Multi-auxiliary-domain information fusion cross-domain recommendation method and system
A recommendation method and auxiliary domain technology, applied in the direction of neural learning methods, digital data information retrieval, biological neural network models, etc., can solve the problems of easy loss of part of feature information, recommendation, etc., to alleviate data sparsity, performance optimization, recommendation list complete effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
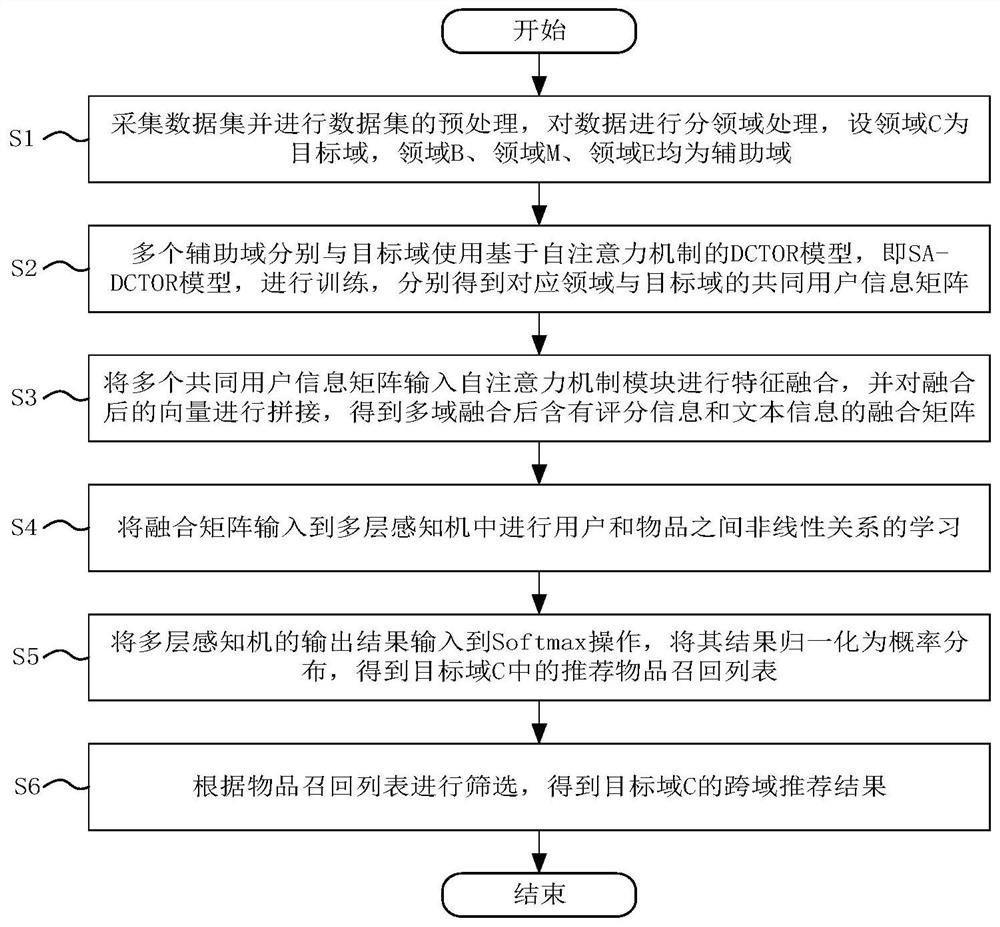
[0077] Such as figure 2 As shown, a multi-assisted domain information fusion cross-domain recommendation method includes the following steps:
[0078] S1: Collect data sets and preprocess the data sets, and process the data in different domains. Set domain C as the target domain, domain B, domain M, and domain E as auxiliary domains;
[0079] S2: Multiple auxiliary domains are trained with the target domain using the DCTOR model based on the self-attention mechanism, that is, the SA-DCTOR model, to obtain the common user information matrix of the corresponding domain and the target domain;
[0080] S3: Input multiple common user information matrices into the self-attention mechanism module for feature fusion, and splicing the fused vectors to obtain a fusion matrix containing rating information and text information after multi-domain fusion;
[0081] S4: Input the fusion matrix into the multi-layer perceptron to learn the nonlinear relationship between users and items;
[0...
Embodiment 2
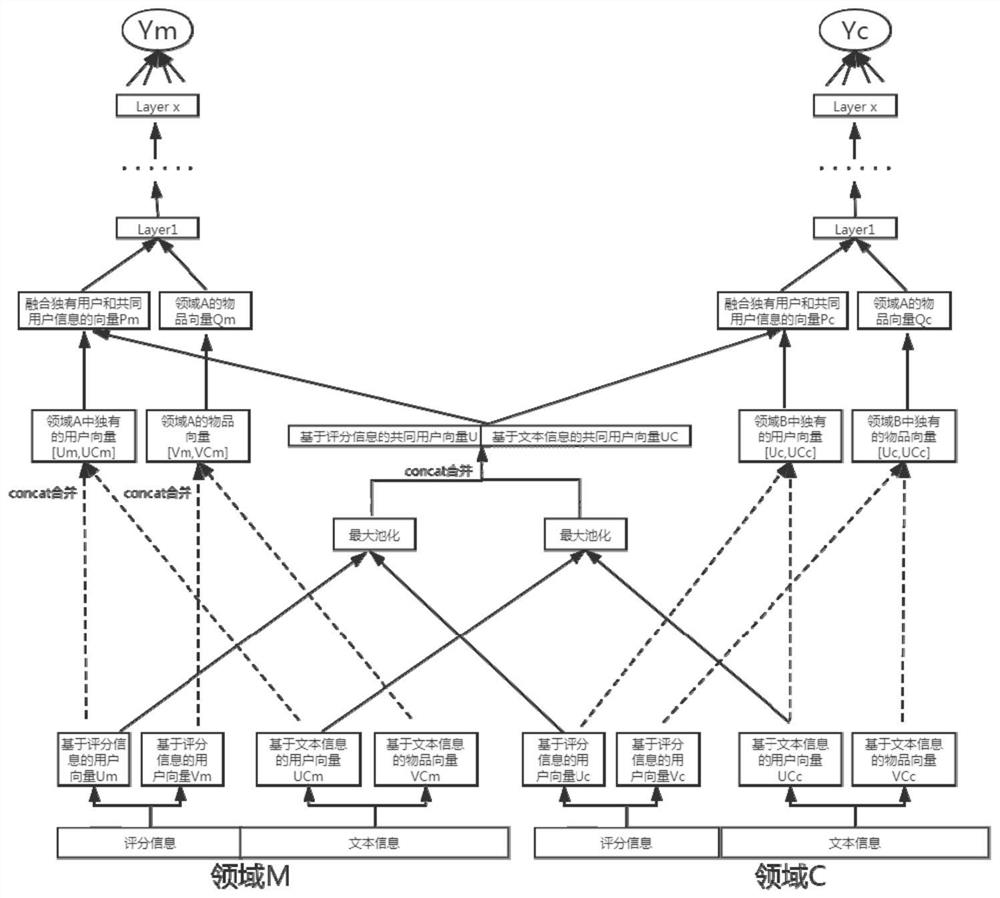
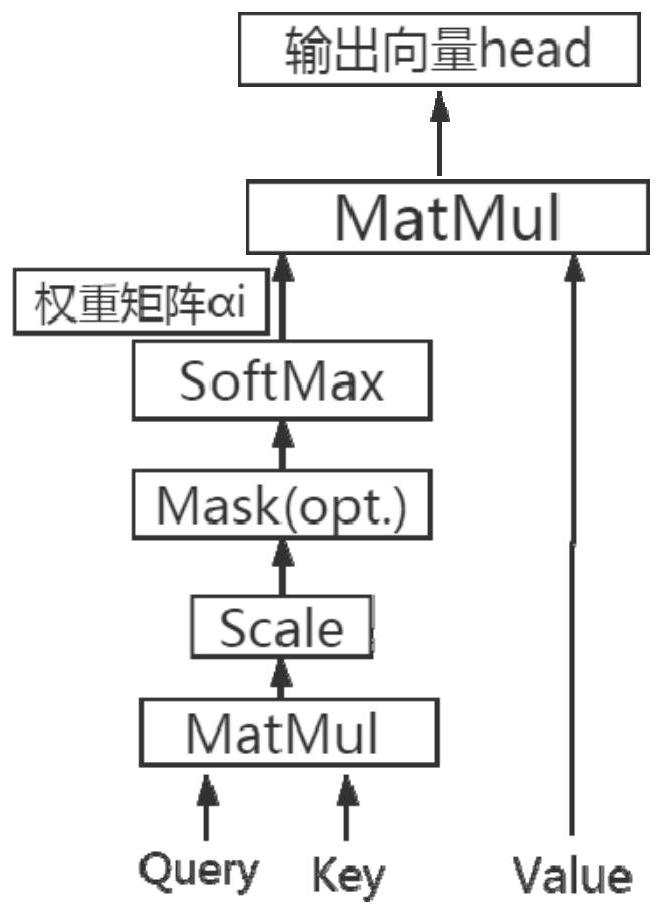
[0087] More specifically, for the common user information extraction part of a single model, the self-attention mechanism is used instead of the original pooling technology. The principle of the self-attention mechanism is as follows: image 3As shown, Query and Key are the hidden states of the decoder and encoder respectively, and Value is the Embedding vector to extract information. After Query and Key are calculated similarity by dot product, normalized, masked, and softmaxed, the corresponding weight a is generated. By multiplying the obtained weight a by the information vector Value, each input vector can be weighted according to the similarity. When using pooling technology, it will lose its generality or specificity. (Specifically, using max-pooling preserves the more prominent of the two domains, i.e. retaining specificity but losing generality. Using average-pooling simply preserves the mean of the two, i.e. retaining generality but losing specificity.)
[0088] Mor...
Embodiment 3
[0147] More specifically, based on the idea of an integrated model, the present invention proposes a multi-auxiliary domain information fusion model (hereinafter referred to as the N-SA-DCTOR model) based on a self-attention mechanism and DCTOR, such as Figure 10 shown. Assume domain C is the target domain, domain B, domain M, and domain E are auxiliary domains. The first step is to use the DCTOR model based on the self-attention mechanism (hereinafter referred to as the SA-DCTOR model) for each auxiliary domain and C respectively, and generate the common user information vector D of the main domain and each auxiliary domain respectively. mc 、D bc and D ec . In the second step, multiple common user vectors are input to a layer of self-attention mechanism Layer for weighted fusion, and the fused vectors are concat spliced to obtain a multi-domain fusion vector U. The third step uses a fully connected multi-layer perceptron (MLP) to learn the non-linear relationship bet...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More