

Large-scale distributed parallel acceleration method and system for protein identification
A protein identification, large-scale technology, applied in special data processing applications, instruments, electrical digital data processing, etc., can solve problems such as poor acceleration efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
[0077] The present invention will be described in detail below in conjunction with the accompanying drawings and specific embodiments, but not as a limitation of the present invention.
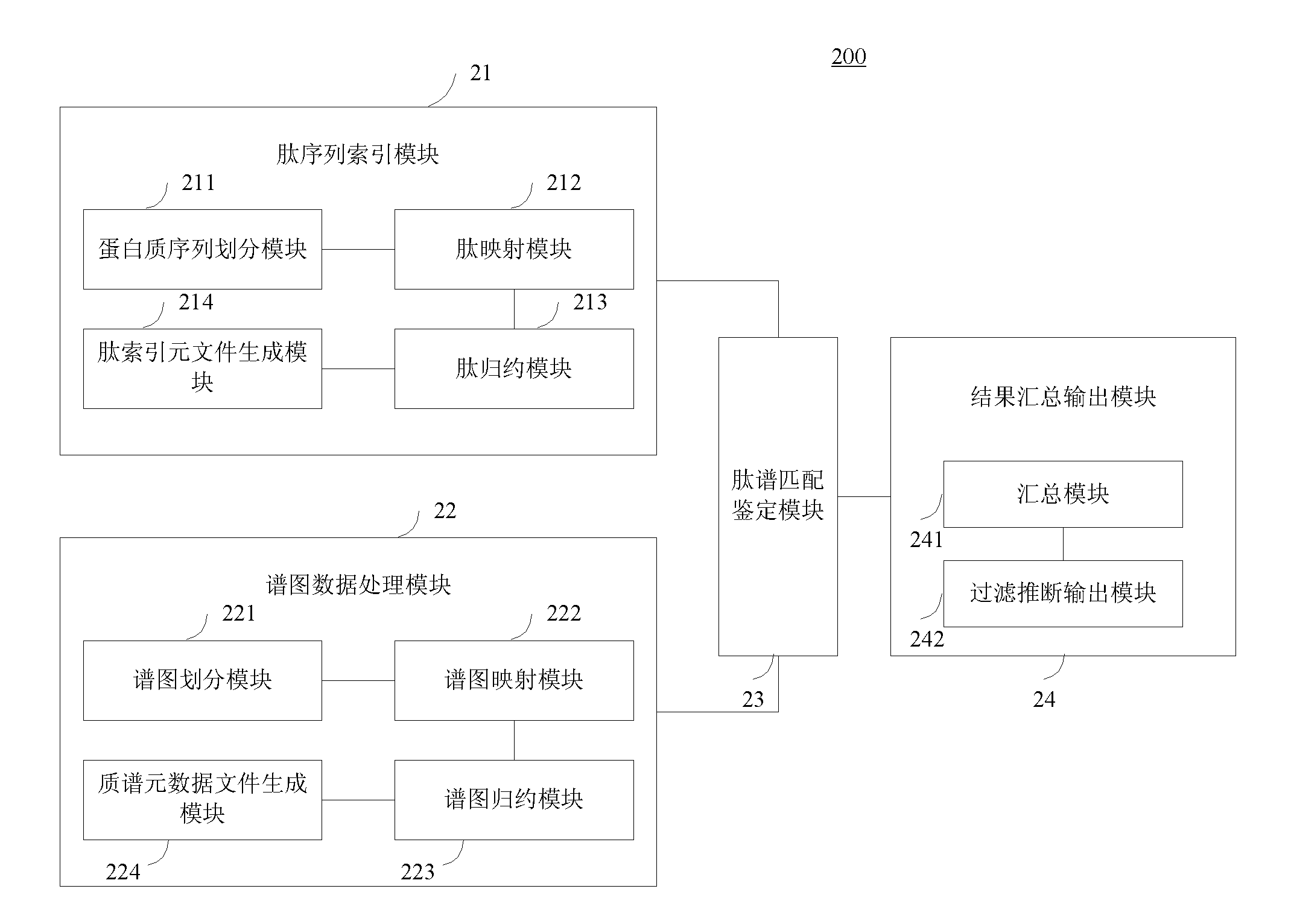
[0078] Such as figure 1 As shown, it is a flow chart of the large-scale distributed parallel acceleration method for protein identification of the present invention. The process uses the following operations to perform large-scale distributed parallel acceleration of protein identification. The specific steps are as follows:
[0079] Step 101, first set the necessary search parameters;
[0080] Step 102, then input the protein sequence, use multiple processor processes in the cluster to theoretically digest the protein sequence, sort the obtained peptide sequences according to the theoretical precursor ion mass, remove redundancy, and finally create a peptide index file block, and Generate peptide index metadata files from peptide index file blocks;
[0081] Step 103, next analyze the input ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More