CNN quantification method based on low-precision floating-point number, forward calculation method and device
A quantization method and forward computing technology, applied in the field of deep convolutional neural network quantization, which can solve problems such as low acceleration performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
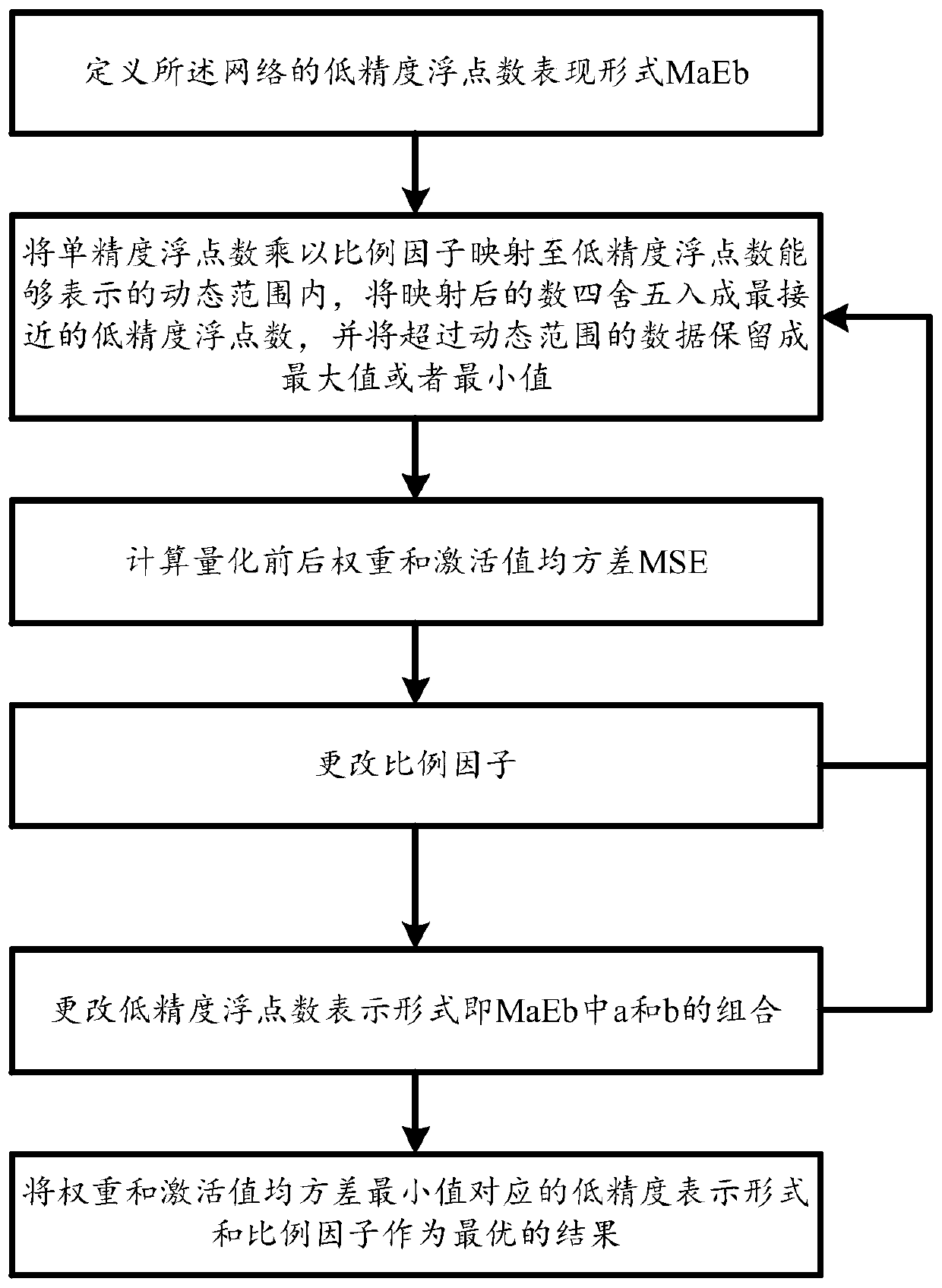
[0072] In view of the need for retraining in the prior art to ensure accuracy, quantization requires the use of 16-bit floating-point numbers or 8-bit specific points to ensure accuracy. The quantization method of this application uses the low-precision floating-point number representation MaEb, and does not require retraining In the case of , you can find the optimal data representation form, only need a 4-bit or 5-bit mantissa, to ensure that the loss of top-1 / top-5 accuracy is negligible, and the loss of top-1 / top-5 accuracy The amount is within 0.5% / 0.3%, respectively, as follows:
[0073] The CNN quantization method based on low-precision floating-point numbers includes the following steps in each layer of each convolutional neural network:
[0074] Step 1: define the low-precision floating-point representation MaEb of the network, the low-precision floating-point representation includes a sign bit, a mantissa and an exponent, wherein a and b are positive integers;
[00...
Embodiment 2
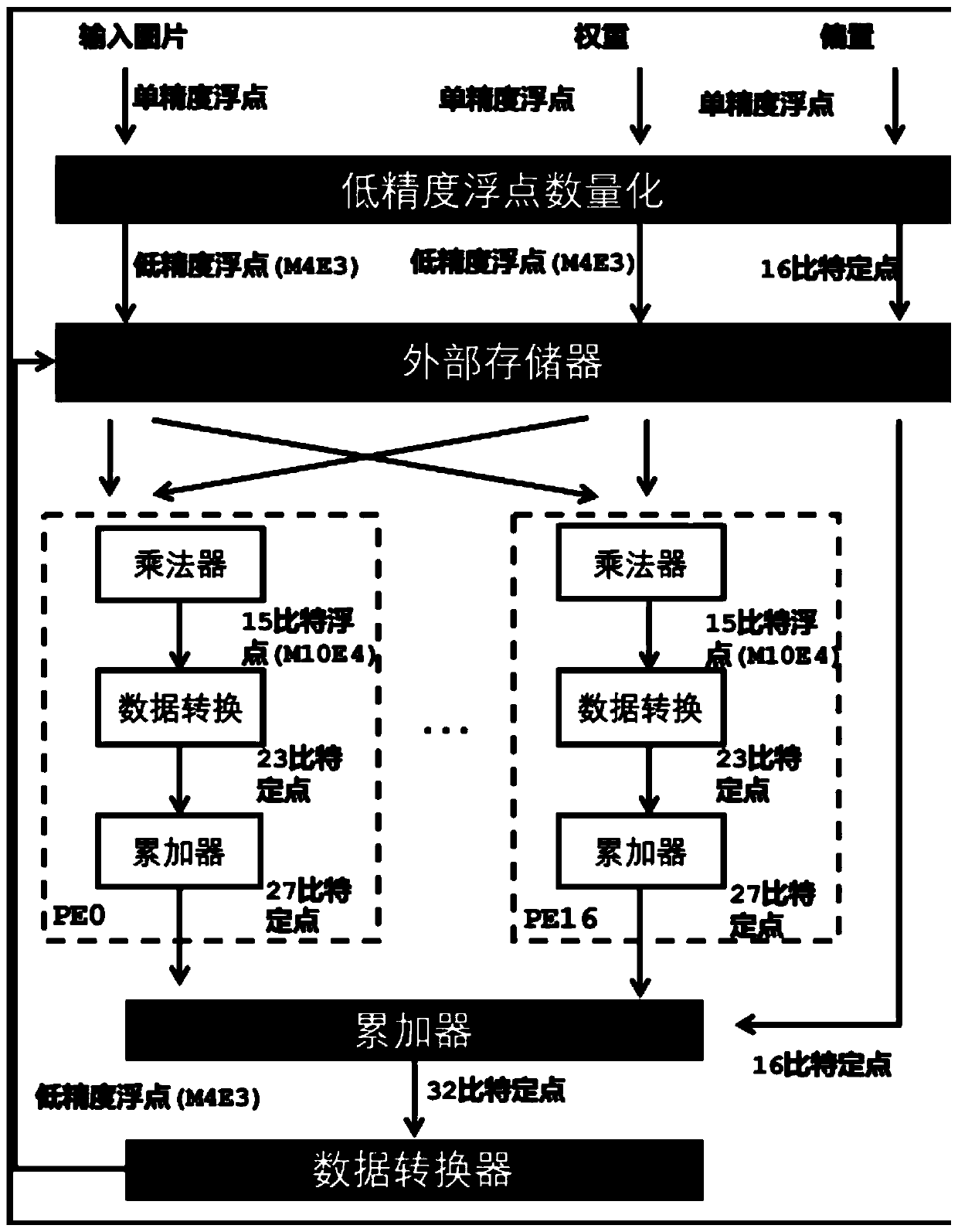
[0098] Based on Embodiment 1, this embodiment provides a convolutional layer forward calculation method, including the following steps in the convolutional neural network:
[0099] Step a: Quantize the input data of single-precision floating-point numbers into floating-point numbers of MaEb in the form of low-precision floating-point numbers, the input data includes input activation values, weights and biases, and a and b are positive integers;
[0100] Step b: Distribute the floating-point numbers of MaEb to the parallel N in the floating-point number function module m A low-precision floating-point multiplier performs forward calculation to obtain a full-precision floating-point product, where N m Represents the number of low-precision floating-point number multipliers of a processing unit PE in the floating-point number function module;
[0101] Step c: transmitting the product of the full-precision floating-point number to the data conversion module to obtain a fixed-poin...
Embodiment 3
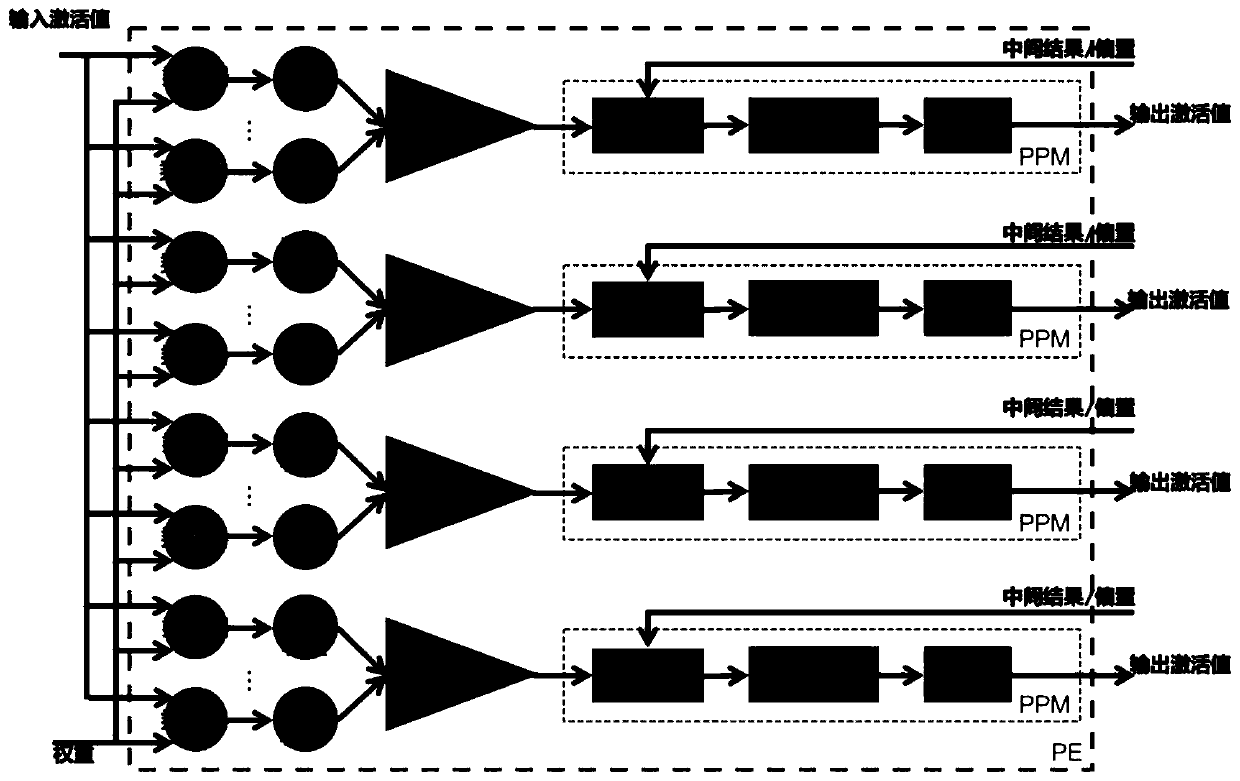
[0128] Based on embodiment 1 or 2, this embodiment provides a device, such as image 3 As shown, it includes a floating-point number function module of a customized circuit or a floating-point number function module of a non-customized circuit; the floating-point number function module is used to distribute input data to different processing units PE and perform parallel calculations through low-precision floating-point number representations. is the dot product of MaEb floating-point numbers, and completes the forward calculation of the convolutional layer;
[0129] The floating-point function module includes n parallel processing units PE, and the processing unit PE realizes N m A MaEb floating point multiplier, wherein, n is a positive integer, a, b are both positive integers, N m Indicates the number of low-precision floating-point number multipliers of a processing unit PE.
[0130] Each processing unit PE includes 4T parallel branches, and each parallel branch contains...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com