

Parallel processing of continuous queries on data streams
a data stream and parallel processing technology, applied in the field of data stream processing and event management, can solve the problems of inability to scale out with respect to the incoming stream volume, system capacity limitation, and inability to scale ou
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
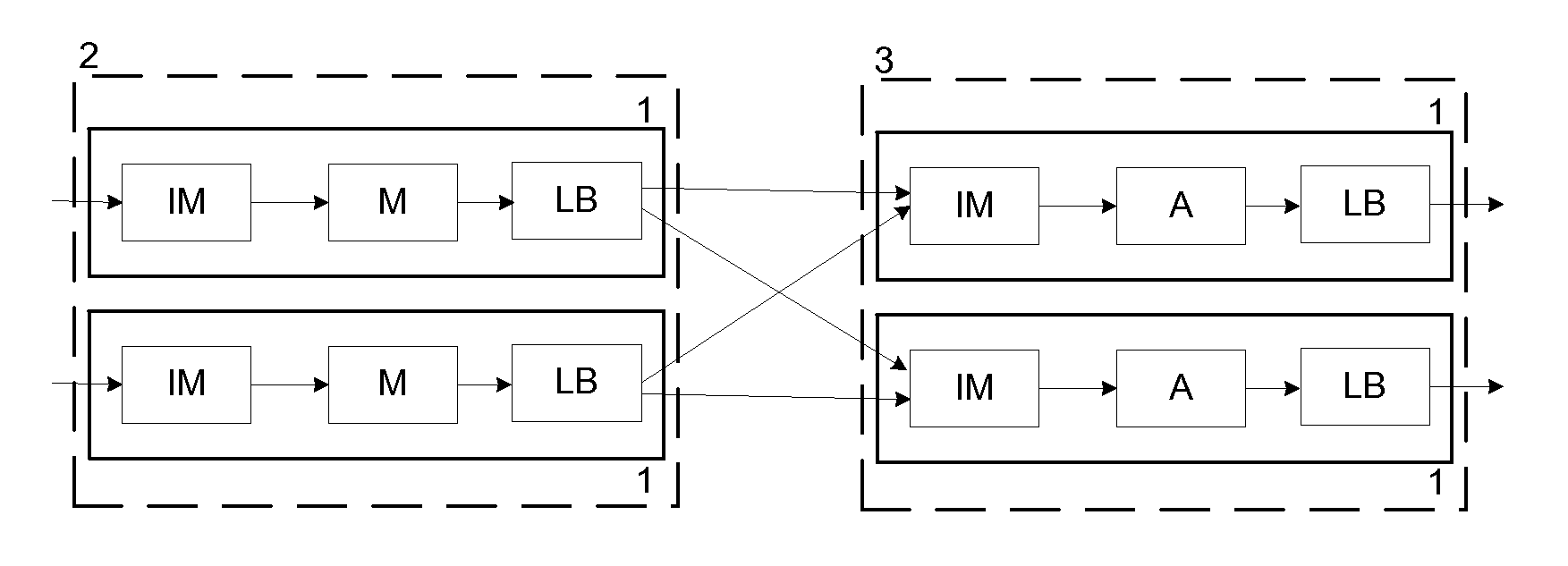
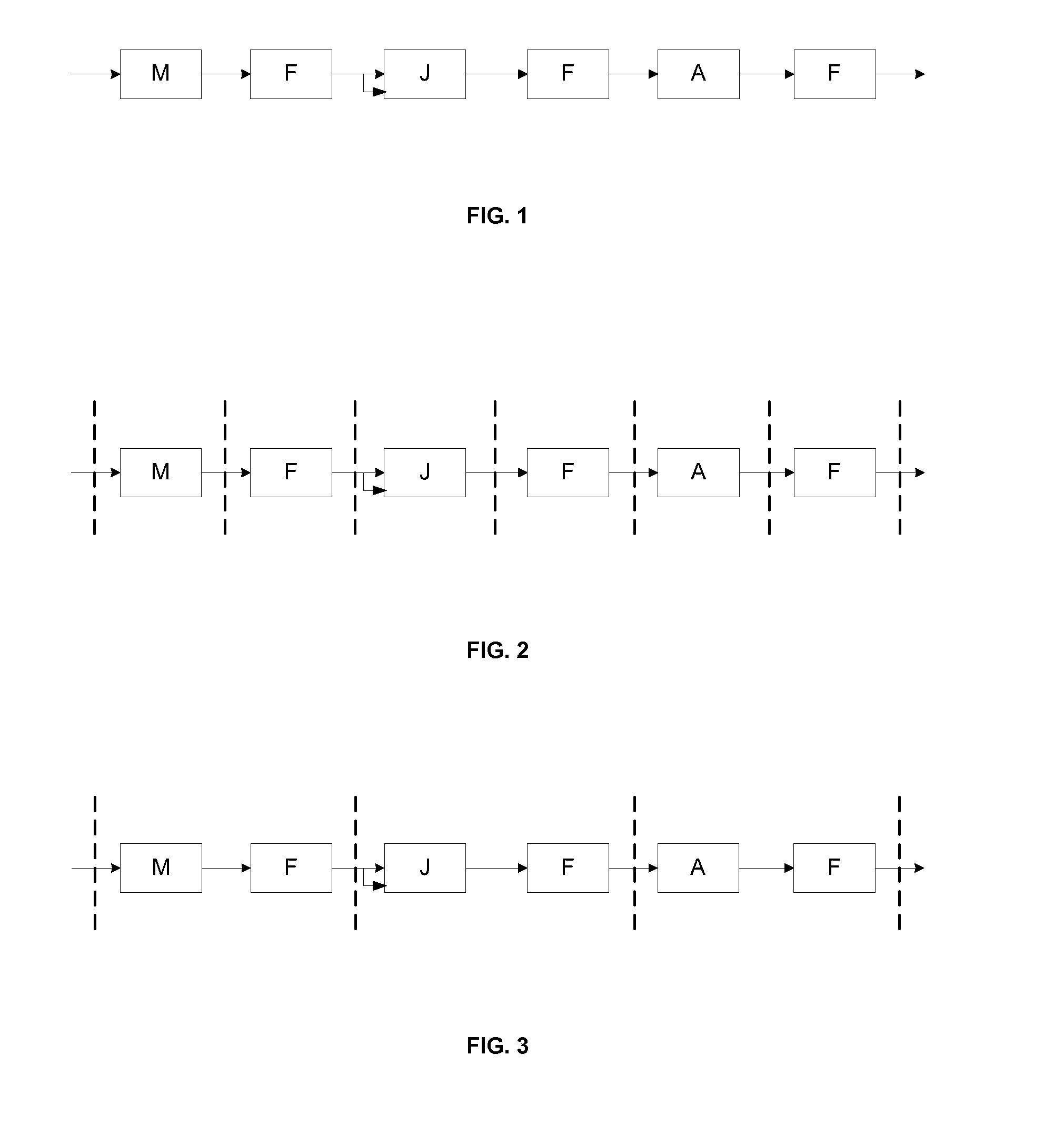
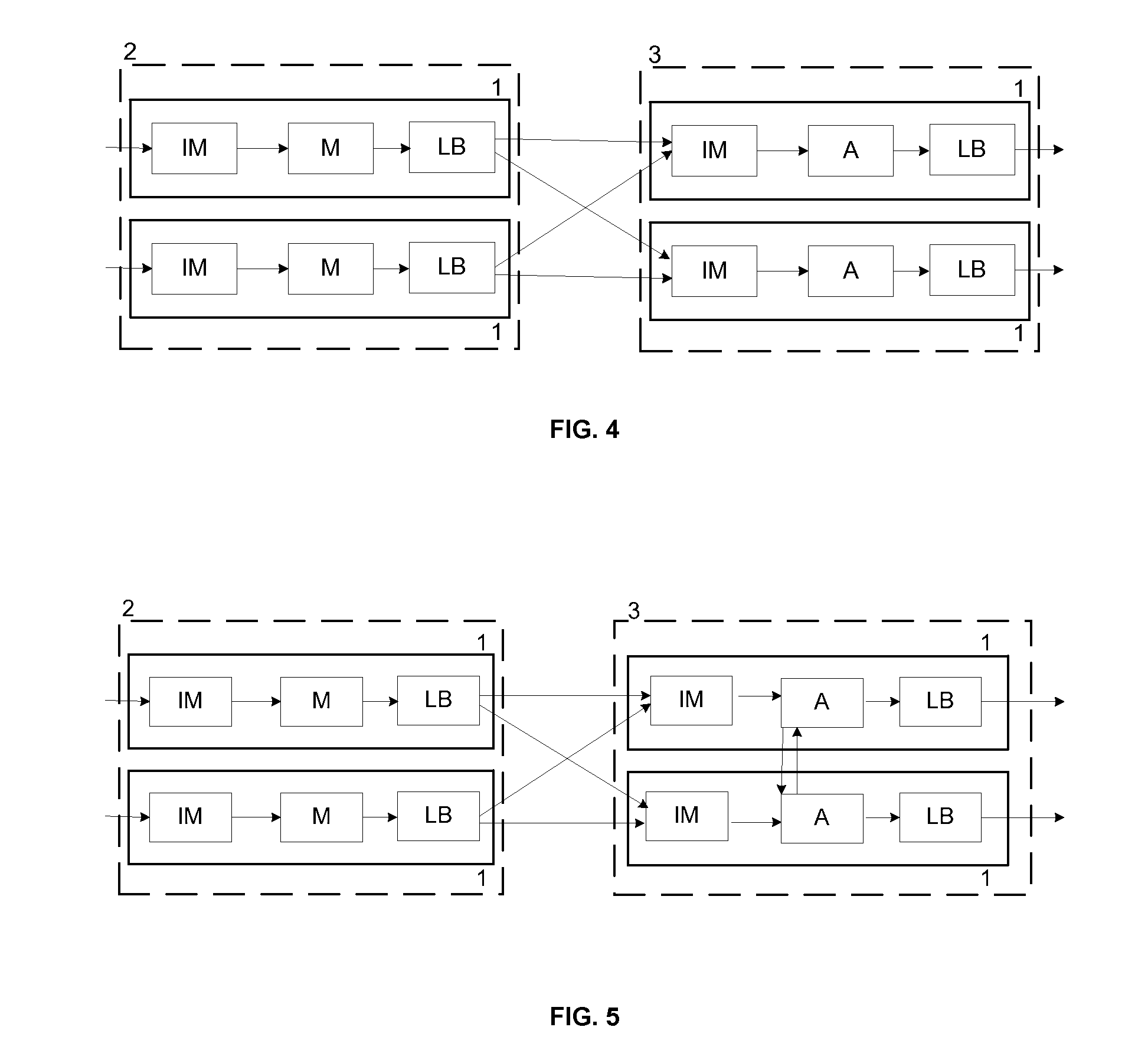
[0052]FIG. 1 shows a query with Map (M), Filter (F), Join (J) and Aggregate (A) operators. In this query incoming tuples enter through the left operator. The map operator transforms a tuple with the associated transformation function. The filtering operator applies a predicate to the tuple, if it is satisfied, then the tuple is forwarded to the next operator, otherwise, it is discarded. The output of the filter operator is connected with the two inputs of the join operator. That is, each tuple produced by the filter operator is sent to each of the two inputs of the join operator performing a self-join. The join operator applies a predicate to all pairs kept in the two sliding windows (associated to the respective input streams). Each pair that satisfies the predicate is concatenated and generated as an output tuple. The next operator is an aggregate. It aggregates the tuples according a given function or a group-by clause. A tuple is generated periodically with the aggregated value ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More