Auxiliary judgment method based on deep learning and virtual reality
A virtual reality and deep learning technology, applied in neural learning methods, input/output of user/computer interaction, speech analysis, etc. The effect of meeting individual needs
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0031] In order to make the purpose, technical solutions and advantages of the embodiments of the present invention clearer, the technical solutions in the embodiments of the present invention will be clearly and completely described below in conjunction with the drawings in the embodiments of the present invention. Obviously, the described embodiments It is a part of the embodiments of the present invention, but not all of them. Based on the embodiments of the present invention, all other embodiments obtained by those of ordinary skill in the art without creative work belong to the protection of the present invention. scope.
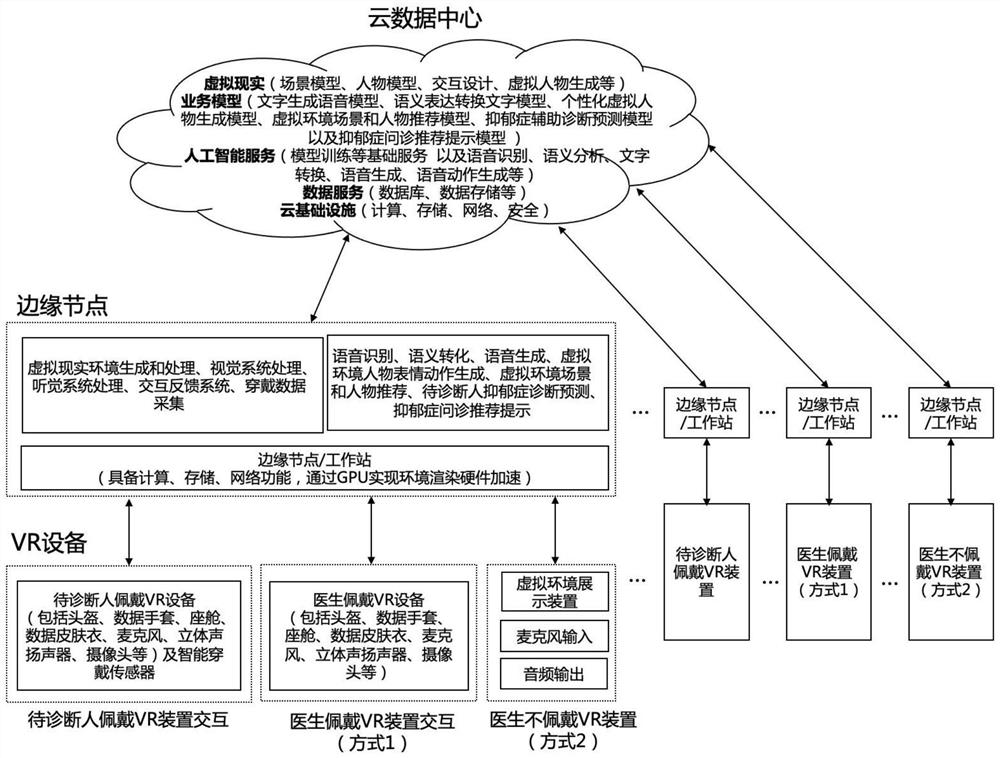
[0032] Such as figure 1 As shown in , build a virtual reality environment, select virtual dialogue characters and scenes based on the preferences and conditions of the testee, and realize interaction with the virtual reality environment and data collection by wearing a virtual reality VR device and smart wearable sensors. Using the model from the cloud...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More