

Feature selection method and device for high-dimensional data and computer storage medium for high-dimensional data
A feature selection method and high-dimensional data technology, applied in the field of information processing, can solve the problems that cannot be widely used and the time complexity of the algorithm is high
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
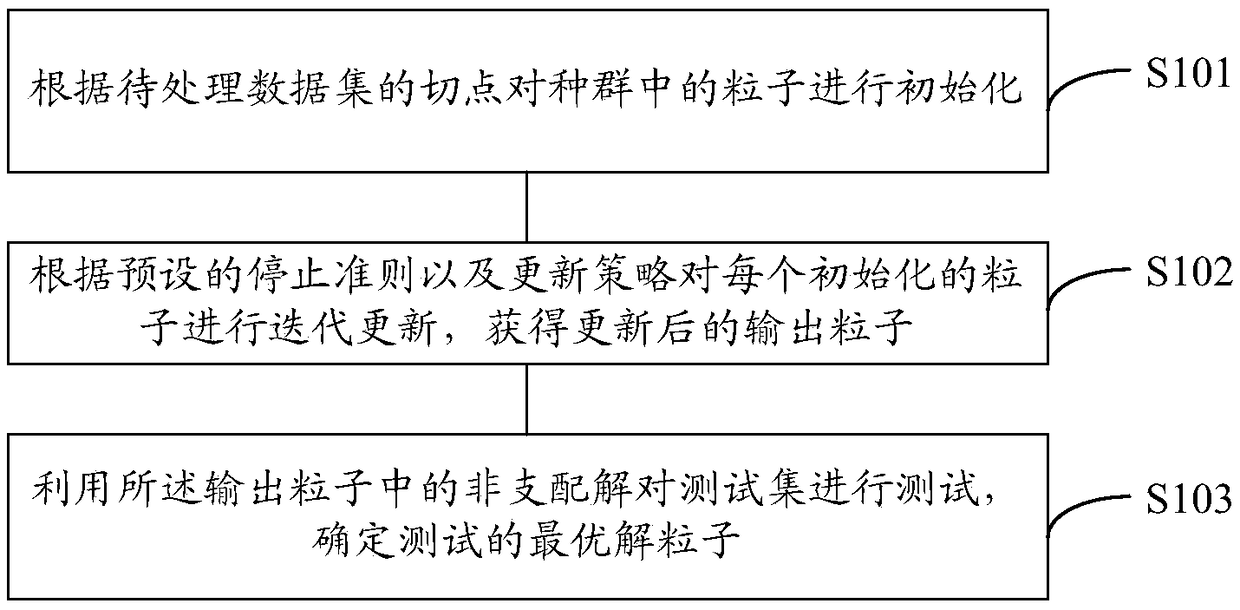
[0031] Based on the above, see figure 1 , which shows a feature selection method for high-dimensional data provided by an embodiment of the present invention, the method may include:
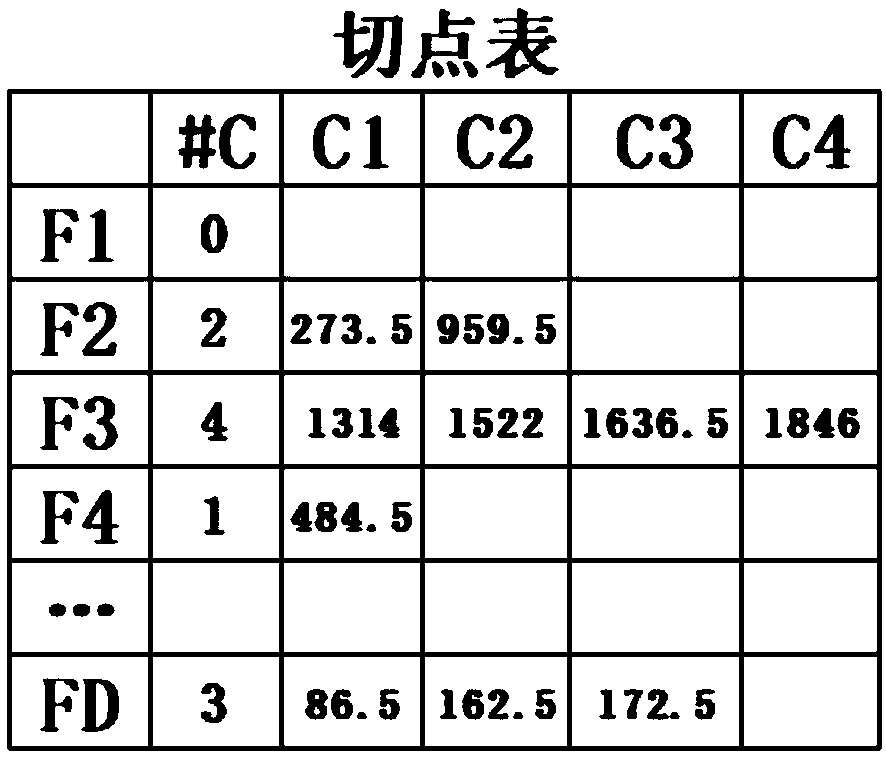
[0032] S101: Initialize the particles in the population according to the cut point of the data set to be processed;
[0033] S102: Iteratively update each initialized particle according to a preset stop criterion and an update strategy to obtain updated output particles;
[0034] S103: Use the non-dominated solutions in the output particles to test the test set, and determine the optimal solution particle for the test; wherein, the test set is a part of the data set to be processed, and the test optimal solution is used for Feature selection is performed on the data set to be processed, and the optimal solution for the test is the particle with the highest classification accuracy and the least number of features in the test set.
[0035] It should be noted, figure 1 In the solution shown, in ...
Embodiment 2
[0086] In order to verify the feature selection method shown in the first embodiment, this embodiment also compares the technical solution of the first embodiment with other feature selection algorithms to verify the robustness and reliability. First, the technical solution of Embodiment 1 is shown in pseudocode form as follows:
[0087]
[0088]
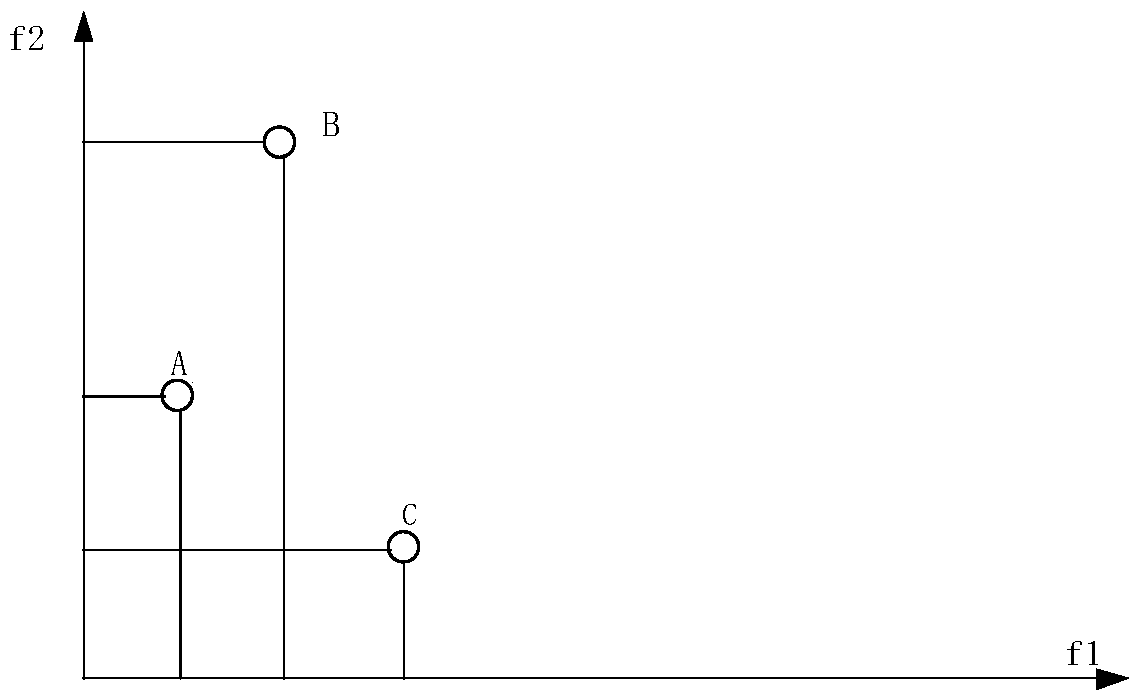
[0089] In addition, in order to compare the technical solution of Example 1 with other feature selection algorithms, 10 high-dimensional gene datasets are set for testing, and these 10 datasets can be found at http: / / www.gems-system.org download on . The evaluation of the particles and the calculation of the classification accuracy are carried out by the KNN algorithm, the K value is set to 1, and the details of the data set are as follows Figure 5 shown. exist Figure 5 , the first column represents the name of the dataset, the second column represents the total number of features, the third column represents the number o...
Embodiment 3
[0100] Based on the same inventive concept as the previous embodiments, see Figure 7 , which shows a feature selection device 70 for high-dimensional data provided by an embodiment of the present invention, including: an initialization part 701, an update part 702, and a determination part 703; wherein,
[0101] The initialization part 701 is configured to initialize the particles in the population according to the tangent point of the data set to be processed;
[0102] The updating part 702 is configured to iteratively update each initialized particle according to a preset stopping criterion and an update strategy to obtain updated output particles;
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More