

Automatic source code annotation generation method based on data mining
An automatic generation and data mining technology, which is applied to network data retrieval, network data indexing, and other database retrieval, etc., can solve the problems of heavy data collection and screening workload, lagging annotation information update, low annotation coverage, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

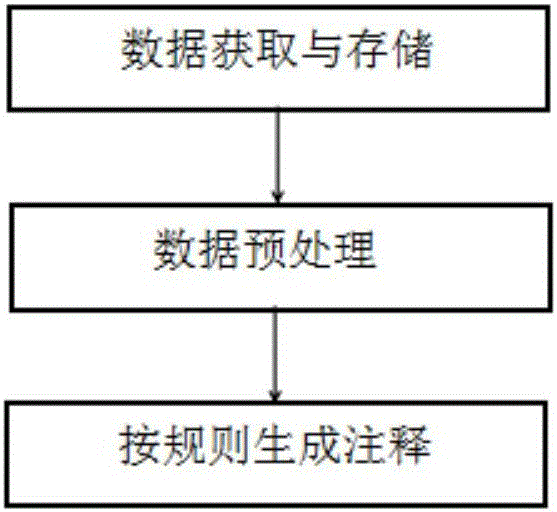
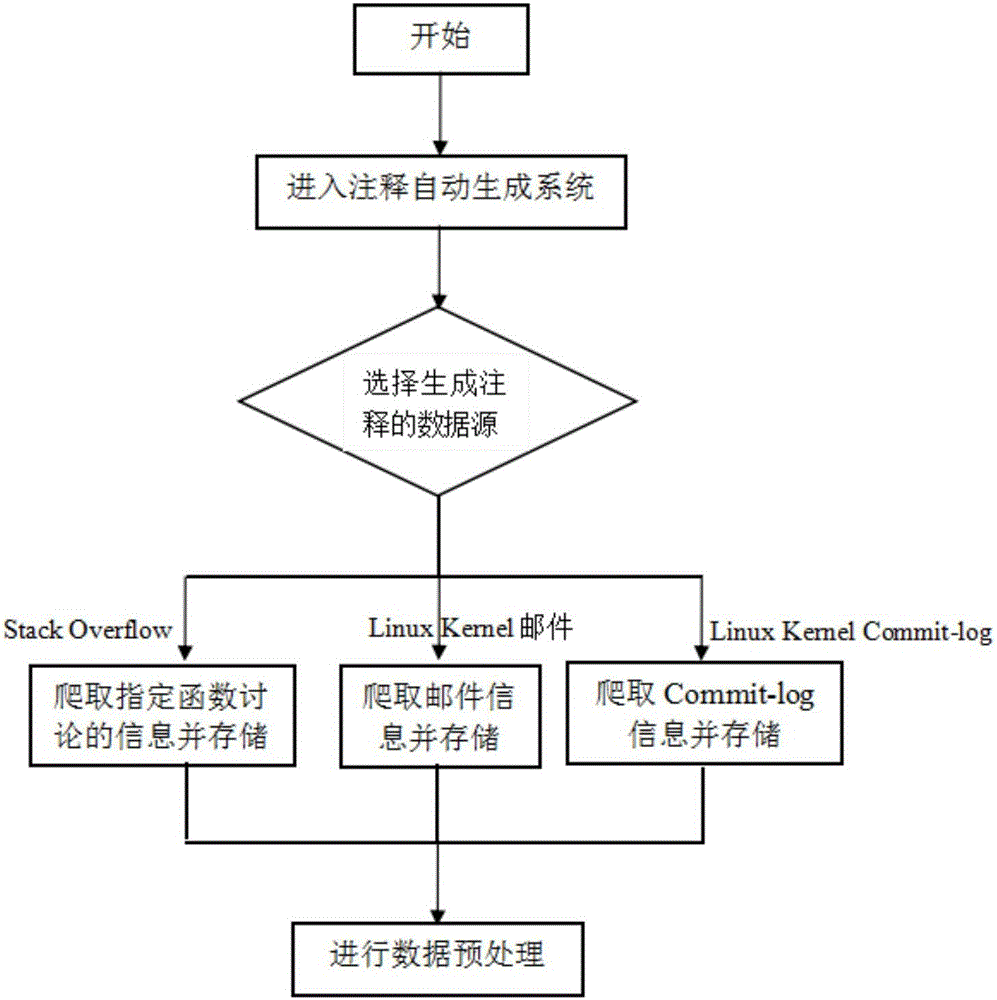
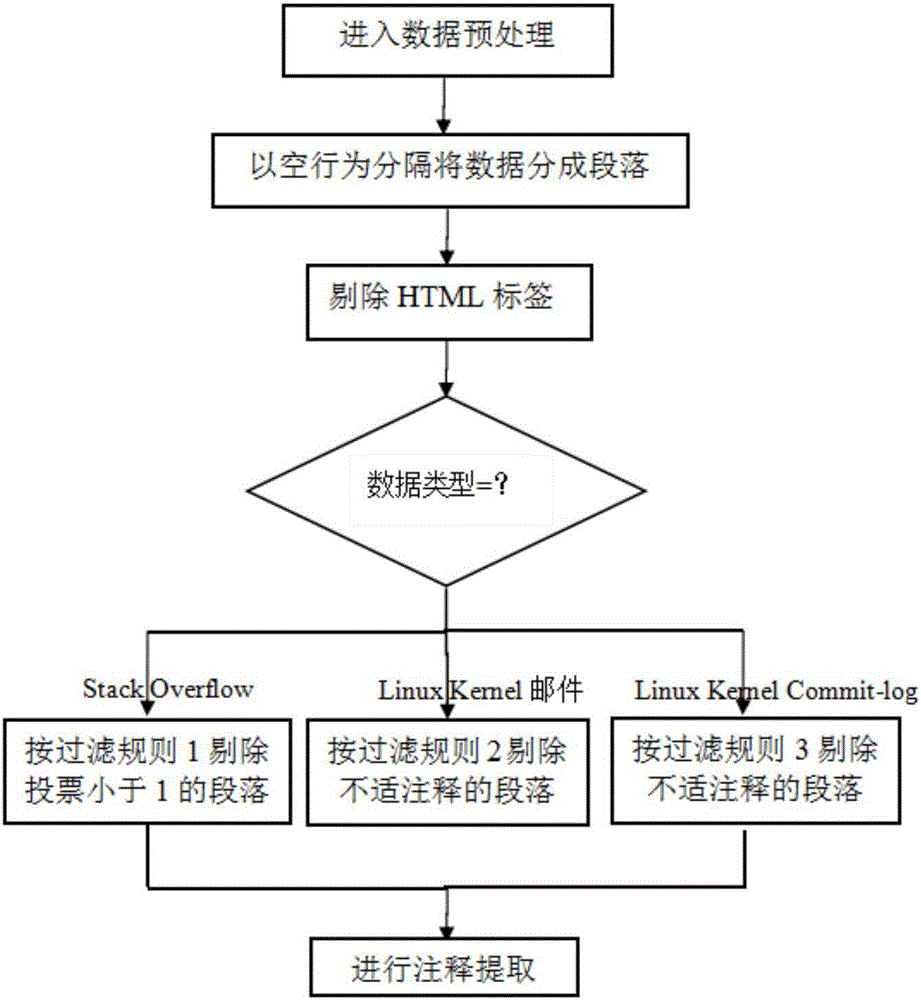
Examples
Embodiment 1
[0098] This embodiment sets the following usage scenarios:
[0099] Using the Stack Overflow website data source, apply this method to automatically generate comments for the fork() function.
[0100] 1) Enter the annotation automatic generation system, select the Stack Overflow data source, search for the keyword "linux fork()", crawl the content of the obtained webpage, and obtain the corresponding texts of 15 topics. One of the topics reads as follows:
[0101] Question number: 12881111
[0102] Question title: Output offock() calls
[0103] Problem Description:
[0104] What would be the output off following fork() call?
[0105] fork(){
[0106] fork();
[0107] fork();
[0108] fork()&&fork()||fork();
[0109] fork();
[0110] Print("Saika collection\n");
[0111] Can anyone help me in getting the answer to this code as well as some explanations as i am new to OS? I have found several questions on fork() on SO, but couldn't figure out.
[0112] Question Votes:...
Embodiment 2
[0131] This embodiment sets the following usage scenarios:
[0132] Using the Linux kernel emails as the data source, select emails from July 16 to July 23, 2016, and apply this method to automatically generate function comments.
[0133] 1) Enter the comment automatic generation system, select the Linux kernel email as the data source, and crawl 4493 emails during this period. The title and body text of one of the letters is as follows:
[0134] Title: timer_list:print_tickdevice():calculate->min_delta_nsdynamically
[0135] Text: print_tickdevice(), assembling the per-tick device sections in / proc / timer_list, is the last user of struct clock_event_device's->min_delta_nsmember.
[0136] In order to make this one fully obsolete while retaining userspaceABI, calculate the displayed value of'min_delta_ns'on the fly from->min_delta_ticks_adjusted.
[0137] Signed-off-by: Nicolai Stange
[0138] ---
[0139] kernel / time / timer_list.c|5+++--
[0140] 1file changed, 3insertion...
Embodiment 3
[0149] This embodiment sets the following usage scenarios:
[0150] Use the Linux kernel Commit-log as the data source, select the log information between the v4.8-rc3 and v4.8-rc2 versions, and apply our own method to automatically generate function comments.
[0151] 1) Enter the comment automatic generation system, select the Linux kernel Commit-log as the data source, and crawl 136 Commit-log information in total. The text of one of the Commit-log title and body is as follows:
[0152] Title: dm raid:enhance attempt_restore_of_faulty_devices() to support more devices
[0153] Text: dm raid:enhance attempt_restore_of_faulty_devices() to support more devices
[0154] attempt_restore_of_faulty_devices() is limited to 64 when it should support the new maximum of 253 when identifying any failed devices. It clears any revivable devices via an MD personality hot remove and add cylce to allow for their recovery.
[0155] Address by using existing functions to retrieve and updat...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More