PET image reconstruction algorithm for improving spatial resolution uniformity of PET system based on deep learning
An image reconstruction and deep learning technology, applied in the field of biomedical image analysis, to achieve the effect of improving uniformity and solving uneven spatial resolution
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0028] In order to describe the present invention more specifically, the technical solutions of the present invention will be described in detail below in conjunction with the accompanying drawings and specific embodiments.
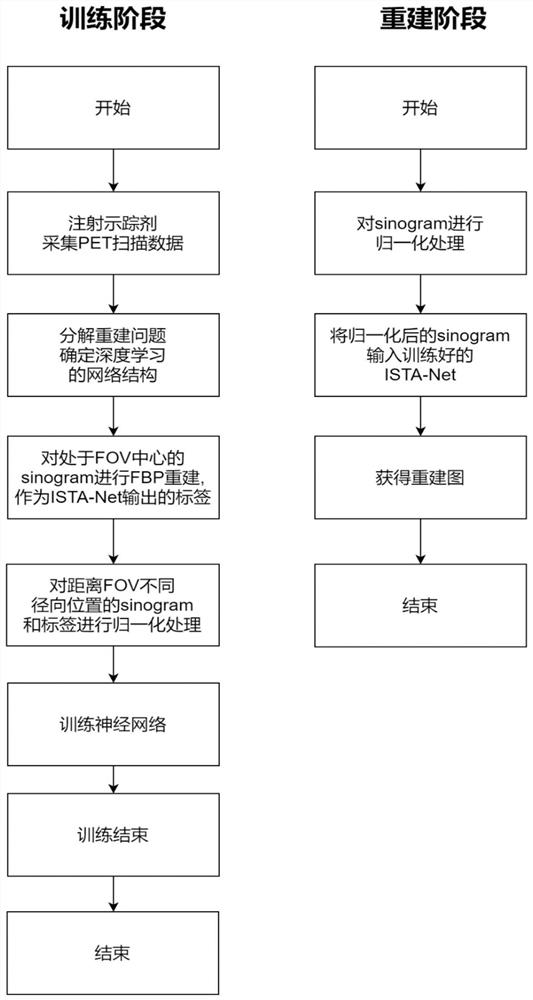
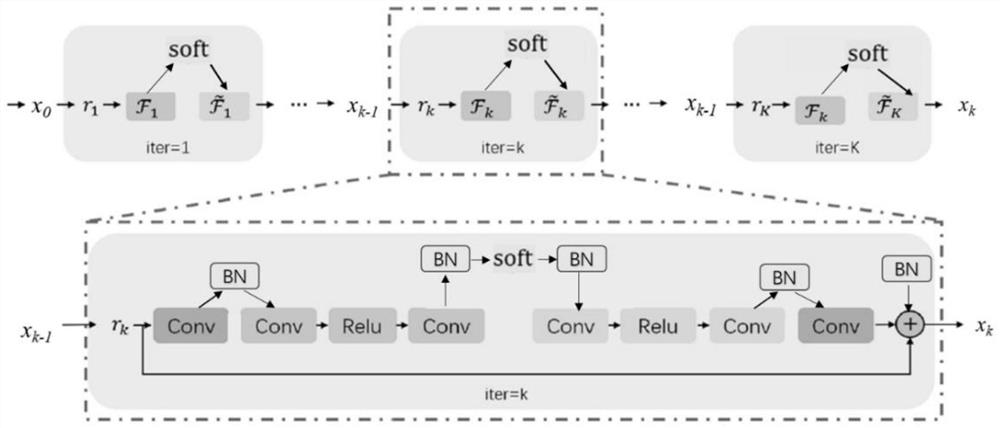
[0029] Such as figure 1As shown, the deep learning of the present invention improves the image reconstruction algorithm of the spatial resolution uniformity of the PET system, which specifically includes the following steps:
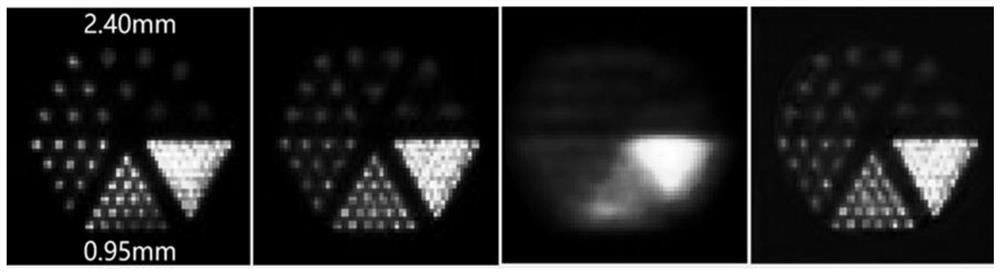
[0030] (1) Collect data. The phantom is injected with a PET radioactive tracer, and the phantom is placed at different positions in the radial distance from the center of field of view (FOV) of the PET device for scanning, and the coincident photons are detected and counted to obtain the results of the phantom at different radial positions. The corresponding original projection data matrix Y at i i .
[0031] (2) According to the principle of PET imaging, the measurement equation model is established:
[0032] Y=GX+R+S
[0033]...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



