

Method for constructing product industry parallel data set by using incremental singular value decomposition method
A singular value decomposition and parallel data technology, applied in complex mathematical operations, instruments, character and pattern recognition, etc., can solve problems such as long time spans, increased batches, and difficulty in reproducing scene data
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
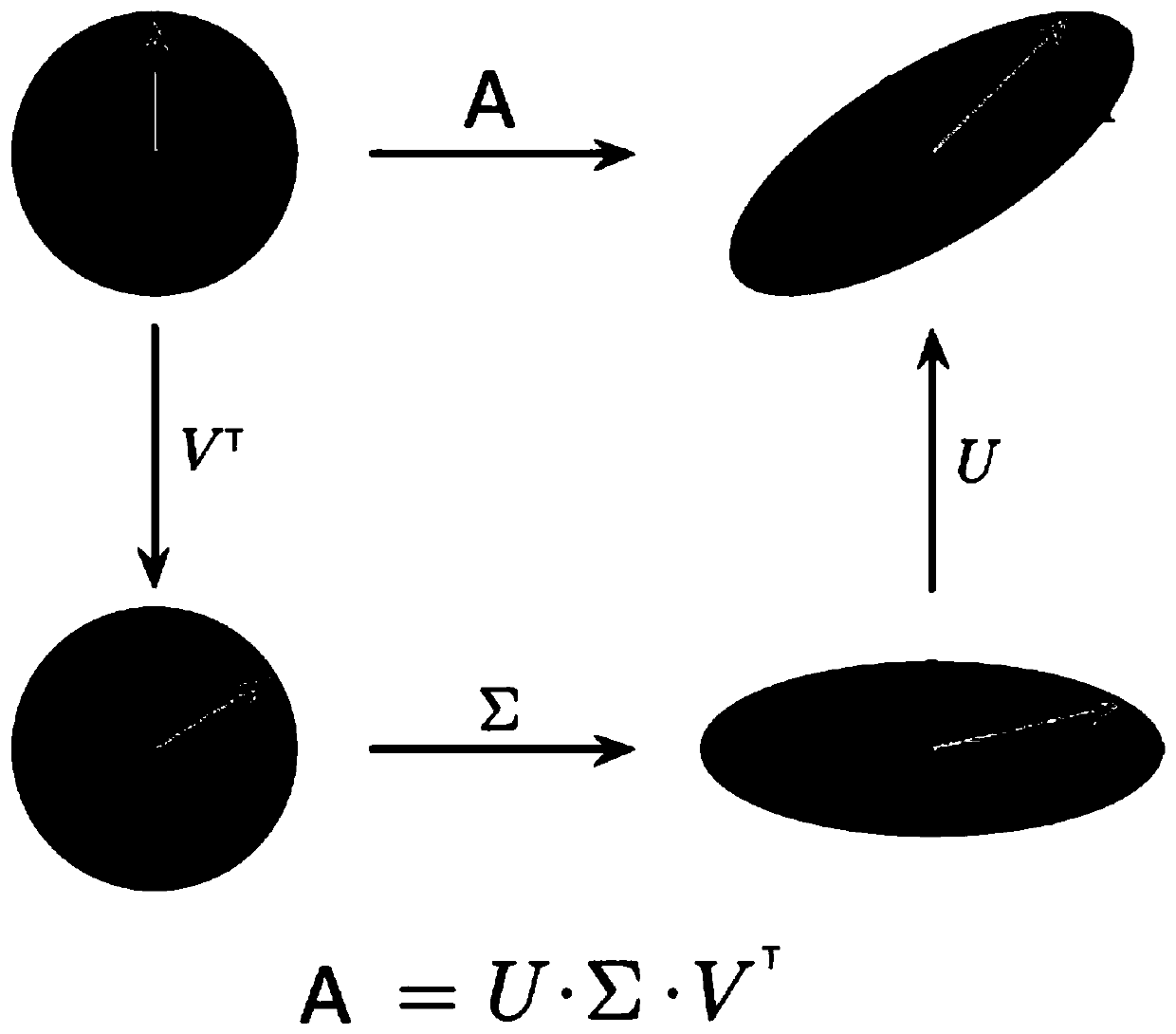
Method used
Image

Examples
Embodiment 1
[0109] In the process of growing grapes, the precipitation in a certain year is relatively high, the temperature is relatively low, and there is a danger of pests and diseases. I hope to modify the irrigation method of water and fertilizer, but I don’t know how to adjust it to ensure the optimal yield and quality.
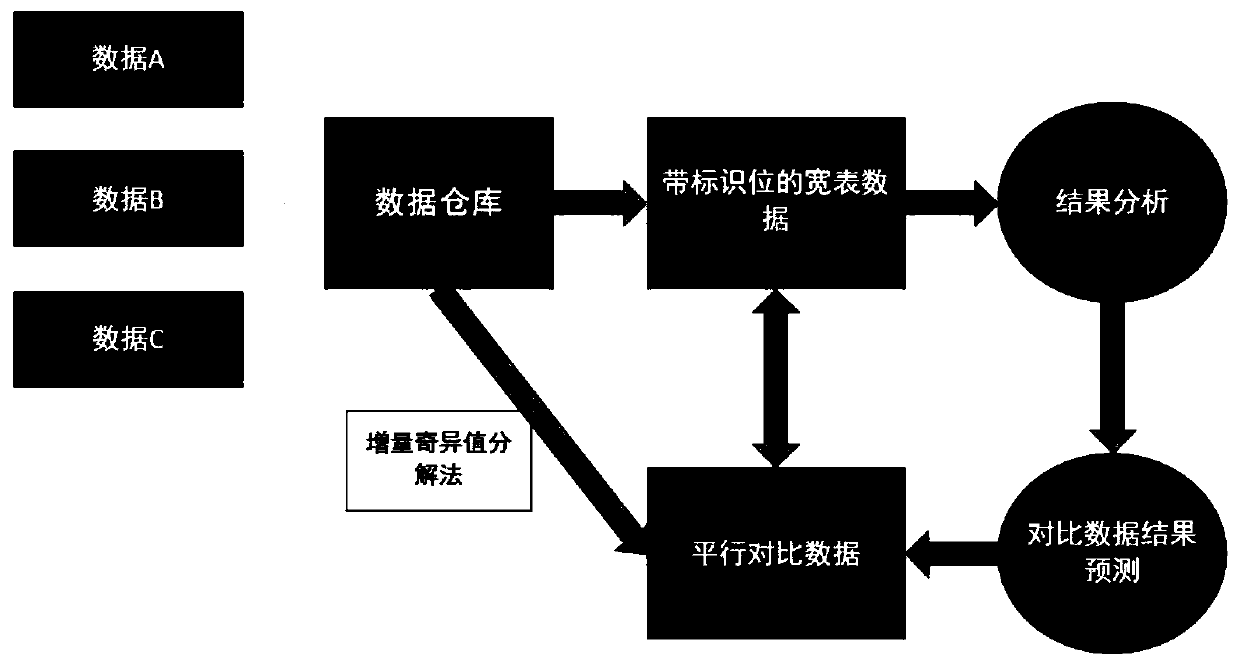
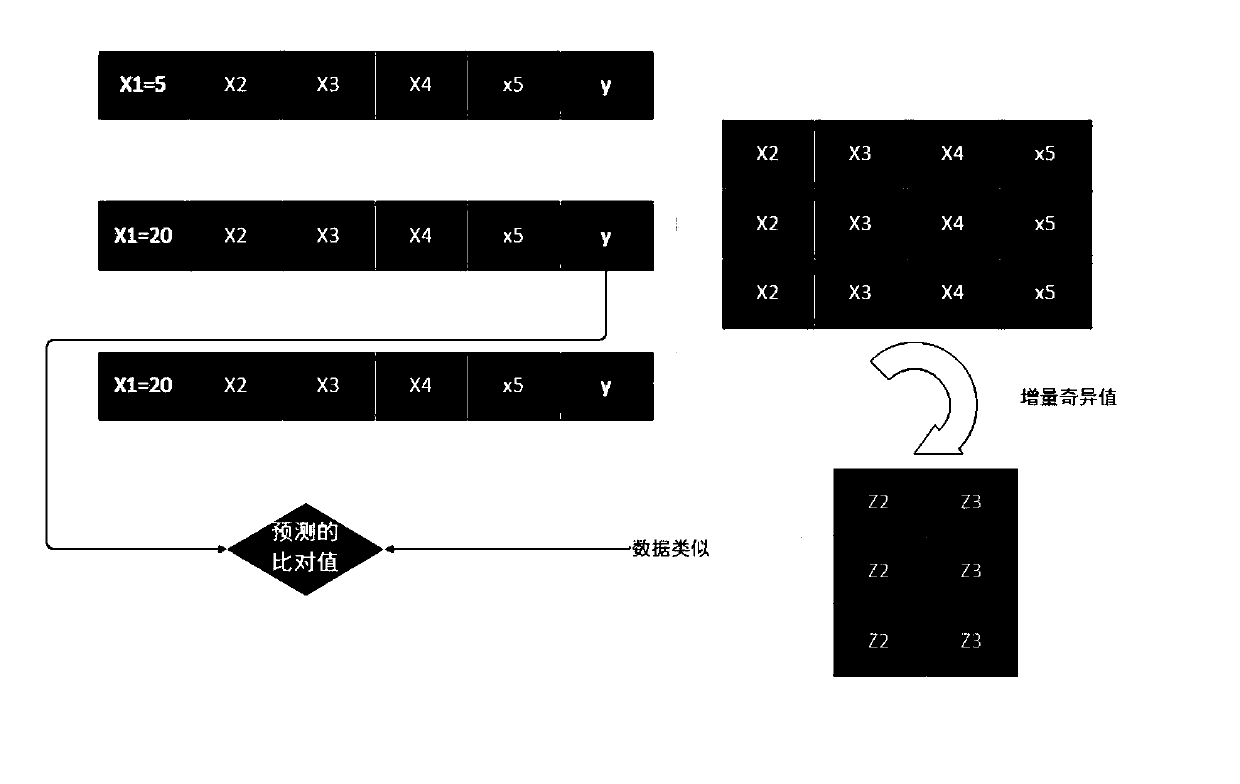
[0110] Step 1: Establish a horizontal table data, link the daily precipitation, water and fertilizer irrigation, pest impact, water and fertilizer irrigation method and the grape yield and quality data of the previous years to form a wide table data Ω.
[0111] Step 2: Get the wide-table data set B corresponding to the output and quality of normal years in the wide-table data set Ω.
[0112] Step 3: Assuming that the water and fertilizer index in a normal year is x, according to the three water and fertilizer indexes of 1.5x, 2x, and 0.8x respectively, obtain parallel data candidate sets D1, D2, and D3 from the part of the data set Ω other than B;
[0113] Assuming...
Embodiment 2
[0120] During the brewing process of wine, a process engineer wants to increase the amount of an enzyme added, but they don't know if doing so will affect the quality of the final wine.
[0121] Step 1: Establish a horizontal table data, which includes indicators such as temperature, humidity, enzyme addition, fermentation time, acidity and sweetness of grape juice in previous production batches, and quality data such as color, taste and alcohol content of the produced wine Associated to form a wide table data Ω.
[0122] Step 2: Obtain the wide-table data set B corresponding to the current process result from the wide-table data set Ω.
[0123] Step 3: Assume that the enzyme index corresponding to the current industrial results is x, respectively, according to the assumption that the increased enzyme index is 2x, and obtain a parallel data candidate set D from the part of the data set Ω other than B;
[0124] Assuming that the wide table data set B has 200 attributes, perfor...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More