Chinese text classification method based on pre-trained word vector model and random forest algorithm
A random forest and word vector technology, applied in text database clustering/classification, neural learning methods, biological neural network models, etc., can solve problems such as redundancy, insufficient model generalization ability, and insufficient semantic information to fully express.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

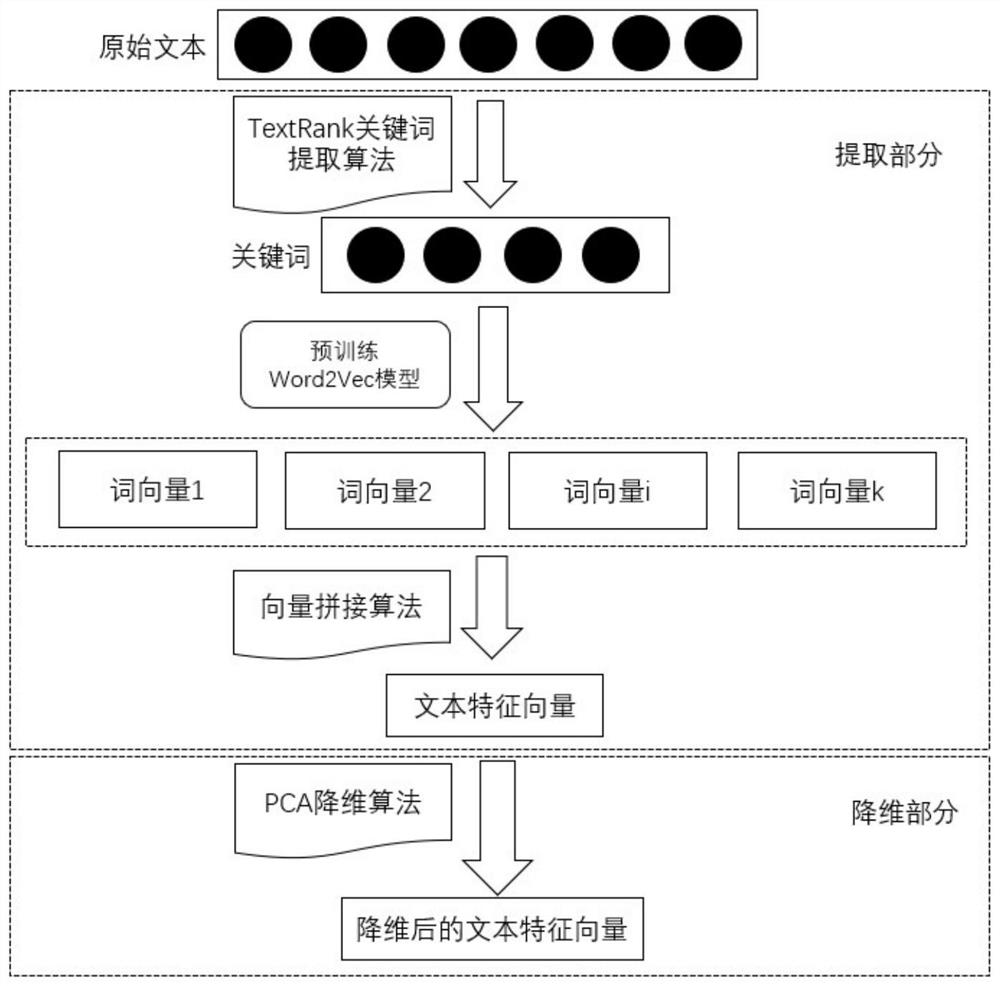
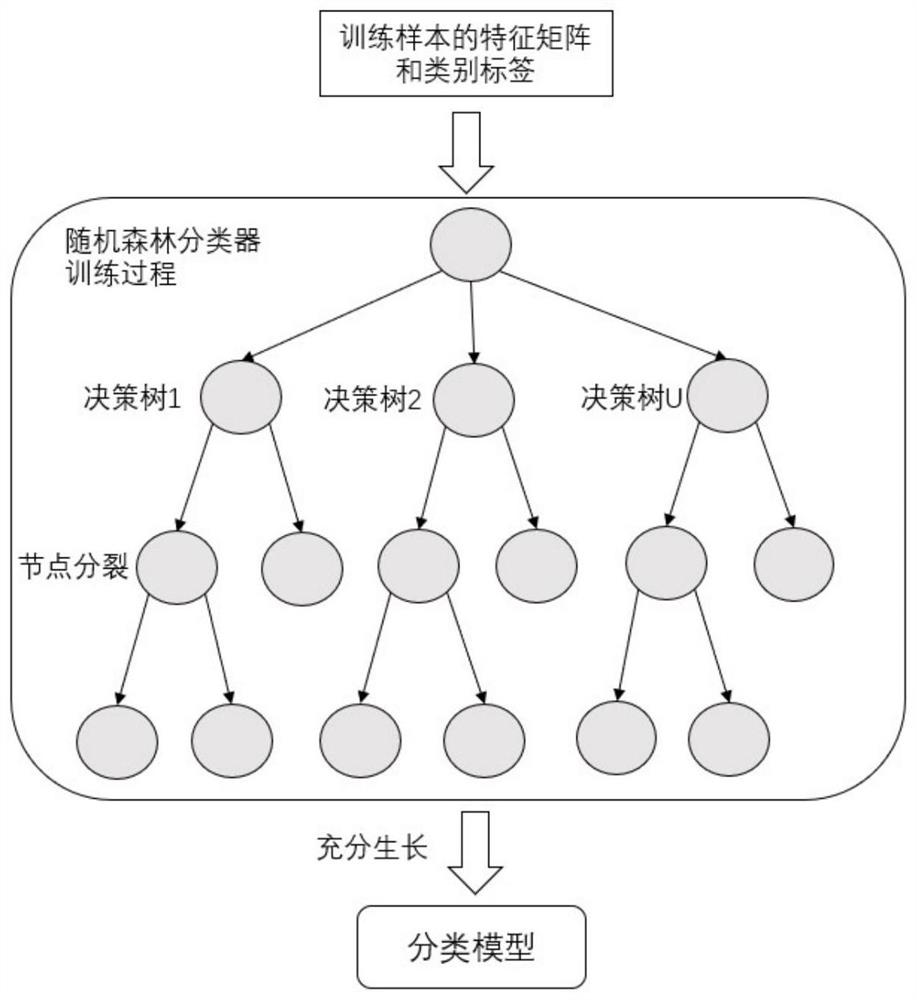
Examples
Embodiment
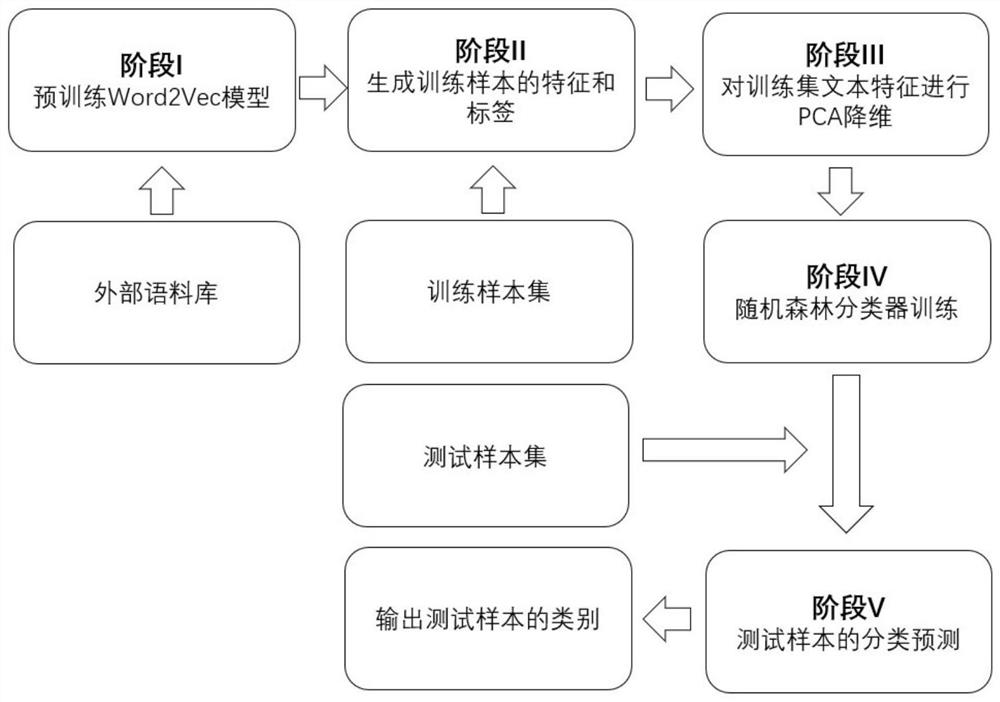
[0098] In order to verify the effectiveness of the scheme of the present invention, a kind of Chinese text classification method based on the pre-training word vector model and the random forest algorithm proposed by the present invention will be specifically exemplified below:
[0099] Input: external corpus Ω, word vector dimension q in Word2Vec, Chinese text classification training sample set of known categories Φ=[T 1 , T 2 ,...,T n ] and training label set L=[l 1 , l 2 ,...,l n ] (n is the number of training samples), the Chinese text classification test sample set of unknown category Ψ=[T 1 , T 2 ,...,T m ] (m is the number of test samples), the number U of decision trees in the random forest, the dimension e of PCA dimensionality reduction, the number r of attributes in the random attribute subset, and the number k of keywords extracted by TextRank.
[0100] Step 1: Based on the external corpus Ω, use the method described in stage I to generate a pre-trained Word...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com