Image target detection method and system
A target detection and image technology, which is applied in image analysis, image enhancement, image data processing, etc., can solve the problems of algorithm AP (low accuracy rate, low object detection accuracy rate of small targets, etc.), and achieve the effect of improving performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
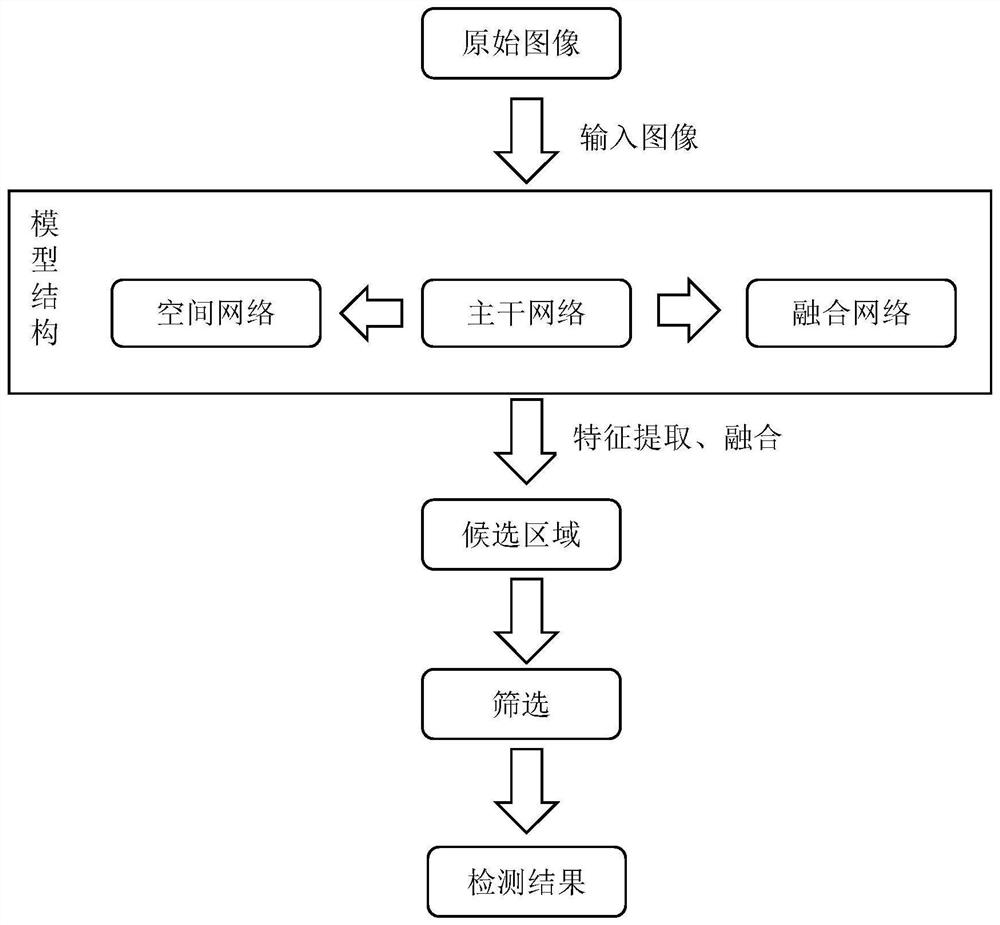
[0047] This embodiment provides a method for image target detection, such as figure 1 shown, including:
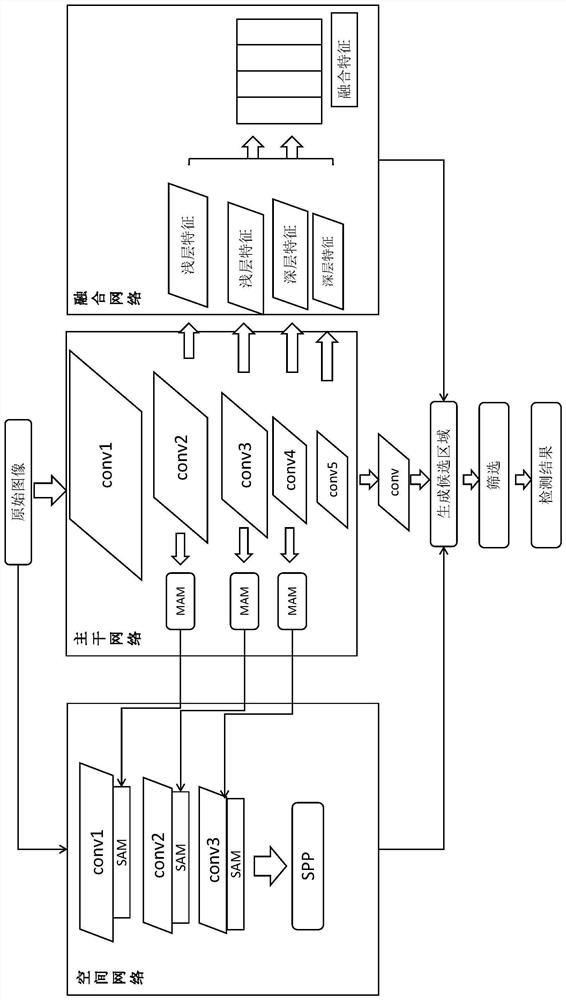
[0048] Obtain the image to be detected, input the image to be detected into the backbone network module and the spatial network module to extract features respectively, and the backbone network module inputs the image feature data extracted by multiple convolution layers into the spatial network module and the fusion network module respectively;
[0049] The spatial network module obtains high-resolution spatial features through the input image to be detected and the image feature data of multiple convolutional layers input by the backbone network module, and adds a spatial attention mechanism after each convolutional layer to strengthen spatial information , and finally integrate multiple spatial information of different scales and output;
[0050] The fusion network module combines the image feature data of multiple convolutional layers input by the backbone network mod...
specific Embodiment approach
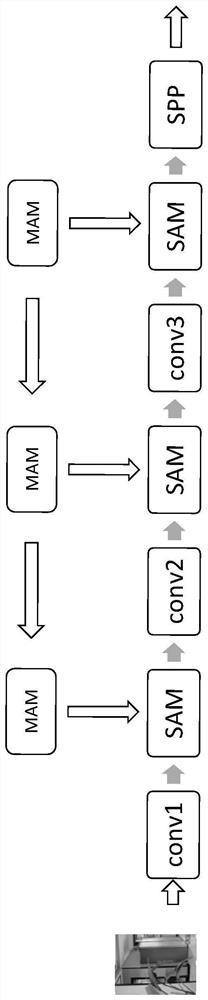
[0053] The image feature data extracted by multiple convolutional layers of the backbone network module are respectively input to the spatial attention mechanism SAM of the space network module through the corresponding multi-level attention module MAM, and the multi-level attention module MAM is used to obtain multiple Level feature information, and then combine the multi-level feature information to achieve feature enhancement.
[0054] The multi-level attention module MAM is specifically used to use F n Get F after upsampling n-1 , combining two levels of features F n and F n-1 (F n Indicates the feature after the nth layer of convolution, F n-1 express to F n The features after upsampling) are concatenated to obtain the combined feature F, and then the feature F is transformed by a 3×3 convolution with batch regularization and nonlinear units to obtain the feature F'. The multi-level attention module MAM has Two hyperparameters: expansion rate d and compression rate ...
Embodiment 2
[0087] In this embodiment, an image target detection system is provided, such as Figure 6 As shown, including: backbone network module, space network module and fusion network module;
[0088] The backbone network module and the spatial network module are respectively connected to the input, and the plurality of convolution layers in the backbone network module are respectively connected to the spatial network module and the fusion network module, and the output of the backbone network module is passed through the convolution module Connected to the detection and identification module, the output ends of the space network module and the fusion network module are respectively connected to the detection and identification module, and the detection and identification module is connected to the filtering module.
[0089] A specific implementation of the image target detection system, the backbone network module includes: a first convolutional layer, a second convolutional layer, ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More