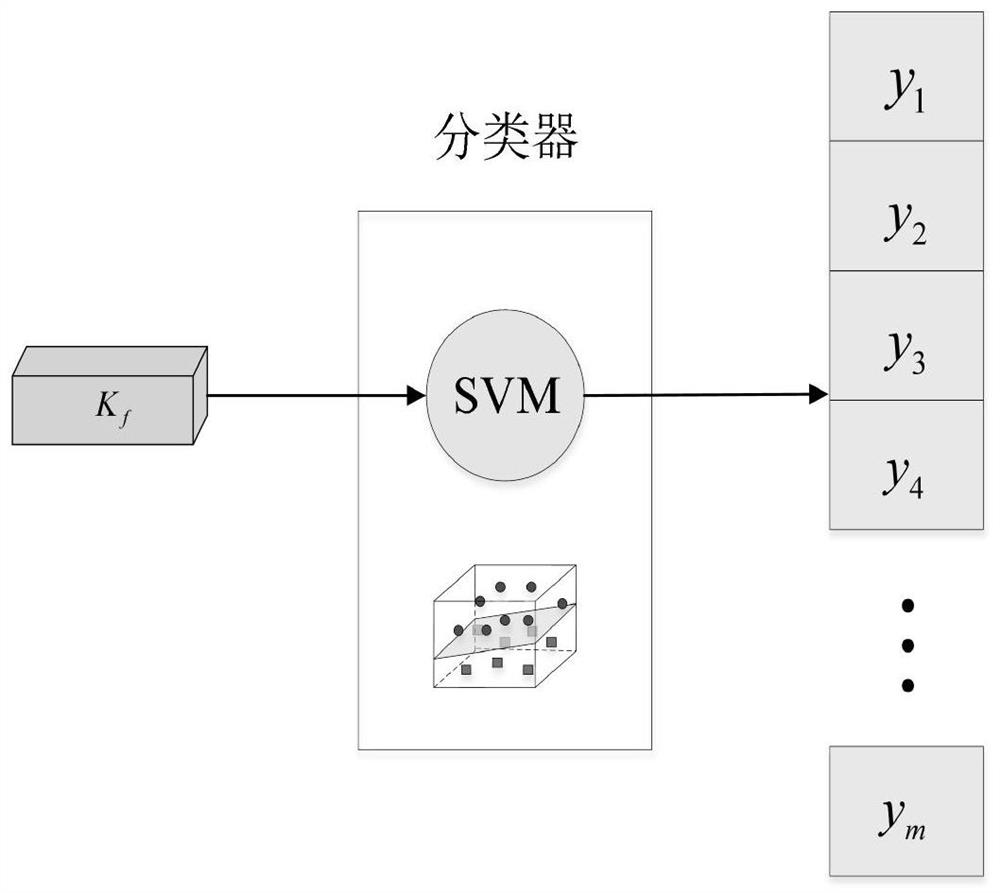
[0167] The method was used to classify 24 sub-datasets in the UCI dataset. Each data set is divided into training set and test set according to the ratio of 1:1. The combined kernel of each channel in each layer consists of four basic kernel functions, including linear kernel, RBF kernel and polynomial kernel (including 2nd-order polynomial and 3rd-order polynomial, and the free parameters are α=1 and β=1). The classifier is selected as the SVM standard classifier. In model training, the number of algorithm iterations is set to 100. The learning rate is lr=1E-5. The penalty coefficient of SVM is set to C∈[10 -1 ,10,10 2 ], and finally determined by 5-fold cross-validation. The algorithm is implemented using MATLAB, and the SVM classifier is implemented using the open source LIBSVM tool. For multi-classification tasks, the algorithm trains classifiers using a "one-vs-all" strategy. Use the trained model to verify the classification effect on the test set. Nine combined ...
Embodiment 3
[0181] The algorithm DWS-MKL proposed by the present invention is used for large-scale MNIST handwritten digit recognition. The MNIST dataset contains handwritten digits from 0 to 9, and the samples are all grayscale images of 28×28. The MNIST training set contains 50,000 samples, and the test set contains 10,000 samples. For the convenience of observation, randomly select 500 samples and use the T-SNE algorithm to reduce the data dimension to 2-D and 3-D such as Figure 4 shown. It can be seen from the figure that the various categories of the MNIST dataset are linearly inseparable. This example can prove that the DWS-MKL algorithm can handle high-dimensional linear inseparable data.
[0182] The experimental implementation method and hyperparameter settings are consistent with those in Example 1, and 5000 samples are randomly selected from the MNIST training set and test set as experimental data. Repeatedly run 10 groups of classification experiments, and calculate the a...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More