

Wheat powdery mildew spore segmentation method for small sample image data set
A technology for wheat powdery mildew and image data sets, applied in image data processing, image analysis, image enhancement, etc., can solve the problems of low segmentation accuracy, empty segmentation results, and small targets, so as to enhance the extraction ability and reduce excessive The effect of learning, effective and accurate segmentation
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

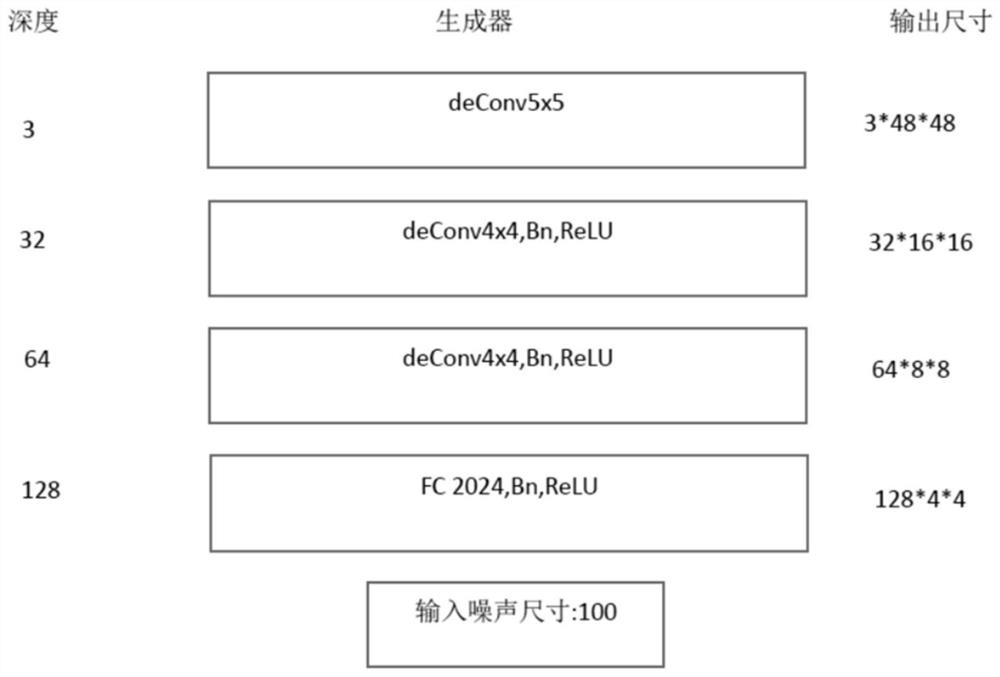
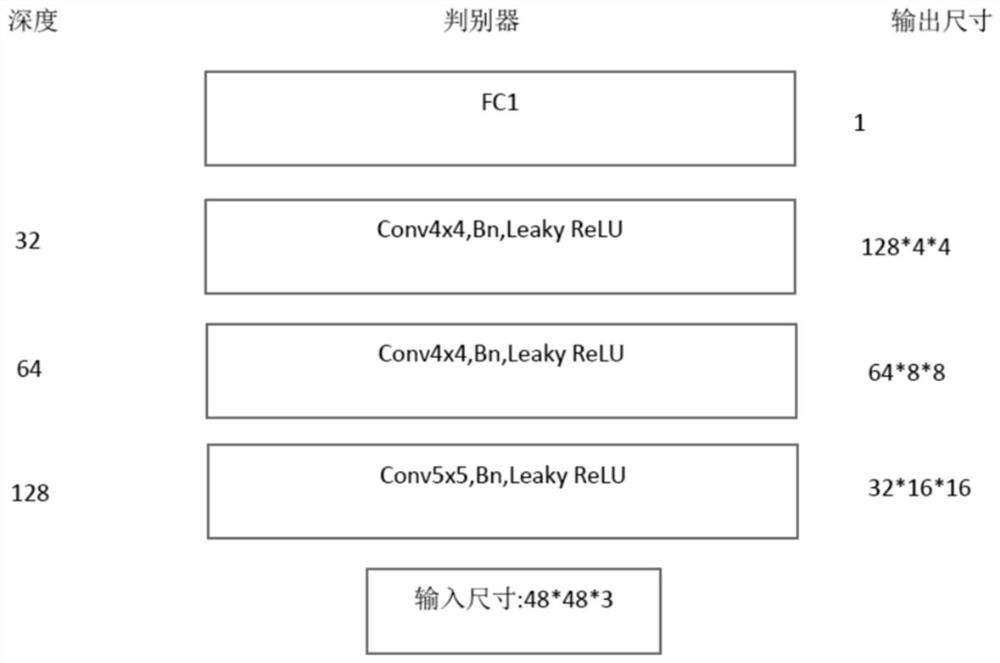
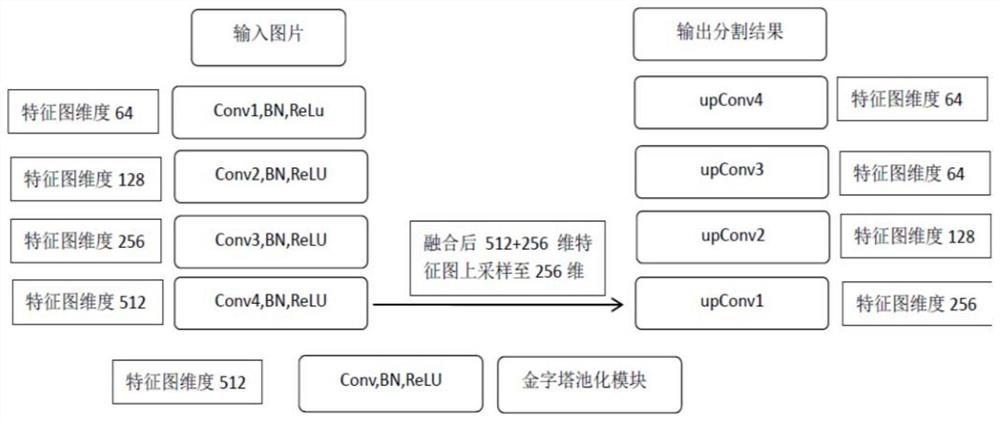
Examples
Embodiment Construction
[0065] The present invention will be described in further detail below in conjunction with specific embodiments and with reference to the accompanying drawings.
[0066] The invention provides a method for segmenting wheat powdery mildew of a small sample image data set, which specifically includes the following steps:
[0067] The used hardware equipment of the present invention has 1 PC machine, 1 1050ti graphics card;
[0068] Step 1. Collect the wheat powdery mildew spore image data set, and clean the data in the data set, and screen the image data that can obtain effective information (including target spores).
[0069] Step 2. After labeling the wheat powdery mildew spore data set with a mask, it is randomly divided into a training set and a test set, and the image and mask are rotated at the same time, randomly cropped, random Gaussian noise is added, brightness adjustment and contrast enhancement are obtained, and the first A batch of augmented data.
[0070] Step 2....
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More