

Knowledge distillation vertical field detection method based on similarity maintenance
A detection method and a similarity technology, applied in the field of text-based position detection, can solve the problems that the recognition accuracy needs to be improved, the computing resources and computing time overhead are large, and achieve the effect of reducing overhead and improving performance.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

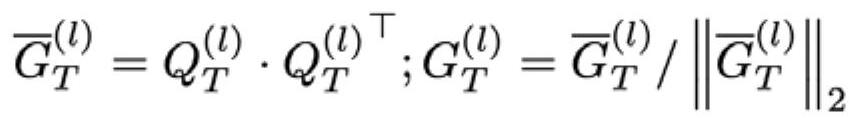
Examples
specific Embodiment approach 1
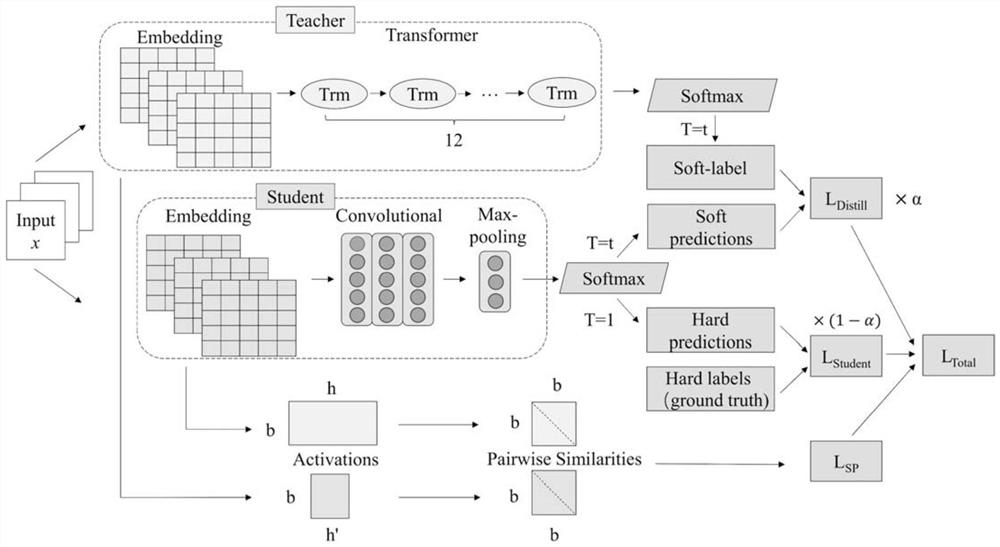
[0039] Specific implementation mode one: combine figure 1 To describe this embodiment,
[0040] This embodiment is a position detection method based on similarity-maintained knowledge distillation, which includes the following steps:
[0041] Obtain the position text to be detected, utilize Text-CNN network model to carry out position detection; The determination process of described Text-CNN network model comprises the following steps:
[0042] S1. Obtain instances of known positions and construct instance datasets:
[0043] Represents a data set with N instances, each instance x i contains a text s i , target t i and a stand label y i ;Each text consists of a sequence of words, s i ={w i0 ,w i1 ,...,w in}, each target also consists of a sequence of words, t i ={t i0 , t i1 ,...,t im}, n and m are respectively s i , t i The number of words in .
[0044] S2. Obtain the "Student" model based on knowledge distillation, that is, the Text-CNN network. The specifi...
Embodiment 1
[0089] Embodiment 1: Experiment of the present invention and baseline method:
[0090] (1) Dataset
[0091]Experiments are performed using two text stance detection datasets. One is the SemEval-2016 task 6 twitter position detection data set, and the other is the NLPCC-ICCPOL-2016 task 4 Chinese Weibo position detection data set. Each piece of data in the dataset is represented in the format of a triple ("stance", "target", "text"), where the "stance" label includes Favor, Against, and None.
[0092] For the English dataset, the training set contains 2914 English tweets with stance labels, and the test set contains 1249 tweets. There are 5 goals: "Atheism", "Climate Change is Concern(CC)", "Feminist Movement(FM)", "Hillary Clinton(HC)" and "Legalization of Abortion(LA)".
[0093] The Chinese dataset contains 4000 Chinese microblogs with stance labels, 3000 of which are used for training and 1000 for testing. There are also 5 targets: "IPhone SE", "Set off firecrackers in t...
Embodiment 2
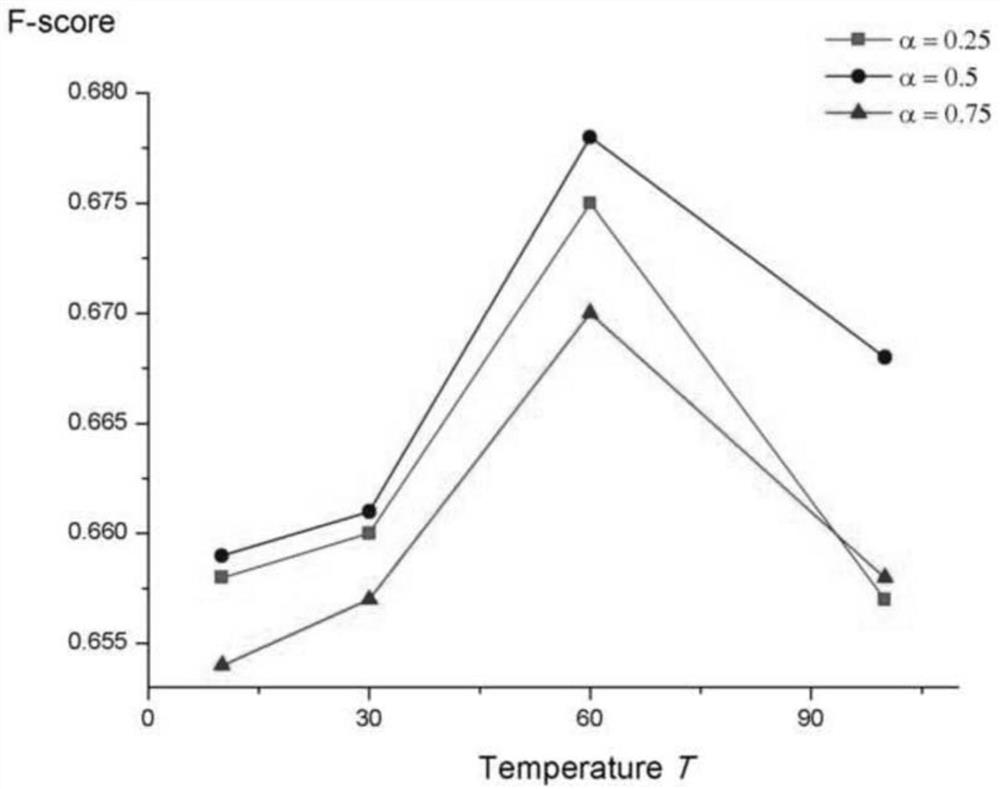
[0118] Embodiment 2: parameter sensitivity experiment
[0119] To analyze the impact of hyperparameters, we conduct two parameter sensitivity experiments on the English Twitter stance detection dataset.
[0120] Furthermore, in the knowledge distillation method, a small dataset may not be enough for the "teacher" model to fully express its knowledge. In order to make up for the lack of data in the English Twitter corpus and obtain a larger data set, the EDA: Easy Data Augment method is used to expand the data set. Four methods of synonym replacement, random insertion, random swap and random deletion are used to process twitter text.
[0121] Synonym Replacement (SR): Refers to randomly selecting n words that are not stop words from a sentence, and replacing each of them with a randomly selected synonym.
[0122] Random Insertion (RI): Randomly select a word in a sentence that is not a stop word and insert a synonym of it anywhere in the sentence. Repeat n times.
[0123] R...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More