

Hardware acceleration implementation architecture for backward training of convolutional neural network based on FPGA
A convolutional neural network and convolutional layer technology, applied in the field of deep learning, can solve problems such as insufficient storage bandwidth, and achieve the effect of significant acceleration effect, regular structure, and improved storage bandwidth.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
example 1
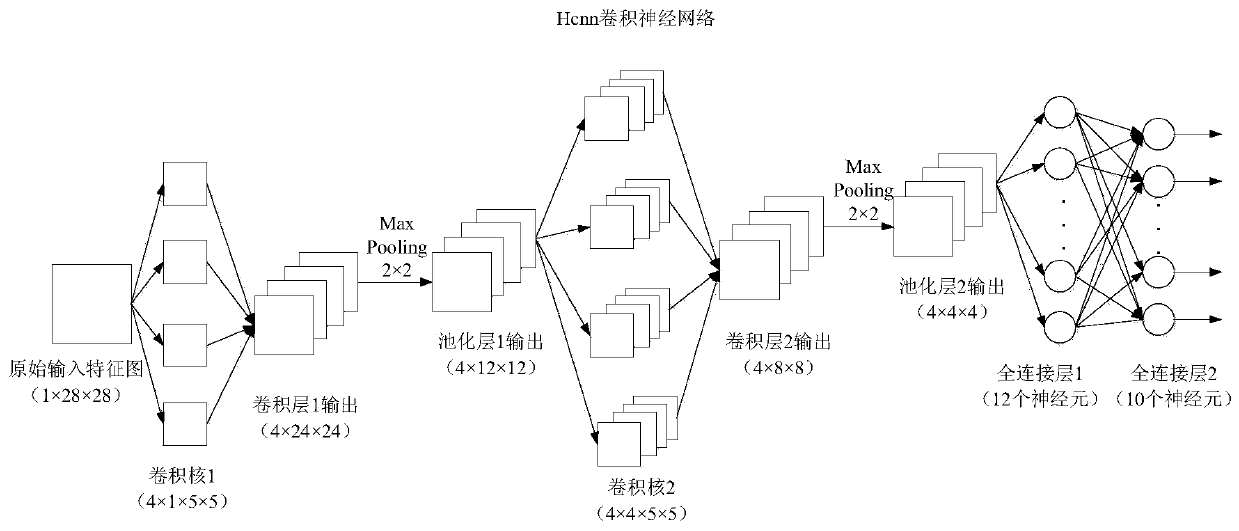
[0068] 1. Example 1: FPGA simulation and implementation of convolutional neural network Hcnn backward training process
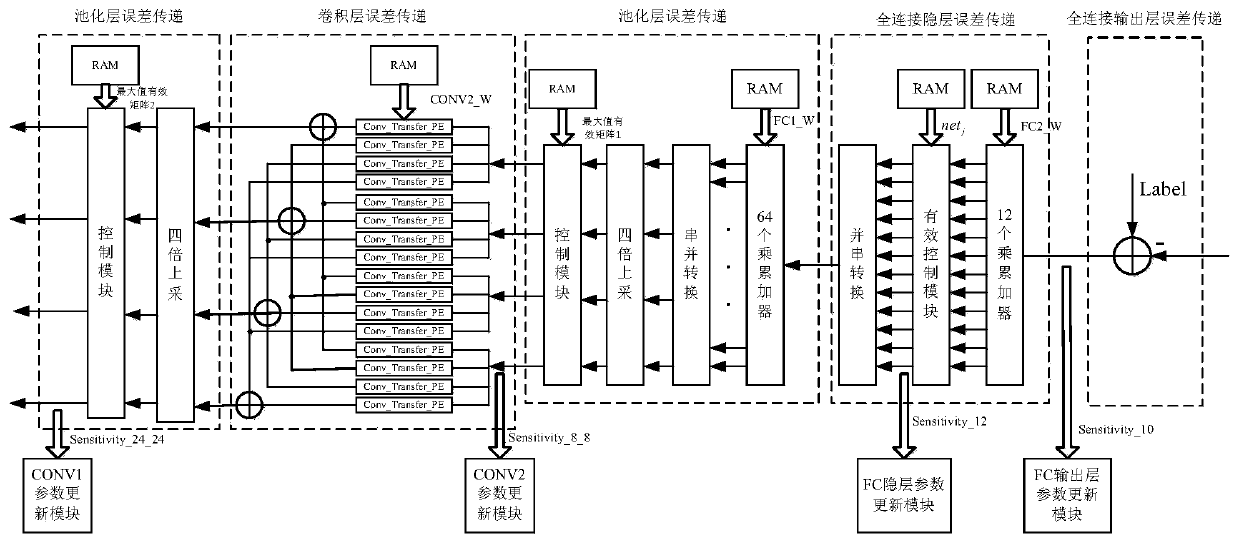
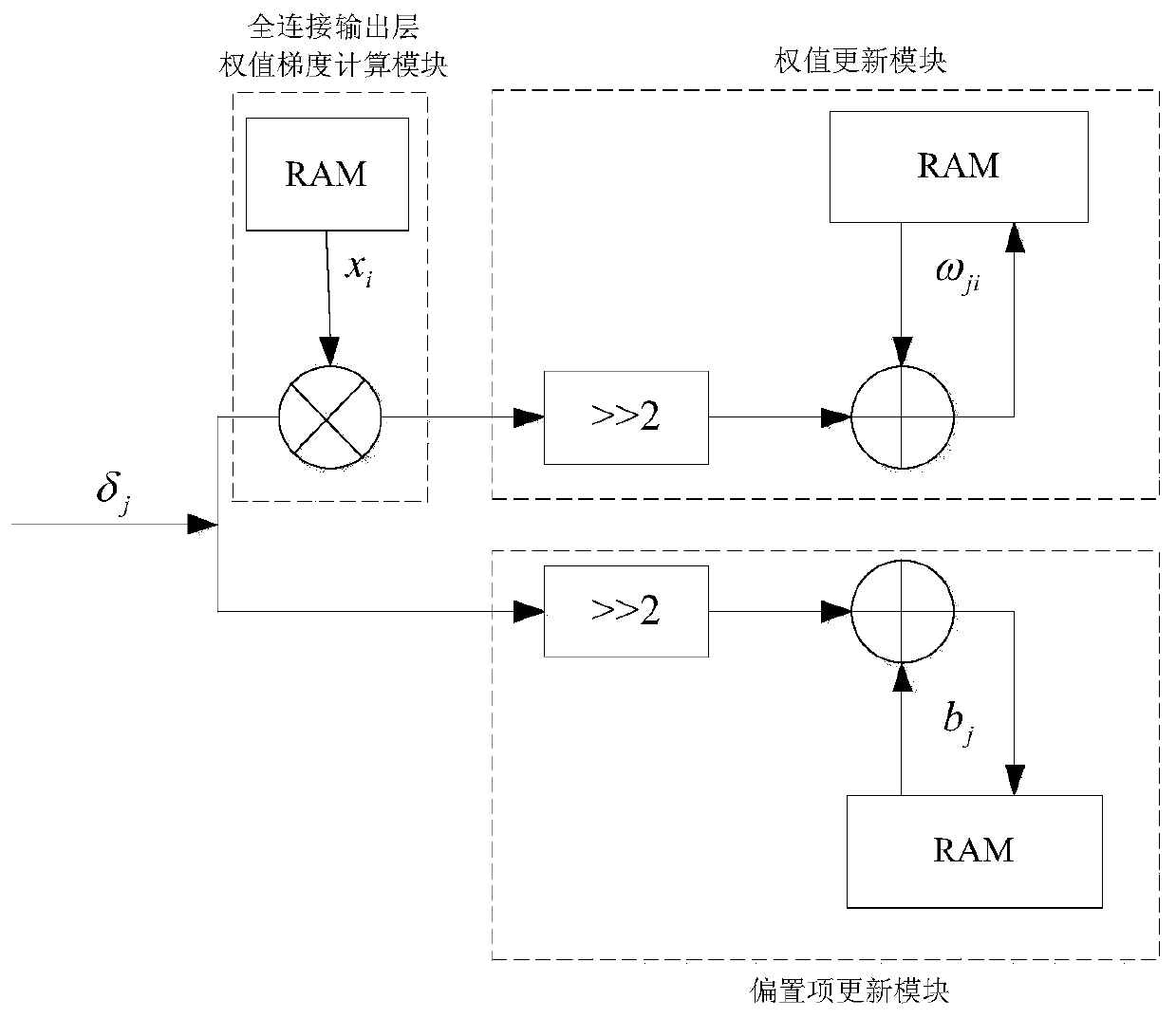
[0069] The simulation platform used in Example 1 is Matlab R2017b, ISE 14.7 and Modelsim 10.1a, and the implemented architecture is as follows figure 2 shown. First in Matlab R2017b for figure 2 The Hcnn convolutional neural network is verified by matlab fixed-point simulation, and the accuracy of the model can reach 95.34%. Then in ISE 14.7 and Modelsim 10.1a, the simulation verification and implementation of the hardware architecture are carried out. In matlab fixed-point simulation and FPGA implementation, most parameters and intermediate register variables adopt the fixed-point method of fi(1,18,12), that is, 1 bit of sign, 5 bits of integer, and 12 bits of decimal.
[0070] The Modelsim simulation results of the forward prediction process of the Hcnn convolutional neural network in Example 1 are as follows Figure 9 shown. It can be seen from the...
example 2
[0073] The simulation platform used in Example 2 is ISE 14.7 and PyCharm. first by Figure 9 It can be seen that the data processing time of the model is 821 clks (excluding the time to read input data), so at a clock frequency of 200M, the time used is 4105ns.
[0074] Then, on the simulation platform PyCharm, use the CPU model of Intel E3-1230V2@3.30GHz and the GPU model of TitanX to complete the calculation of the structure in Example 1, and the calculation time of the CPU and GPU to process a sample is 7330ns and 405ns.
[0075] The speed and power consumption performance analysis comparison diagram of the structure of Example 1 implemented in FPGA, CPU, and GPU is as follows Figure 11 shown. As can be seen from the figure, in terms of speed, the convolutional neural network FPGA implementation architecture of the present invention has an improvement of about three times compared with the CPU; and there is still a certain gap compared with the GPU, which is limited by ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More