

Cross-modal retrieval method for querying video from complex text based on semantic tree enhancement
A semantic tree, cross-modal technology, applied in the field of cross-modal retrieval, can solve the problems of information loss, poor video retrieval effect, and ineffective complex text query.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


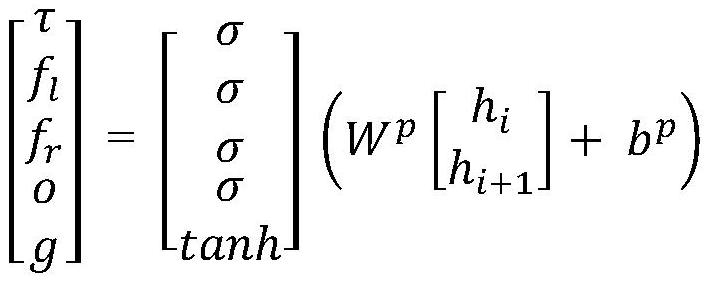
Examples
Embodiment Construction
[0067] The present invention will be described in detail below in conjunction with the accompanying drawings and specific embodiments.
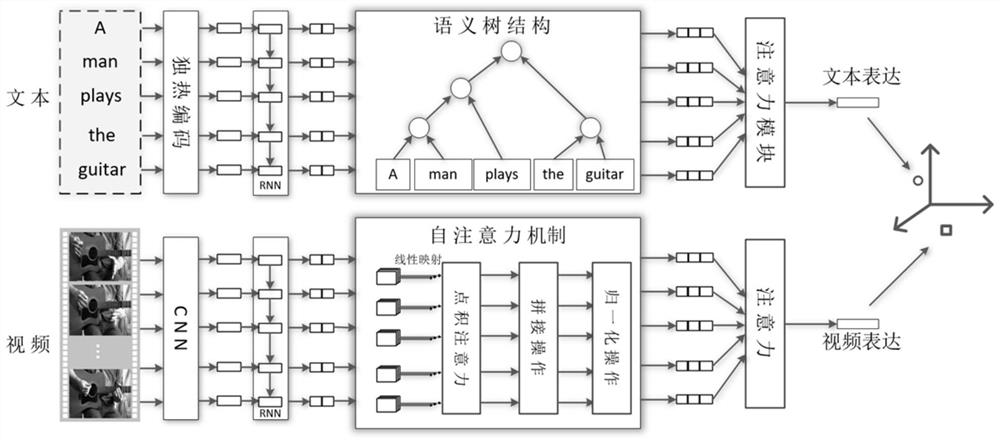
[0068] In order to solve the problem of cross-modal retrieval from complex text query to video, the present invention proposes a cross-modal retrieval method from complex text query to video based on semantic tree enhancement. The specific steps are as follows:
[0069] (1) Using the feature extraction method to extract the features of the complex text query statement, and obtain the leaf node features of the complex text query statement.
[0070] (1-1) Given a complex text query statement Q of length N, the complex text query statement Q can be expressed as:
[0071] Q={w 1 ,w 2 ,...,w N}
[0072] where w 1 Represents the first word in the complex text query sentence, first use one-hot encoding (one-hot) to encode each word in the complex text query sentence, and the one-hot encoding vector sequence {w′ 1 , w′ 2 ,...,w′ N}, where w′ ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More