Network information risk identification method and system
An information and network technology, applied in the Internet field, can solve the problems of inability to identify the latest risk information and low update efficiency, and achieve the effect of improving the ability of network information risk identification and expanding coverage
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


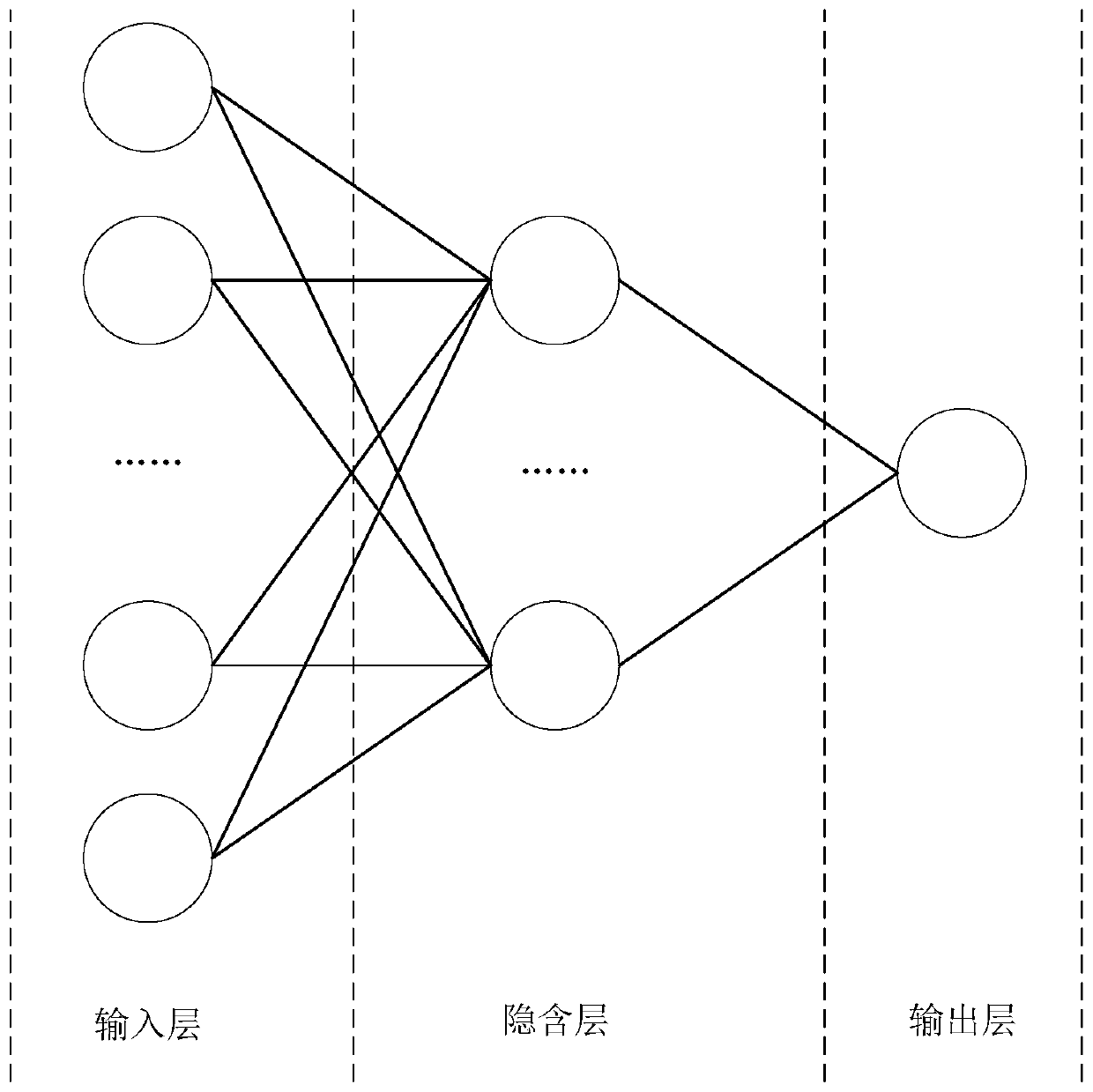
Examples
Embodiment Construction
[0018] In order to make the purposes, technical solutions and advantages of the embodiments of the present invention more clearly understood, the embodiments of the present invention will be further described in detail below with reference to the accompanying drawings. Here, the exemplary embodiments of the present invention and their descriptions are used to explain the present invention, but not to limit the present invention.
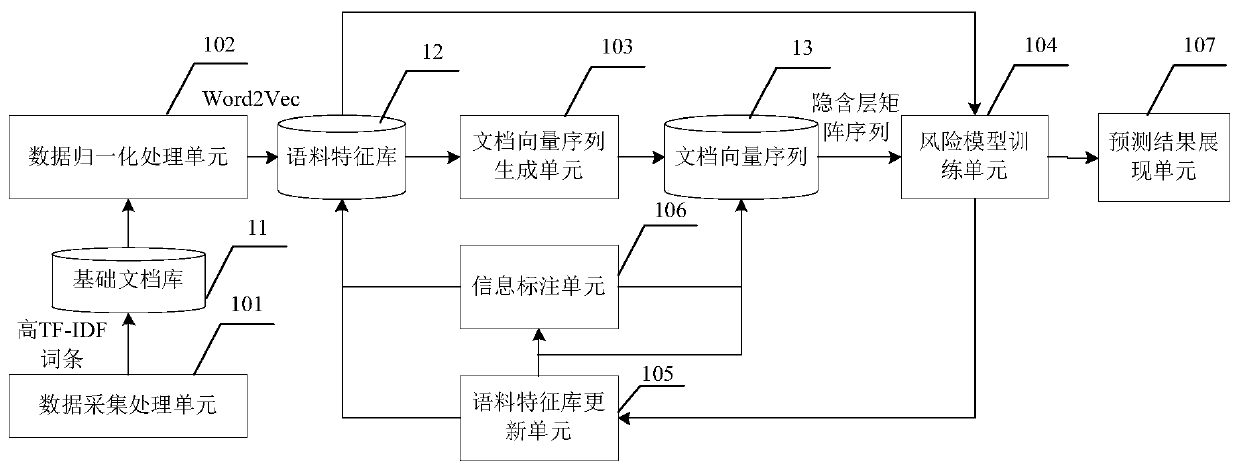
[0019] The embodiment of the present invention provides a network information risk identification system, figure 1 A schematic diagram of a network information risk identification system provided in an embodiment of the present invention, such as figure 1 As shown, the system includes: a data acquisition processing unit 101 , a data normalization processing unit 102 , a document vector sequence generation unit 103 and a risk model training unit 104 .
[0020] The data collection and processing unit 101 is used to collect network information data, wh...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More